



Top Yield Aggregators & Vaults (2025)
%201.svg)
%201.svg)


Why Yield Aggregators & Vaults Matter in September 2025
DeFi never sits still. Rates move, incentives rotate, and new chains launch weekly. Yield aggregators and vaults automate that work—routing your assets into on-chain strategies that can compound rewards and manage risk while you sleep. In short: a yield aggregator is a smart-contract “account” that deploys your tokens into multiple strategies to optimize returns (with risks).
Who is this for? Active DeFi users, long-term holders, DAOs/treasuries, and anyone exploring passive crypto income in 2025. We prioritized providers with strong security postures, transparent docs, useful dashboards, and broad asset coverage. Secondary angles include DeFi vaults, auto-compounders, and yield optimization tools.
How We Picked (Methodology & Scoring)
- Liquidity (30%) – scale, sustained TVL/volumes and depth across chains/pairs.
- Security (25%) – audits, disclosures, incident history, contracts/docs clarity.
- Coverage (15%) – supported assets, strategies, and chain breadth.
- Costs (15%) – vault/performances fees, hidden costs, gas efficiency.
- UX (10%) – clarity, portfolio tools, reporting, accessibility.
- Support (5%) – docs, community, communications, responsiveness.
Data sources: official product/docs, security and transparency pages; Token Metrics testing; cross-checks with widely cited market datasets when needed. Last updated September 2025.
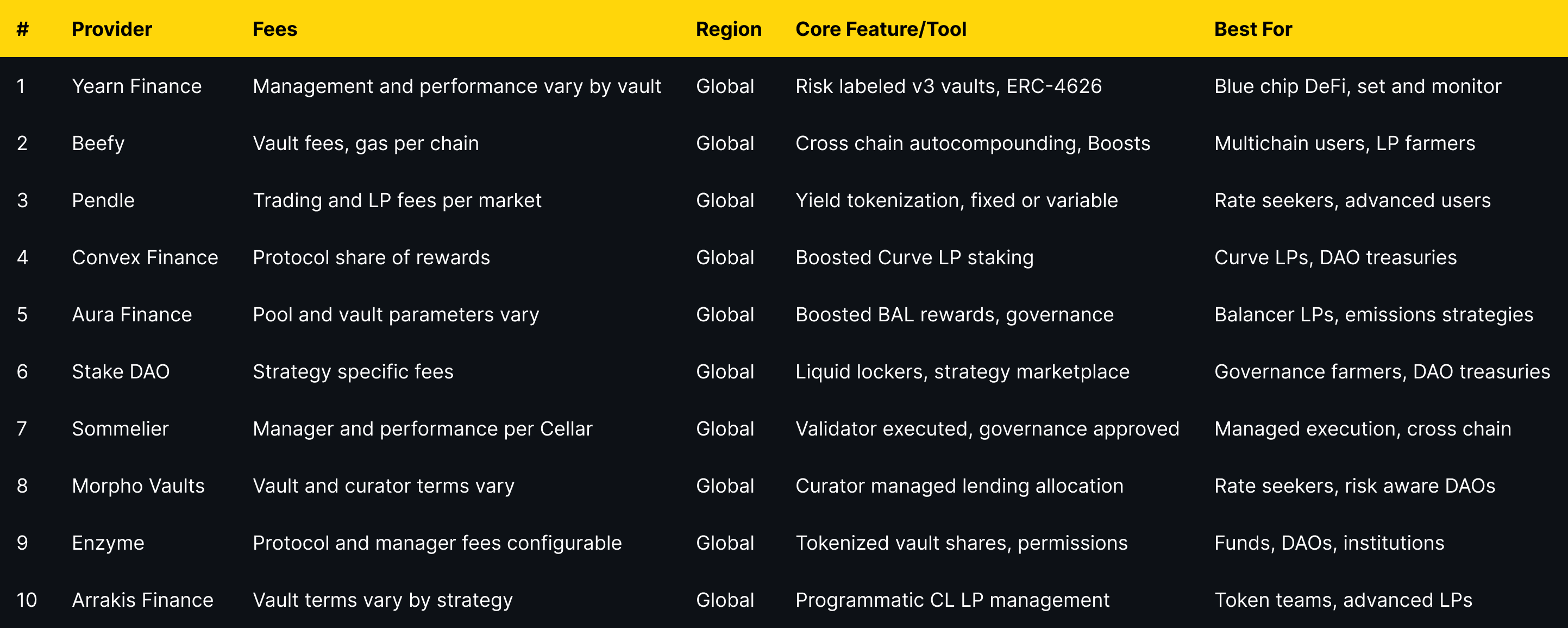
Top 10 Yield Aggregators & Vaults in September 2025
1. Yearn Finance — Best for blue-chip DeFi auto-compounding
- Why Use It: Yearn’s v3 vaults focus on automated, battle-tested strategies with risk labels and historical APY panes that make evaluation straightforward. You can pick targeted vaults (e.g., Curve/LST strategies) and let contracts handle compounding and rebalancing. Yearn+2Yearn Docs+2
- Best For: Long-term holders • Blue-chip DeFi exposure • “Set and monitor” users • DAO treasuries
- Notable Features: Risk-labeled v3 vaults • Multi-strategy routes • ERC-4626 standardization • Transparency via docs/app
- Consider If: You want conservative, audited strategies with clear dashboards vs. aggressive degen plays.
- Alternatives: Beefy • Sommelier
- Regions: Global
- Fees/Notes: Standard vault/performances fees vary by vault; check each vault page.
2. Beefy — Best multichain auto-compounder

- Why Use It: Beefy spans dozens of chains with a huge catalog of auto-compounding vaults (LPs and singles). If you farm across EVM ecosystems, Beefy’s breadth and simple UI make chain-hopping easier—and compounding automatic. beefy.com+1
- Best For: Power users across multiple chains • Yield farmers • Stablecoin/LP strategies
- Notable Features: Cross-chain coverage • “Boosts” campaigns • Strategy docs • Partner integrations
- Consider If: You want wide coverage and simple autocompounding rather than bespoke, strategy-managed funds.
- Alternatives: Yearn • Aura
- Regions: Global
- Fees/Notes: Vault-level fees; gas costs vary by chain.
3. Pendle — Best for fixed yield & yield trading
- Why Use It: Pendle tokenizes yield so you can earn fixed yield, long/short yield, or accumulate boosted “real yield” when conditions are attractive. It’s ideal if you want to lock in rates or speculate on future APYs with no liquidation risk. Pendle Finance+2Pendle Documentation+2
- Best For: Rate seekers • Sophisticated DeFi traders • LST/LRT and points farmers
- Notable Features: Yield tokenization (SY/PT/YT) • Fixed/variable yield markets • vePENDLE incentives
- Consider If: You understand interest-rate style products and settlement at maturity dates.
- Alternatives: Yearn (conservative) • Morpho (lending-based yields)
- Regions: Global
- Fees/Notes: Trading/LP fees; check markets per asset.
4. Convex Finance — Best for Curve ecosystem boosts
- Why Use It: Convex lets Curve LPs capture boosted CRV emissions and trading fees without locking CRV themselves. If your LP stack is Curve-heavy, Convex remains the go-to optimizer for rewards and governance alignment. Convex+1
- Best For: Curve LPs • veCRV stackers • DAO treasuries optimizing Curve positions
- Notable Features: Boosted staking for Curve LPs • cvxCRV staking • Aggregated rewards flows
- Consider If: Your liquidity sits primarily on Curve and you want to maximize incentives efficiently.
- Alternatives: Stake DAO • Aura
- Regions: Global
- Fees/Notes: Protocol takes a share of rewards; details in docs.
5. Aura Finance — Best for Balancer LP boosts
- Why Use It: Aura builds on Balancer to maximize BAL incentives and fees for LPs. Deposit Balancer LP tokens, earn boosted rewards, and participate in governance via locked AURA if you want additional influence over emissions. aura.finance+1
- Best For: Balancer LPs • Emissions-driven strategies • Governance-active users
- Notable Features: Boosted BAL rewards • Cross-chain Balancer support • Vote incentives via ve-style mechanics
- Consider If: Your primary liquidity is on Balancer; Aura is a natural optimizer there.
- Alternatives: Convex • Stake DAO
- Regions: Global
- Fees/Notes: Standard vault and protocol parameters vary by pool.
6. Stake DAO — Best for “liquid lockers” & strategy menus
- Why Use It: Stake DAO pioneered “liquid lockers” for governance tokens (e.g., CRV, BAL, FXS), offering boosted yields plus liquid representations of locked positions and a broad strategy shelf. stakedao.org+1
- Best For: Governance farmers • Curve/Balancer/FXS communities • DAO treasuries
- Notable Features: Liquid lockers • Strategy marketplace • Vote markets/governance tooling
- Consider If: You want governance exposure with yield and flexibility, not hard locks.
- Alternatives: Convex • Aura
- Regions: Global
- Fees/Notes: Strategy-specific fees; review each locker/strategy page.
7. Sommelier — Best for validator-supervised “Cellar” vaults
- Why Use It: Sommelier’s Cellars are ERC-4626 vaults curated by strategists and approved via governance; the Cosmos-based validator set executes transactions, aiming for safer, rules-based automation. It’s a nice middle ground between DIY farming and black-box funds. Sommelier+2Sommelier Finance+2
- Best For: Users wanting managed vaults with on-chain governance • Cross-chain strategy execution
- Notable Features: Validator-executed strategies • Governance-approved vaults • ERC-4626 standard
- Consider If: You value managed execution and transparency over maximal degen yields.
- Alternatives: Yearn • Enzyme
- Regions: Global
- Fees/Notes: Vault-specific management/performance fees; see each Cellar.
8. Morpho Vaults — Best for curated lending vaults
- Why Use It: Morpho Vaults (evolved from MetaMorpho) route deposits across Morpho Blue lending markets, curated by third-party risk experts. It’s lending-centric yield with visible curators, risk budgets, and permissionless vault creation. morpho.org+2morpho.org+2
- Best For: Rate seekers comfortable with lending risk • Risk-aware DAOs/treasuries
- Notable Features: Curator-managed allocation • Transparent risk profiles • Permissionless vaults
- Consider If: You want lending-market yields with curator oversight, not AMM-LP farming.
- Alternatives: Pendle (rates via yield tokens) • Yearn
- Regions: Global
- Fees/Notes: Vault/curator parameters vary; review each vault.
9. Enzyme — Best for custom, institutional-grade vaults
- Why Use It: Enzyme provides infrastructure to spin up tokenized vaults—useful for DAOs, managers, and institutions who need controls, fee models, and compliance-minded workflows. You can deploy diversified or structured strategies and issue shares to depositors. enzyme.finance+2enzyme.finance+2
- Best For: Funds/DAOs • Institutional treasuries • Strategy builders needing controls
- Notable Features: Tokenized vault shares • Configurable fees/permissions • Treasury & structured product tooling
- Consider If: You want to create and operate vaults (not just deposit).
- Alternatives: Sommelier • Arrakis (for LP-specific vaults)
- Regions: Global
- Fees/Notes: Protocol and manager fees configurable per vault.
10. Arrakis Finance — Best for concentrated-liquidity LP vaults
- Why Use It: Arrakis V2 focuses on programmatic Uniswap-style LP management. Vaults issue ERC-20 shares, rebalance ranges, and can be set up as private “Pro” vaults for token issuers or public strategies for LPs—great if your yield comes from maker fees and incentives. arrakis.finance+2beta.arrakis.finance+2
- Best For: Token teams/treasuries • Advanced LPs • Liquidity mining with CL AMMs
- Notable Features: Modular vault architecture • Programmatic rebalancing • Public & private vault modes
- Consider If: You prefer fee-based LP yields over farm-and-dump emissions.
- Alternatives: Gamma-style LP managers (varies) • Enzyme (custom)
- Regions: Global
- Fees/Notes: Vault terms vary; check each vault/strategy.
Decision Guide: Best By Use Case
- Regulated, conservative posture: Yearn, Sommelier, Enzyme
- Global chain coverage & autocompound: Beefy
- Curve LP optimization: Convex
- Balancer LP optimization: Aura
- Fixed yield / yield trading: Pendle
- Lending-centric rates with curator oversight: Morpho Vaults
- LP vaults for token issuers: Arrakis
- DAO treasuries & strategy builders: Enzyme, Stake DAO
How to Choose the Right Yield Aggregators & Vaults (Checklist)
- Region/eligibility and front-end access (some sites warn on local restrictions).
- Asset & chain coverage that matches your portfolio.
- Custody model (self-custody vs. managed) and who can move funds.
- Fees: management/performance, withdrawal, gas.
- Strategy transparency: docs, parameters, risk labels.
- UX: dashboards, reporting, TVL history.
- Support: docs, forums, community channels.
- Red flags: unaudited contracts, opaque fees, admin keys without disclosures.
Use Token Metrics With Any Yield Aggregators & Vaults
- AI Ratings to quickly screen protocols and assets.
- Narrative Detection to spot yield rotations (LRTs, stablecoin points, etc.).
- Portfolio Optimization to balance rate, volatility, and correlation.
- Alerts/Signals to track entries/exits and net APY shifts.
Workflow: Research → Select → Execute on provider → Monitor with alerts.
Primary CTA: Start free trial.

Security & Compliance Tips
- Enable 2FA on wallets/interfaces where applicable; use hardware wallets for size.
- Understand vault custody: permissions, pausable states, and upgradeability.
- Follow KYC/AML and tax rules in your jurisdiction; some front-ends gate regions.
- Diversify across strategies/curators; avoid over-concentration.
- Practice wallet hygiene: approvals management, separate hot/cold wallets.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Chasing only headline APY without reading how it’s produced.
- Ignoring gas/fee drag when compounding on L1 vs. L2.
- Depositing into unaudited or opaque vaults.
- Over-allocating to a single strategy/chain.
- Forgetting lockups/maturities (e.g., Pendle) and withdrawal mechanics.
FAQs
What is a yield aggregator in crypto?
A yield aggregator is a smart-contract system that deploys your tokens into multiple DeFi strategies and auto-compounds rewards to target better risk-adjusted returns than manual farming.
Are vaults custodial?
Most DeFi vaults are non-custodial contracts—you keep control via your wallet, while strategies execute on-chain rules. Always read docs for admin keys, pausable functions, and upgrade paths.
Fixed vs. variable yield—how do I choose?
If you value certainty, fixed yields (e.g., via Pendle) can make sense; variable yield can outperform in risk-on markets. Many users blend both.
What fees should I expect?
Common fees are management, performance, and withdrawal (plus gas). Each vault shows specifics; compare net, not just gross APY.
Which networks are best for beginners?
Start on mainstream EVM chains with strong tooling (Ethereum L2s, major sidechains). Fees are lower and UI tooling is better for learning.
How safe are these platforms?
Risks include contract bugs, oracle issues, market shocks, and governance. Prefer audited, well-documented protocols with visible risk controls—and diversify.
Conclusion + Related Reads
If you want set-and-forget blue-chips, start with Yearn or Sommelier. Multichain farmers often prefer Beefy. Curve/Balancer LPs should consider Convex/Aura. Rate-sensitive users may like Pendle or Morpho Vaults. Builders and treasuries should look at Enzyme and Arrakis for tailored vault setups.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
Sources & Update Notes
We reviewed each provider’s official site, docs, and product pages for features, security notes, and positioning. Third-party datasets were used only to cross-check market presence. Updated September 2025.
- Yearn Finance — App & Docs: yearn.fi, docs.yearn.fi (Vaults, v3 overview). Yearn+2Yearn Docs+2
- Beefy — Site & Docs: beefy.com, docs.beefy.finance. beefy.com+1
- Pendle — Site, App & Docs: pendle.finance, app.pendle.finance, docs.pendle.finance. Pendle Finance+2Pendle V2+2
- Convex Finance — Site & Docs: convexfinance.com, docs.convexfinance.com. Convex+1
- Aura Finance — Site & App: aura.finance, app.aura.finance. aura.finance+1
- Stake DAO — Site & Yield page: stakedao.org. stakedao.org+1
- Sommelier — Site & Docs (Cellars): somm.finance, sommelier-finance.gitbook.io. Sommelier+1
- Morpho — Vaults page & blog: morpho.org/vaults, morpho.org/blog. morpho.org+1
- Enzyme — Site & Vault docs: enzyme.finance. enzyme.finance+1
- Arrakis Finance — Site, V2 vaults & docs/github: arrakis.finance, beta.arrakis.finance, docs.arrakis.finance, github.com/ArrakisFinance. GitHub+3arrakis.finance+3beta.arrakis.finance+3
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.