



AAVE Price Prediction 2027: $70-$2,175 Forecast Analysis
%201.svg)
%201.svg)


AAVE Price Prediction 2027: Market Analysis and Scenario-Based Forecasts
Market Context for Aave Price Prediction: The Case for 2027
DeFi protocols are maturing beyond early ponzi dynamics toward sustainable revenue models. Aave operates in this evolving landscape where real yield and proven product-market fit increasingly drive valuations rather than speculation alone. Growing regulatory pressure on centralized platforms creates tailwinds for decentralized alternatives—factors that inform our comprehensive AAVE price prediction framework.
The scenario bands below reflect how AAVE price predictions might perform across different total crypto market cap environments. Each tier represents a distinct liquidity regime, from bear conditions with muted DeFi activity to moon scenarios where decentralized infrastructure captures significant value from traditional finance.

Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to Read This AAVE Price Prediction
Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline: Token Metrics TM Grade is 72, Buy, and the trading signal is bullish, indicating solid protocol fundamentals, healthy developer activity, and positive near-term momentum. Concise twelve-month numeric view, Token Metrics price prediction scenarios cluster roughly between $70 and $320, with a base case near $150, reflecting continued growth in lending TVL, fee revenue capture by the protocol, and modest macro tailwinds.
Live details: Aave Token Details
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Key Takeaways
- Scenario driven, outcomes hinge on total crypto market cap, higher liquidity and adoption lift the bands.
- Fundamentals: Fundamental Grade 75.51% (Community 77%, Tokenomics 100%, Exchange 100%, VC 49%, DeFi Scanner 70%).
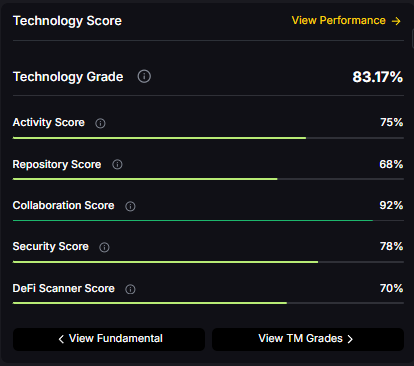
- Technology: Technology Grade 83.17% (Activity 75%, Repository 68%, Collaboration 92%, Security 78%, DeFi Scanner 70%).
- TM Agent gist: scenarios cluster between $70 and $320 with base near $150, assuming steady lending TVL growth and neutral macro conditions.
- Education only, not financial advice.
AAVE Price Prediction Scenario Analysis
Our Token Metrics price prediction framework spans four market cap tiers, each representing different levels of crypto market maturity and liquidity:
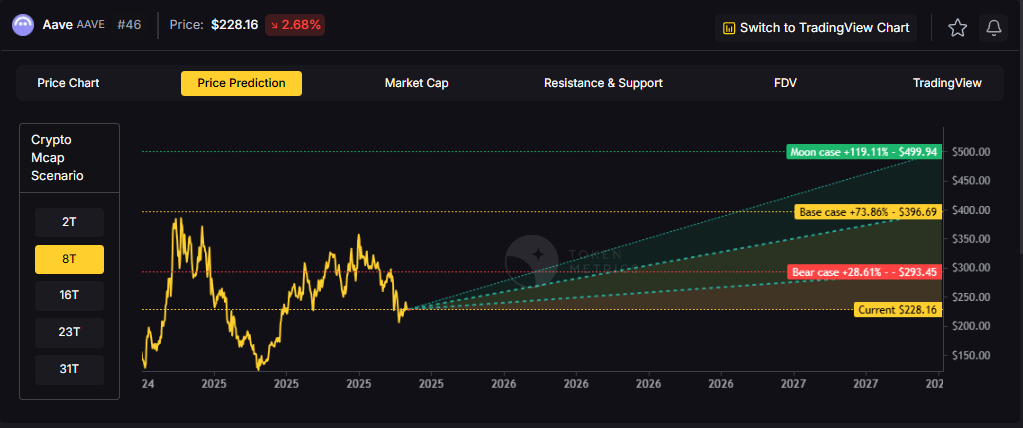
8T Market Cap - AAVE Price Prediction:
At an 8 trillion dollar total crypto market cap, AAVE projects to $293.45 in bear conditions, $396.69 in the base case, and $499.94 in bullish scenarios.
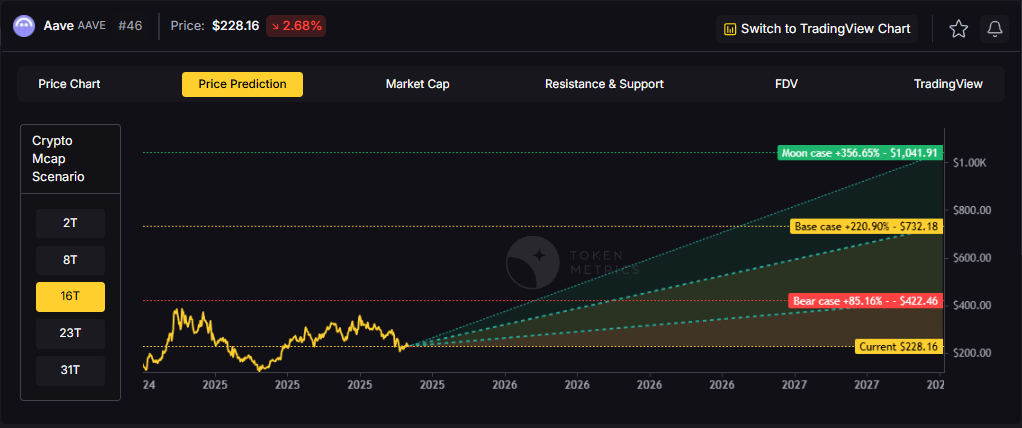
16T Market Cap - AAVE Price Prediction:
Doubling the market to 16 trillion expands the price prediction range to $427.46 (bear), $732.18 (base), and $1,041.91 (moon).
23T Market Cap - AAVE Price Prediction:
At 23 trillion, the price prediction scenarios show $551.46, $1,007.67, and $1,583.86 respectively.

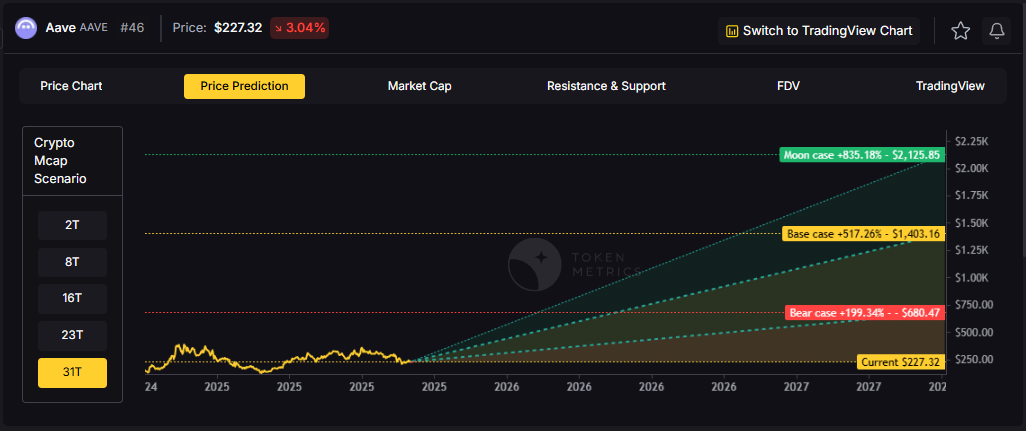
31T Market Cap - AAVE Price Prediction:
In the maximum liquidity scenario of 31 trillion, AAVE price predictions could reach $680.47 (bear), $1,403.16 (base), or $2,175.85 (moon).
Each tier assumes progressively stronger market conditions, with the base case price prediction reflecting steady growth and the moon case requiring sustained bull market dynamics.
Why Consider the Indices with Top-100 Exposure
Aave represents one opportunity among hundreds in crypto markets. Token Metrics Indices bundle AAVE with top one hundred assets for systematic exposure to the strongest projects. Single tokens face idiosyncratic risks that diversified baskets mitigate.
Historical index performance demonstrates the value of systematic diversification versus concentrated positions.
What Is Aave?
Aave is a decentralized lending protocol that operates across multiple EVM-compatible chains including Ethereum, Polygon, Arbitrum, and Optimism. The network enables users to supply crypto assets as collateral and borrow against them in an over-collateralized manner, with interest rates dynamically adjusted based on utilization.
The AAVE token serves as both a governance asset and a backstop for the protocol through the Safety Module, where stakers earn rewards in exchange for assuming shortfall risk. Primary utilities include voting on protocol upgrades, fee switches, collateral parameters, and new market deployments.
Token Metrics AI Analysis
Token Metrics AI provides comprehensive context on Aave's positioning and challenges.
Vision: Aave aims to create an open, accessible, and non-custodial financial system where users have full control over their assets. Its vision centers on decentralizing credit markets and enabling seamless, trustless lending and borrowing across blockchain networks.
Problem: Traditional financial systems often exclude users due to geographic, economic, or institutional barriers. Even in crypto, accessing credit or earning yield on idle assets can be complex, slow, or require centralized intermediaries. Aave addresses the need for transparent, permissionless, and efficient lending and borrowing markets in the digital asset space.
Solution: Aave uses a decentralized protocol where users supply assets to liquidity pools and earn interest, while borrowers can draw from these pools by posting collateral. It supports features like variable and stable interest rates, flash loans, and cross-chain functionality through its Layer 2 and multi-chain deployments. The AAVE token is used for governance and as a safety mechanism via its staking program (Safety Module).
Market Analysis: Aave is a leading player in the DeFi lending sector, often compared with protocols like Compound and Maker. It benefits from strong brand recognition, a mature codebase, and ongoing innovation such as Aave Arc for institutional pools and cross-chain expansion. Adoption is driven by liquidity, developer activity, and integration with other DeFi platforms. Key risks include competition from newer lending protocols, regulatory scrutiny on DeFi, and smart contract risks. As a top DeFi project, Aave's performance reflects broader trends in decentralized finance, including yield demand, network security, and user trust. Its multi-chain strategy helps maintain relevance amid shifting ecosystem dynamics.
Fundamental and Technology Snapshot from Token Metrics
Fundamental Grade: 75.51% (Community 77%, Tokenomics 100%, Exchange 100%, VC 49%, DeFi Scanner 70%).

Technology Grade: 83.17% (Activity 75%, Repository 68%, Collaboration 92%, Security 78%, DeFi Scanner 70%).
Catalysts That Skew AAVE Price Predictions Bullish
- Institutional and retail access expands with ETFs, listings, and integrations
- Macro tailwinds from lower real rates and improving liquidity
- Product or roadmap milestones such as upgrades, scaling, or partnerships
Risks That Skew AAVE Price Predictions Bearish
- Macro risk-off from tightening or liquidity shocks
- Regulatory actions or infrastructure outages
- Concentration or competitive displacement in lending
AAVE Price Prediction FAQs
Can AAVE reach $1,000?
Yes. Based on our price prediction scenarios, AAVE could reach $1,007.67 in the 23T base case and $1,041.91 in the 16T moon case. Not financial advice.
Can AAVE 10x from current levels?
At current price of $228.16, a 10x would reach $2,281.60. This falls within the 31T moon case price prediction at $2,175.85 (only slightly below), and would require extreme liquidity expansion. Not financial advice.
What price could AAVE reach in the moon case?
Our moon case price predictions range from $499.94 at 8T to $2,175.85 at 31T. These scenarios assume maximum liquidity expansion and strong Aave adoption. Not financial advice.
What is the AAVE price prediction for 2027?
Our comprehensive 2027 price prediction framework suggests AAVE could trade between $293.45 and $2,175.85, depending on market conditions and total crypto market capitalization. The base case scenario clusters around $396.69 to $1,403.16 across different market cap environments. Not financial advice.
Is AAVE a good investment based on price predictions?
AAVE shows strong fundamentals (75.51% grade) and technology scores (83.17% grade), with bullish trading signals. However, all price predictions involve uncertainty and risk. Always conduct your own research and consult financial advisors before investing. Not financial advice.

Next Steps
Track live grades and signals: Token Details
Want exposure? Buy AAVE on MEXC
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
Why Use Token Metrics?
- AI-driven crypto and DeFi grades for risk management and alpha discovery.
- Quantitative, on-chain signals and robust scenario modeling for tokens like AAVE.
- Access in-depth research reports, analyst perspectives, auto-grades, and portfolio tools from Token Metrics.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.