



Best Remittance Companies Using Crypto Rails (2025)
%201.svg)
%201.svg)


Why Crypto-Powered Remittances Matter in September 2025
Cross-border money transfers are still too expensive and slow for millions of workers and families. Crypto remittance companies are changing that by using stablecoins, Lightning, and on-chain FX to compress costs and settlement time from days to minutes. In one line: crypto remittances use blockchain rails (e.g., Lightning or stablecoins like USDC) to move value globally, then convert to local money at the edge. This guide highlights the 10 best providers by liquidity, security, corridor coverage, costs, and UX—so you can pick the right fit whether you’re sending U.S.→MX/PH remittances, settling B2B payouts in Africa, or building compliant payout flows. Secondary topics we cover include stablecoin remittances, Lightning transfers, and cross-border crypto payments—with clear pros/cons and regional caveats.
How We Picked (Methodology & Scoring)
- Liquidity (30%) – Depth/scale of flows, corridor breadth, and on/off-ramps.
- Security (25%) – Licenses, audits, proof-of-reserves or equivalent disclosures, custody posture.
- Coverage (15%) – Supported corridors, payout methods (bank, e-wallet, cash pickup, mobile money).
- Costs (15%) – FX + transfer fees, spread transparency, typical network costs.
- UX (10%) – Speed, reliability, mobile/web experience, integration options (APIs).
- Support (5%) – Human support, docs, business SLAs.
Data sources prioritized official sites, docs/security pages, and disclosures; third-party market datasets used only for cross-checks. Last updated September 2025.
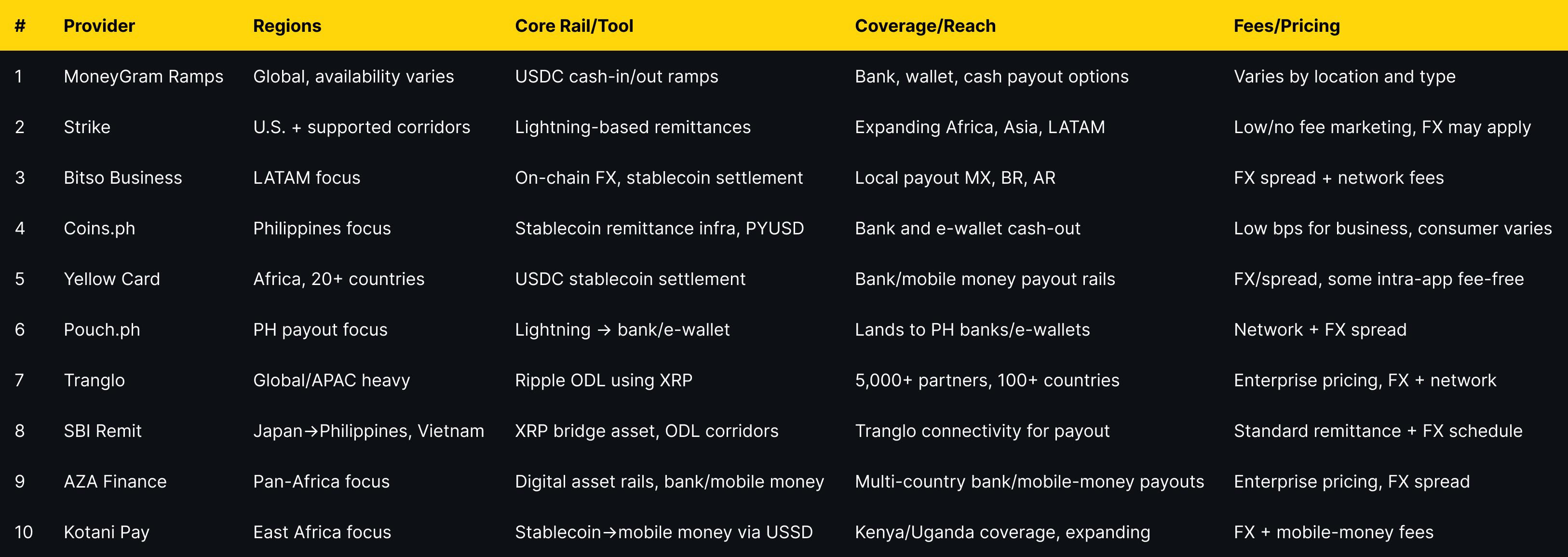
Top 10 Remittance Companies Using Crypto Rails in September 2025
1. MoneyGram Ramps — Best for cash ↔ USDC access worldwide
Why Use It: MoneyGram connects cash and bank rails to on-chain USDC via its Ramps network and global locations, enabling senders/receivers to move between fiat and stablecoins quickly—useful where banking access is limited. The developer docs support flexible flows and partner integrations for compliant cash-in/cash-out. anchors.stellar.org
Best For: Cash-to-crypto access • Stablecoin remittances with cash pickup • Fintechs needing global cash-out
Notable Features:
- USDC cash-in/out network with global footprint anchors.stellar.org
- Developer docs + SDKs for partners
- Bank, wallet, and cash payout options
Consider If: You need cash pickup endpoints or mixed cash/crypto flows.
Alternatives: Coins.ph, Yellow Card
Regions: Global (availability varies by country).
Fees Notes: Vary by location and payout type; check local schedule.
2. Strike — Best for Lightning-powered U.S.→Global transfers

Why Use It: Strike uses the Bitcoin Lightning Network under the hood to move value, combining a fiat UX with bitcoin rails for speed and cost efficiency across corridors (e.g., U.S. to Africa/Asia/LatAm). Their “Send Globally” program highlights expanding coverage and low-friction transfers. Strike
Best For: U.S.-origin senders • Freelancers/SMBs paying abroad • Lightning enthusiasts
Notable Features:
- Lightning-based remittances behind a simple fiat UI Strike
- Expanding corridor coverage (Africa, Asia, LATAM) Trusted Crypto Wallet
- Mobile app + business features
Consider If: Recipient banks/e-wallets need predictable FX; confirm corridor availability.
Alternatives: Pouch.ph, Bitnob
Regions: U.S. + supported corridors.
Fees Notes: Strike markets low/no transfer fees; FX/spread may apply by corridor. Trusted Crypto Wallet
3. Bitso Business — Best for LATAM B2B remittances & on-chain FX

Why Use It: Bitso powers large USD↔MXN/BRL flows, combining stablecoin rails with local payout, and publicly reports multi-billion USD remittance throughput. Their business stack (APIs, on-chain FX) targets enterprises moving funds into Mexico, Brazil, and Argentina with speed and deep local liquidity. Bitso+1
Best For: Marketplaces • Payroll/treasury teams • LATAM fintechs
Notable Features:
- On-chain FX & stablecoin settlement via Bitso Business business.bitso.com
- Deep U.S.→Mexico remittance liquidity; disclosed volumes Bitso
- Local payout rails across MX/BR/AR
Consider If: You need compliance reviews and B2B contracts.
Alternatives: AZA Finance, Tranglo
Regions: LATAM focus.
Fees Notes: FX spread + network fees; enterprise pricing via API.
4. Coins.ph — Best for Philippines inbound remittances & stablecoin flows
Why Use It: Coins.ph is a leading PH exchange/e-wallet with crypto rails, Western Union integrations, and recent initiatives using stablecoins (including PYUSD) and always-on corridors (e.g., HK↔PH). It positions blockchain/stablecoins to lower costs and improve speed for business and retail remittances. Trusted Crypto Wallet+2Trusted Crypto Wallet+2
Best For: PH recipients • Businesses seeking PH payout • Retail cash-out to banks/e-wallets
Notable Features:
- Stablecoin-based remittance infrastructure; speed & cost focus Trusted Crypto Wallet
- PYUSD partnership; remittance use case Trusted Crypto Wallet
- Integrations & promos with Western Union (historical) Trusted Crypto Wallet
Consider If: Limits/tiers and corridor specifics vary—check KYC levels.
Alternatives: Pouch.ph, MoneyGram
Regions: Philippines focus.
Fees Notes: Business rails cite very low basis-point costs; consumer pricing varies. Trusted Crypto Wallet
5. Yellow Card (Yellow Pay) — Best for intra-Africa stablecoin remittances
Why Use It: Yellow Card provides USDC-powered transfers across 20+ African countries through Yellow Pay, with app-level FX and local payout. It emphasizes simple, fast, transparent transfers over stablecoin rails at scale.
Best For: Africa-to-Africa family support • SMB payouts • Creator/contractor payments
Notable Features:
- Pan-African coverage; stablecoin settlement (USDC)
- Local rails for bank/mobile money payout
- Consumer app + business APIs
Consider If: Some markets have changing crypto rules—confirm eligibility.
Alternatives: AZA Finance, Kotani Pay
Regions: Africa (20+ countries).
Fees Notes: App shows FX/spread; some intra-app transfers may appear fee-free—confirm in-app.
6. Pouch.ph — Best for Lightning → bank/e-wallet payouts in the Philippines
Why Use It: Pouch abstracts the Bitcoin Lightning Network for senders and lands funds to PH banks/e-wallets in minutes. It’s a clean example of “bitcoin rails, fiat UX,” removing friction for overseas workers and micro-merchants.
Best For: U.S./global senders to PH • SMB invoices • Merchant settlement
Notable Features:
- Lightning under the hood; simple web/mobile experience
- Bank/e-wallet cash-out in the Philippines
- Merchant tools and local support
Consider If: Corridors are PH-centric; coverage outside PH is limited.
Alternatives: Strike, Coins.ph
Regions: PH payout focus.
Fees Notes: Network + FX spread; see app for live quote.
7. Tranglo — Best for enterprise APAC corridors via Ripple ODL
Why Use It: Tranglo is a cross-border payment hub that enabled Ripple’s On-Demand Liquidity (ODL) across its corridors, using XRP as a bridge asset to reduce pre-funding and improve speed. It provides enterprise access to a vast payout network in 100+ countries. Tranglo+2Tranglo+2
Best For: Licensed remittance operators • Fintechs • PSPs seeking APAC reach
Notable Features:
- ODL across many corridors; instant, pre-funding-free settlement Tranglo
- 5,000+ payout partners; 100+ countries Tranglo
- Portal + APIs for B2B integration
Consider If: ODL availability varies by corridor/compliance.
Alternatives: SBI Remit, Bitso Business
Regions: Global/APAC heavy.
Fees Notes: Enterprise pricing; FX spread + network costs.
8. SBI Remit — Best for Japan→PH/VN corridors using XRP ODL
Why Use It: SBI Remit launched a remittance service using XRP through Ripple/Treasure Data/Tranglo stack, focusing on the Japan→Philippines & Vietnam corridors. For Japan-origin transfers into Southeast Asia, it’s a regulated, XRP-settled option. remit.co.jp
Best For: Japan-based senders • B2B/B2C payout into PH/VN
Notable Features:
- XRP as bridge asset; fast settlement remit.co.jp
- Partnership with Tranglo for payout connectivity remit.co.jp
- Licensed, established remittance brand in JP
Consider If: Corridor scope is focused; confirm supported routes.
Alternatives: Tranglo, Coins.ph
Regions: Japan→Philippines, Vietnam.
Fees Notes: Standard remittance + FX; see SBI Remit schedule.
9. AZA Finance — Best for B2B Africa cross-border payouts over digital asset rails
Why Use It: Formerly BitPesa, AZA Finance specializes in enterprise cross-border payments and treasury in Africa, long known for leveraging digital asset rails to improve settlement. It supports multi-country bank and mobile-money payouts for payroll, vendor payments, and fintech flows.
Best For: Enterprises • Marketplaces • Fintech payout platforms
Notable Features:
- Local payout to bank/mobile money across African markets
- B2B focus with compliance onboarding
- FX + treasury support
Consider If: Requires business KYC and minimum volumes.
Alternatives: Yellow Card, Kotani Pay
Regions: Pan-Africa focus.
Fees Notes: Enterprise pricing; FX spread.
10. Kotani Pay — Best for stablecoin→mobile money in East Africa
Why Use It: Kotani Pay bridges stablecoins (notably on Celo) to mobile money (e.g., M-Pesa) so recipients can receive funds without a crypto wallet. This reduces friction and helps businesses/DAOs route funds compliantly to last-mile users.
Best For: NGOs/DAOs paying field teams • SMB payouts • Africa remittances to mobile money
Notable Features:
- Stablecoin→mobile money off-ramp (USSD flows)
- Business dashboards & APIs
- Kenya/Uganda coverage; expanding
Consider If: Coverage is country-specific; confirm supported networks.
Alternatives: Yellow Card, AZA Finance
Regions: East Africa focus.
Fees Notes: FX + mobile-money fees; confirm per country.
Decision Guide: Best By Use Case
- Cash pickup / cash-to-crypto: MoneyGram Ramps
- U.S.→PH via Lightning: Pouch.ph (also Strike for U.S.-origin)
- U.S.→MX & broader LATAM B2B: Bitso Business
- Japan→Southeast Asia with XRP ODL: SBI Remit (JP→PH/VN)
- Pan-Africa consumer remittances: Yellow Card (Yellow Pay)
- Africa B2B payouts & treasury: AZA Finance
- Enterprise APAC corridors / ODL aggregation: Tranglo
- Philippines retail wallet with stablecoins: Coins.ph
- Developer-friendly Lightning UX (sender side): Strike
How to Choose the Right Crypto Remittance Provider (Checklist)
- Confirm your corridor (origin/destination, currencies, payout method).
- Check rail type (Lightning vs stablecoins) and liquidity in that corridor.
- Verify licenses/compliance and recipient KYC/limits.
- Compare total cost (FX spread + transfer fee + network fee).
- Assess speed & reliability (minutes vs hours, cut-off times).
- Review on/off-ramp options (bank, e-wallet, mobile money, cash pickup).
- For businesses: look for APIs, SLAs, and settlement reporting.
- Red flags: unclear fees, no legal entity/licensing, or limited cash-out options.
Use Token Metrics With Any Remittance Workflow
- AI Ratings to vet counterparties and ecosystem risk.
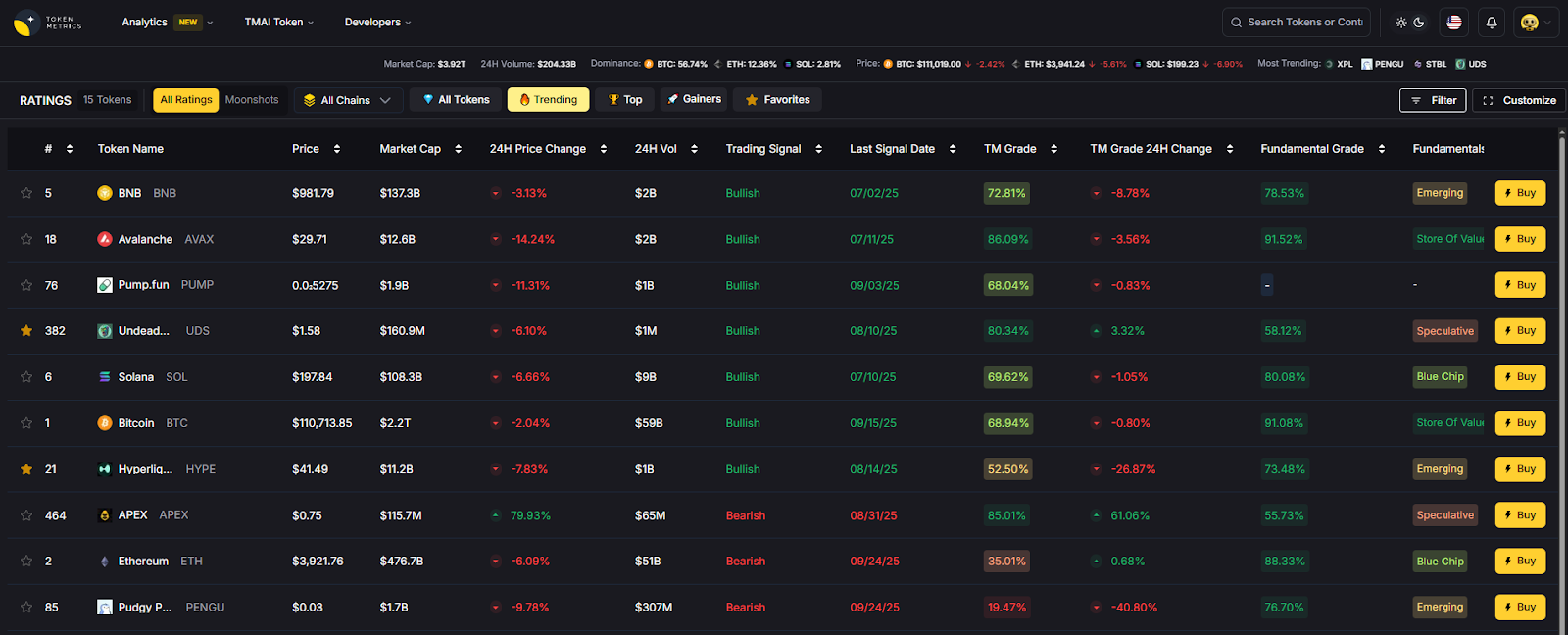
- Narrative Detection to monitor stablecoin/Lightning adoption trends.
- Portfolio Optimization for treasuries using stablecoins.
- Alerts/Signals to track market moves affecting FX and on-chain costs.
Workflow: Research corridors → Select provider → Execute → Monitor with alerts.
Primary CTA: Start free trial.

Security & Compliance Tips
- Enable 2FA; use strong device security for any wallet accounts.
- Clarify custody (who holds funds during transfer) and cash-out steps.
- Ensure KYC/AML is complete; keep sender/recipient identity docs ready.
- For businesses, use RFQ/quotes and transaction logs for audits.
- Practice wallet hygiene (test transfers, correct network/addresses).
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Assuming every provider supports your corridor without checking.
- Ignoring FX spreads—“zero fees” ≠ lowest total cost.
- Sending to the wrong network or without a supported cash-out.
- Overlooking recipient limits (daily/monthly) and KYC tiers.
- Relying on one payout method when recipients need bank + cash.
FAQs
What is a crypto remittance?
A cross-border transfer where value moves on-chain (e.g., Lightning, USDC) and is converted to local currency on arrival; it can cut costs and settlement time versus legacy rails.
Are crypto remittances cheaper than traditional methods?
They can be. Savings typically come from fewer intermediaries and 24/7 settlement, but FX spreads, cash-out fees, and network fees still apply. Trusted Crypto Wallet
Which is better for remittances: Lightning or stablecoins?
Lightning excels for low-cost, instant micro-payments; stablecoins are great for fiat-like value with broad exchange/wallet support. The best choice depends on corridor liquidity and payout options. Strike+1
Can I send crypto and have the recipient pick up cash?
Yes—networks like MoneyGram Ramps and select partners enable cash-in/out around USDC rails in supported countries. Availability and fees vary by location. anchors.stellar.org
What regions are strongest today?
LATAM (e.g., U.S.→Mexico), the Philippines, and many African corridors show strong on/off-ramp growth via stablecoins and Lightning. Bitso
Do I need a crypto wallet?
Not always. Many apps abstract the rails and pay out to bank accounts, e-wallets, or mobile money. Check each provider’s onboarding and recipient flow.
Conclusion + Related Reads
If you need cash pickup and stablecoin access, start with MoneyGram Ramps. For U.S.→PH or U.S.→Africa Lightning routes, consider Pouch.ph and Strike. For enterprise flows in LATAM/APAC/Africa, Bitso Business, Tranglo, SBI Remit, AZA Finance, Yellow Card, and Kotani Pay offer strong coverage—each with different strengths in corridors, payout types, and integration depth.
Related Reads:
- Which Cryptocurrency Exchange Should I Use in 2025? A Guide for Smart Trading
- Top Picks for the Best Crypto Trading Platform in 2025
- Top Web3 Wallets in 2025
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.