



Mantle (MNT) Price Prediction 2027 | Token Metrics Analysis
%201.svg)
%201.svg)


Mantle (MNT) Price Prediction: Portfolio Context for MNT - Diversification in the 2027 Landscape
Layer 2 tokens like Mantle offer exposure to Ethereum's scaling roadmap, but with concentration risk around one specific L2's adoption trajectory. MNT performance depends heavily on Mantle winning rollup market share against competing L2s. Diversified L2 exposure or broader L1 and L2 baskets reduce the risk of backing the wrong scaling solution.
Token Metrics price prediction scenarios below project MNT ranges across market environments. These outcomes assume Mantle maintains relevance as Ethereum scales, but portfolio theory suggests hedging this bet by holding multiple L2s or allocating to Ethereum itself, which benefits from L2 success regardless of which specific rollup dominates.
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to read it: Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline: Token Metrics long term view for Mantle, cashtag $MNT. Lead metric first, Token Metrics TM Grade is 68%, Buy, and the trading signal is bullish, indicating positive short-term momentum and above-average project quality. Concise 12-month numeric view, price prediction scenarios cluster roughly between $0.70 and $3.40, with a base case near $1.60.
Key Takeaways
- Scenario driven, outcomes hinge on total crypto market cap, higher liquidity and adoption lift the bands.
- Single-asset concentration amplifies both upside and downside versus diversified approaches.
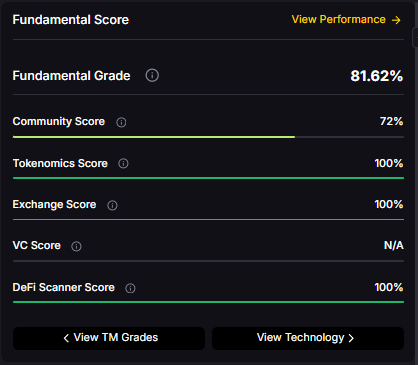
- Fundamentals: Fundamental Grade 81.62% (Community 72%, Tokenomics 100%, Exchange 100%, VC —, DeFi Scanner 100%).
- Technology: Technology Grade 78.22% (Activity 64%, Repository 70%, Collaboration 71%, Security —, DeFi Scanner 100%).
- TM Agent gist: bullish signal, 12‑month range roughly $0.70 to $3.40 with base near $1.60.
- Education only, not financial advice.
Scenario Analysis - MNT Price Prediction Models
Token Metrics price prediction scenarios span four market cap tiers, each representing different levels of crypto market maturity and liquidity:
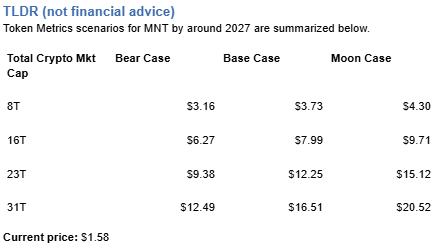
- 8T: At an 8 trillion dollar total crypto market cap, MNT projects to $3.16 in bear conditions, $3.73 in the base case, and $4.30 in bullish scenarios.
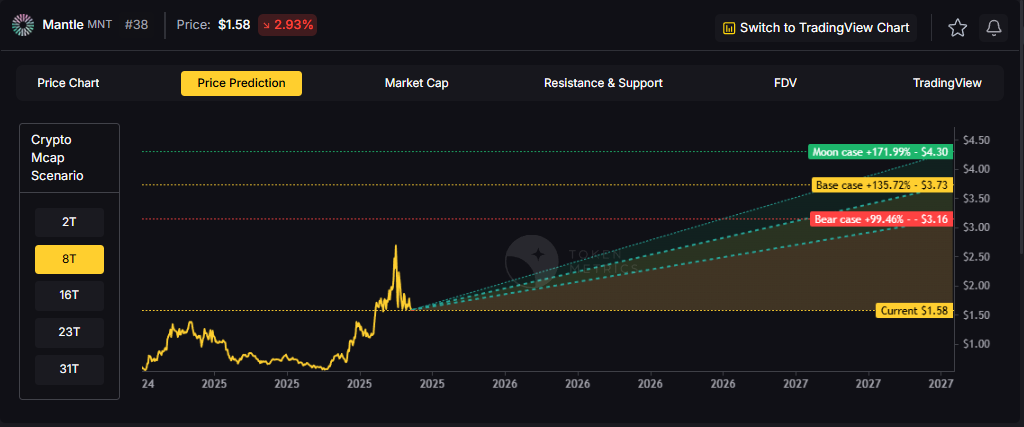
- 16T: Doubling the market to 16 trillion expands the price prediction range to $6.27 (bear), $7.99 (base), and $9.71 (moon).
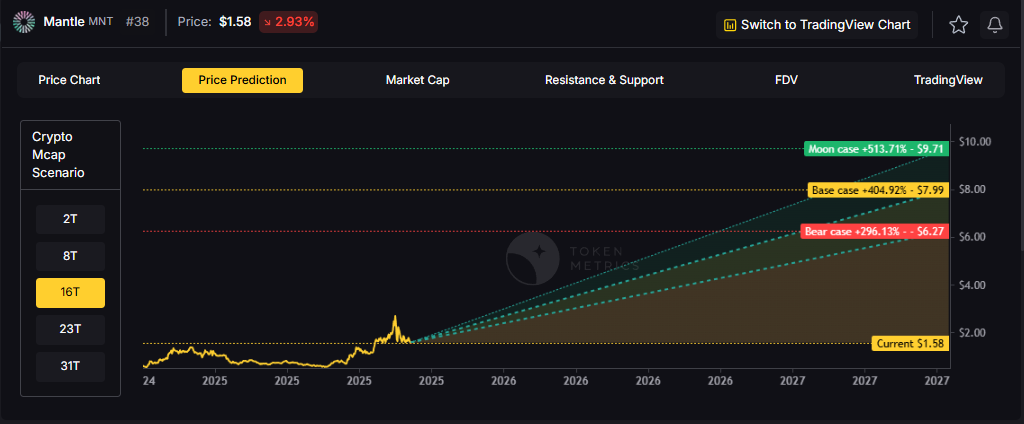
- 23T: At 23 trillion, the price prediction scenarios show $9.38, $12.25, and $15.12 respectively.
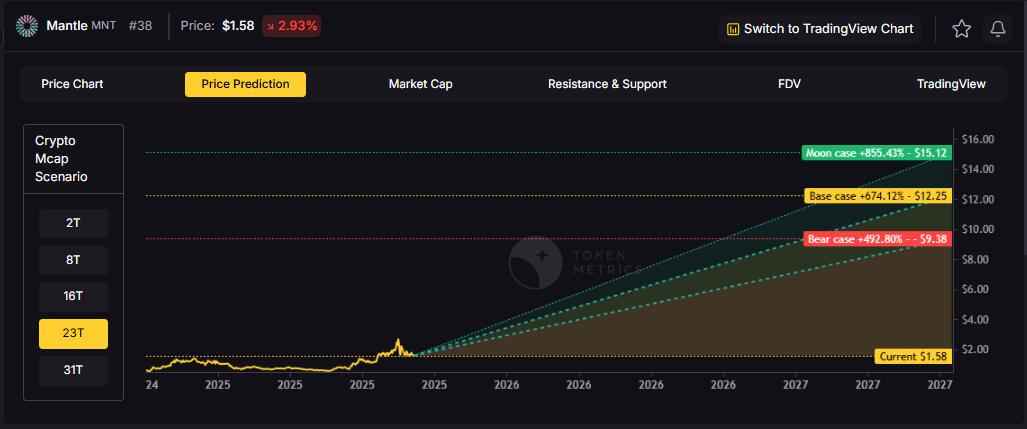
- 31T: In the maximum liquidity scenario of 31 trillion, MNT price prediction could reach $12.49 (bear), $16.51 (base), or $20.52 (moon).

These ranges illustrate potential outcomes for concentrated MNT positions, but investors should weigh whether single-asset exposure matches their risk tolerance or whether diversified strategies better suit their objectives.
The Case for Diversified Index Exposure
Portfolio theory teaches that diversification is the only free lunch in investing. MNT concentration violates this principle by tying your crypto returns to one protocol's fate. Token Metrics Indices blend Mantle with the top one hundred tokens, providing broad exposure to crypto's growth while smoothing volatility through cross-asset diversification. This approach captures market-wide tailwinds without overweighting any single point of failure.
Systematic rebalancing within index strategies creates an additional return source that concentrated positions lack. As some tokens outperform and others lag, regular rebalancing mechanically sells winners and buys laggards, exploiting mean reversion and volatility. Single-token holders miss this rebalancing alpha and often watch concentrated gains evaporate during corrections while index strategies preserve more gains through automated profit-taking.
Beyond returns, diversified indices improve the investor experience by reducing emotional decision-making. Concentrated MNT positions subject you to severe drawdowns that trigger panic selling at bottoms. Indices smooth the ride through natural diversification, making it easier to maintain exposure through full market cycles.
What Is Mantle?
Mantle is a blockchain project focused on scaling Ethereum via layer 2 rollup technology. The goal is to enable faster and cheaper transactions while inheriting Ethereum security. It targets scalable and efficient infrastructure for decentralized applications and financial services.
The MNT token powers network economics such as fees, incentives, or governance depending on implementation. Users interact with dApps and bridges within the ecosystem, and Mantle competes among leading Ethereum scaling solutions.
Token Metrics AI Analysis
- Vision: Mantle aims to build a scalable, secure, and self-sustaining blockchain ecosystem that leverages decentralized governance and treasury-backed financial innovation. Its vision emphasizes capital efficiency, leveraging restaking for security, and fostering long-term sustainability through community-driven development and treasury utilization.
- Problem: Many blockchain platforms face trade-offs between scalability, security, and capital efficiency. High transaction costs and network congestion on Ethereum, combined with fragmented liquidity and underutilized treasury assets in DAOs, create friction for developers and users. Mantle addresses the challenge of efficiently deploying capital while maintaining robust security and enabling rapid, low-cost transactions for decentralized applications.
- Solution: Mantle implements an Ethereum Layer 2 network using optimistic rollup technology to reduce fees and increase throughput. It integrates EigenLayer for security via restaking, allowing its treasury to earn yield and contribute to network validation. The ecosystem supports native governance through its token and funds development via a large DAO-managed treasury, aiming to create a self-sustaining cycle of innovation and user incentives.
- Market Analysis: Mantle operates in the competitive Layer 2 and modular blockchain space, competing with established networks like Arbitrum, Optimism, and emerging restaking platforms. Its differentiation lies in the integration of a large treasury with restaking, aiming to bootstrap security and ecosystem growth simultaneously. Adoption is driven by developer activity, yield opportunities, and strategic partnerships within the broader Ethereum ecosystem. Market risks include execution challenges in treasury management, regulatory scrutiny on DAO structures, and strong competition from other scaling solutions. While not a market leader like Ethereum or Bitcoin, Mantle participates in the broader narrative of modular, restaked, and treasury-driven blockchains, which have gained traction in 2024-2025.
Fundamental and Technology Snapshot from Token Metrics
- Fundamental Grade: 81.62% (Community 72%, Tokenomics 100%, Exchange 100%, VC —, DeFi Scanner 100%).
- Technology Grade: 78.22% (Activity 64%, Repository 70%, Collaboration 71%, Security —, DeFi Scanner 100%).

Catalysts That Skew Bullish
- Institutional and retail access expands with ETFs, listings, and integrations.
- Macro tailwinds from lower real rates and improving liquidity.
- Product or roadmap milestones such as upgrades, scaling, or partnerships.
Risks That Skew Bearish
- Macro risk-off from tightening or liquidity shocks.
- Regulatory actions or infrastructure outages.
- Concentration or validator economics and competitive displacement.
- Protocol-specific execution risk and competitive pressure from alternatives.
FAQs
Can MNT reach $10?
Based on the price prediction scenarios, MNT could reach $10 in the higher tiers. The 23T tier projects $12.25 in the base case, and the 31T tier shows $12.49 (bear), $16.51 (base), and $20.52 (moon). Achieving this requires both broad market cap expansion and Mantle maintaining competitive position. Not financial advice.
What's the risk/reward profile for MNT?
Risk and reward spans from $3.16 at 8T bear to $20.52 at 31T moon. Downside risks include competitive pressure among L2s and execution challenges, while upside drivers include adoption growth and liquidity expansion. Concentrated positions amplify both tails, while diversified strategies smooth outcomes.
What gives MNT value?
MNT accrues value through network usage, fees, incentives, and governance tied to Mantle's L2 ecosystem. Demand drivers include dApp activity, bridging, and security via restaking integrations. While these fundamentals matter, diversified portfolios capture value accrual across multiple tokens rather than betting on one protocol's success.
Where can I find Mantle price predictions?
Token Metrics provides comprehensive Mantle (MNT) price predictions through scenario-based analysis spanning multiple market cap tiers. Our data-driven price prediction models incorporate fundamental grades, technology scores, and market conditions to project potential MNT price targets across bear, base, and moon scenarios.

Next Steps
- Explore diversified crypto exposure: Token Metrics Indices Early Access
- Track Mantle fundamentals: Token Details
- Access Token Metrics platform for portfolio analytics
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, concentration amplifies risk, and diversification is a fundamental principle of prudent portfolio construction. Do your own research and manage risk appropriately.
Why Investors Choose Token Metrics
Token Metrics provides data-driven crypto ratings, on-chain grades, and scenario-based targets—empowering you to make informed investment decisions with confidence. Accelerate your research with unique AI-powered analysis and risk management tools.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.