



Best Crypto Payment Processors for Merchants (2025)
%201.svg)
%201.svg)

Why crypto payment processors for merchants Matter in September 2025
If you sell online (or in-store) and want to accept Bitcoin or stablecoins, choosing the best crypto payment processors can lower costs, expand global reach, and reduce chargeback risk. In one line: a crypto payment processor lets merchants accept digital assets at checkout and settle in crypto or fiat while handling pricing, invoicing, and compliance basics.
In 2025, stablecoin rails and Lightning are improving speed and costs, while major gateways add plugins for Shopify, WooCommerce, and custom APIs. This guide is for startups and enterprises comparing fees, settlement options, asset coverage, and regional availability. We blend live docs research with practical fit notes so you can pick confidently and ship faster.
How We Picked (Methodology & Scoring)
- Liquidity (30%): breadth of supported assets/rails (BTC, stablecoins, Lightning), reliability of conversion/settlement.
- Security (25%): custody model, key management options, certifications, and clear incident/disclosure pages.
- Coverage (15%): e-commerce plugins, API maturity, payouts, and fiat-settlement choices.
- Costs (15%): transparent processing fees, conversion/payout costs.
- UX (10%): checkout speed, invoicing, reporting, and developer experience.
- Support (5%): docs quality, SLA, enterprise support.
Data sources: official product/docs, pricing/security pages, and (for cross-checks only) widely cited market datasets. Last updated September 2025.
Top 10 crypto payment processors for merchants in September 2025
1. BitPay — Best for mature U.S. merchants wanting stable operations
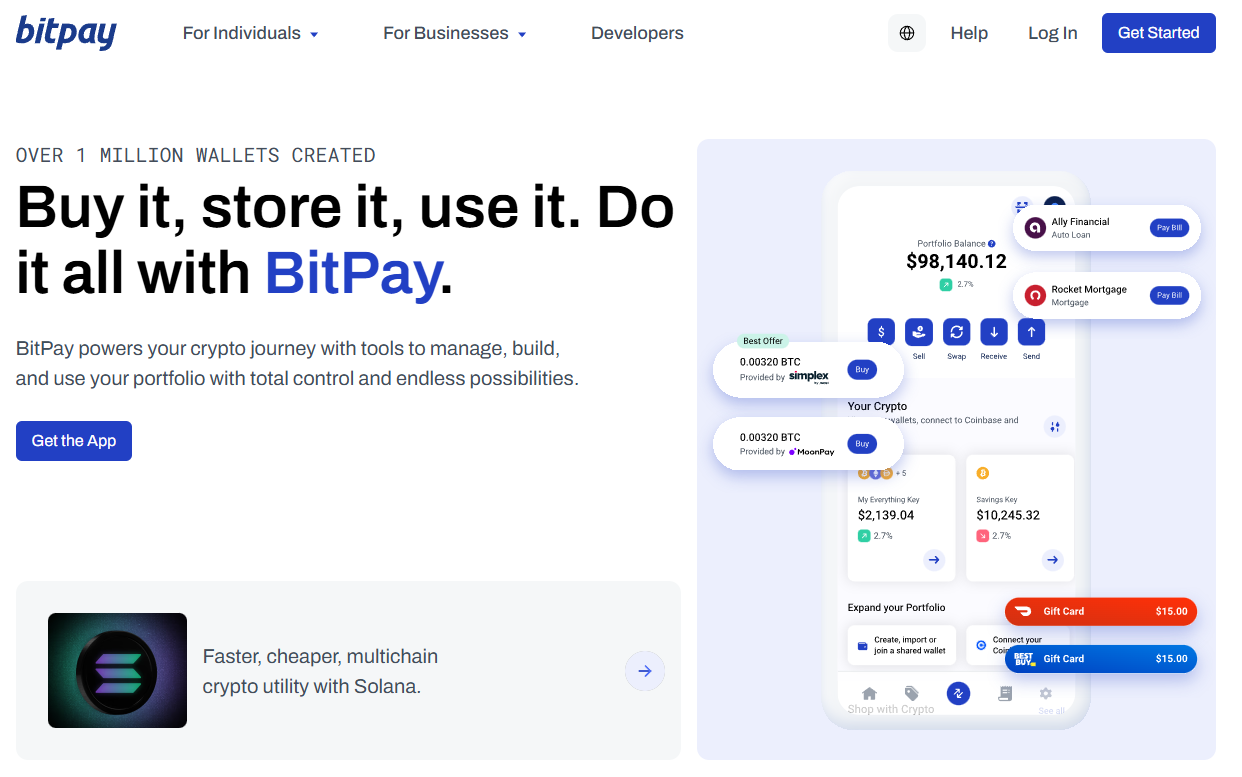
- Why Use It: One of the longest-running crypto processors with robust invoicing, refunds, accounting exports, and fiat settlement. Tiered pricing and clear policies suit compliance-sensitive teams. BitPay+1
- Best For: U.S./EU retailers, subscriptions, digital goods, B2B invoices.
- Notable Features: Branded checkout links; partial/full refunds; mass payouts; settlement in multiple currencies; stablecoin support. support.bitpay.com
- Consider If: You want predictable fees and traditional support over maximum coin variety.
- Fees/Regions: Tiered 1–2% + $0.25 per transaction; extensive global reach. BitPay
- Alternatives: Coinbase Commerce, CoinGate.
2. Coinbase Commerce — Best for simple USDC/crypto checkout with fiat-style reporting
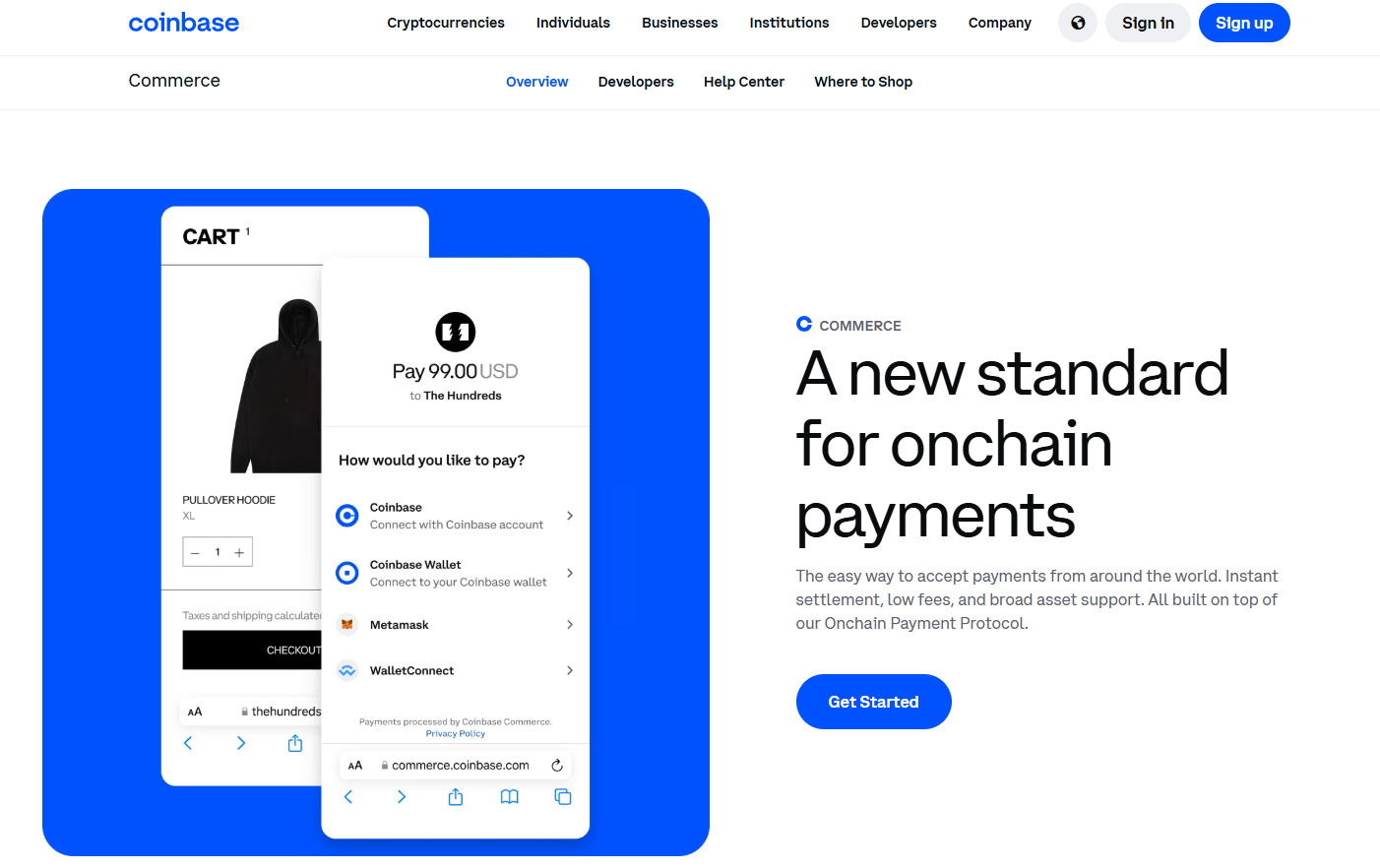
- Why Use It: Clean merchant dashboard, simple payment links, and an onchain payment protocol with automatic conversions; integrates neatly with Coinbase ecosystem and USDC flows. Coinbase
- Best For: SaaS, creators, and startups already using Coinbase.
- Notable Features: Payment links; ecommerce plugins; onchain protocol migration; automatic fee display and reporting. Coinbase Help
- Consider If: You want a recognizable brand and 1% flat pricing.
- Fees/Regions: 1% processing fee; broad availability (jurisdictional limits may apply). Coinbase Help
- Alternatives: BitPay, Crypto.com Pay.
3. CoinGate — Best for multi-coin coverage and EU-friendly payouts
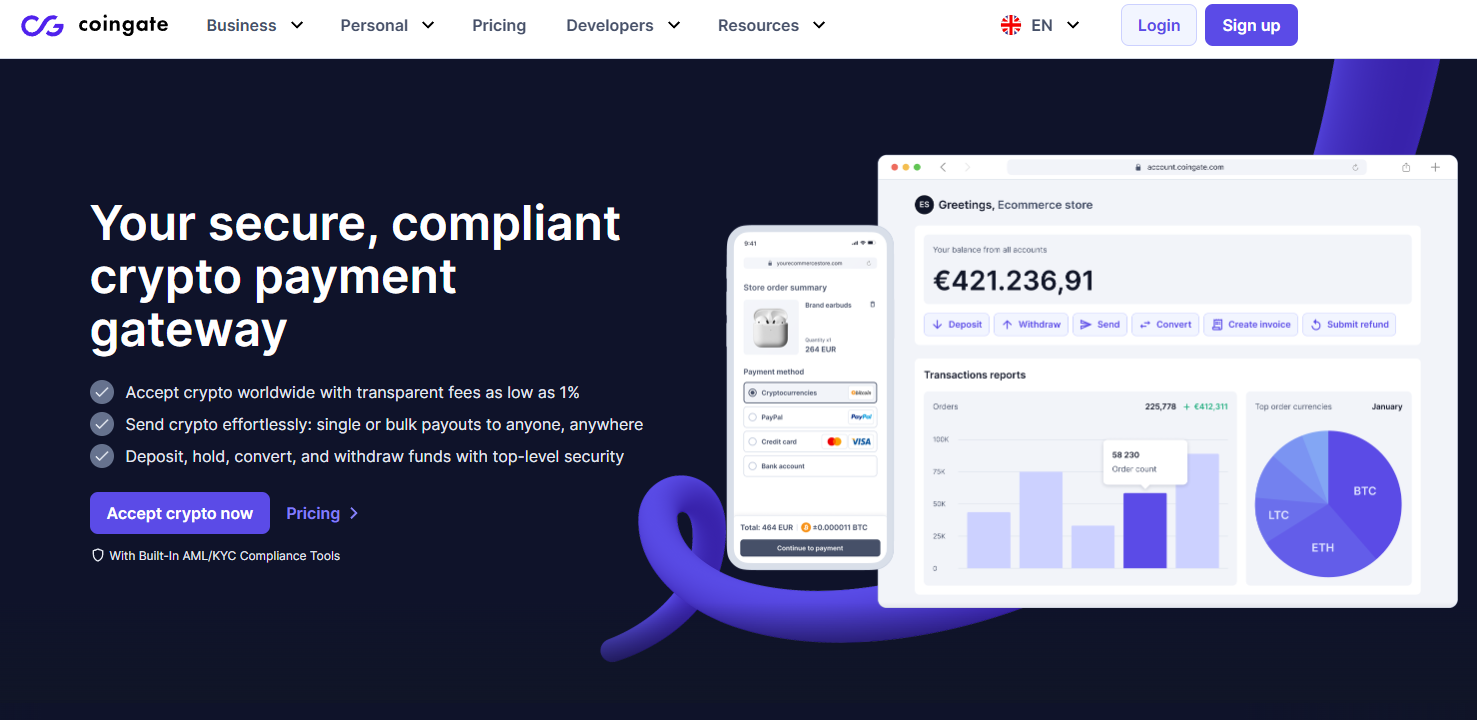
- Why Use It: Transparent pricing and solid plugin coverage (WooCommerce, OpenCart, etc.) with weekly settlements and crypto payouts. Best Bitcoin & Crypto Payment Processor
- Best For: EU merchants, hosting/VPNs, and globally distributed ecommerce.
- Notable Features: 1% processing; refunds in crypto; payouts with/without conversion; accepts customers from 180+ countries. Best Bitcoin & Crypto Payment Processor
- Consider If: You need flexible payouts and many altcoins.
- Fees/Regions: 1% processing; additional small fees for certain payout types; EU/Global. Best Bitcoin & Crypto Payment Processor
- Alternatives: CoinPayments, NOWPayments.
4. CoinPayments — Best for plugins and long-tail altcoin acceptance
- Why Use It: A veteran gateway with broad coin support and deep ecommerce integrations (BigCommerce, WooCommerce). Good for merchants courting crypto-native audiences. CoinPayments
- Best For: Online stores, marketplaces, gaming.
- Notable Features: Auto-conversion between coins; extensive plugin library; merchant tools and invoicing. BigCommerce
- Consider If: You want low, flat pricing across many assets.
- Fees/Regions: 0.5% processing (plus network fees); Global. CoinPayments
- Alternatives: CoinGate, NOWPayments.
5. NOWPayments — Best for lowest advertised base rate with auto-conversion
- Why Use It: Simple setup, broad coin list, and clear fee tiers—great for testing crypto checkout with minimal overhead. NOWPayments
- Best For: SMB ecommerce, content creators, charities.
- Notable Features: 300+ coins; donations/PoS widgets; subscriptions; mass payouts; auto-conversion. NOWPayments
- Consider If: You value quick launch and wide asset coverage.
- Fees/Regions: 0.5% monocurrency; 1% with conversion (excl. network fees); Global. NOWPayments
- Alternatives: CoinPayments, CoinGate.
6. OpenNode — Best for Bitcoin + Lightning with fiat conversion
- Why Use It: Lightning-native processing for low fees and instant settlement, with optional auto-conversion to local currency to avoid BTC volatility. OpenNode
- Best For: High-volume BTC checkouts, gaming, and emerging markets needing fast micro-payments.
- Notable Features: Hosted checkout; API; automatic conversion; bank settlements; PoS. OpenNode
- Consider If: You prioritize Lightning speed and simple, transparent pricing.
- Fees/Regions: 1% transaction fee; supports many currencies and countries; Global. OpenNode
- Alternatives: Lightspark, BTCPay Server (self-hosted).
7. Lightspark — Best enterprise Lightning infrastructure
- Why Use It: Enterprise-grade Lightning with AI-assisted routing, flexible custody models, and SLA-style support—ideal for platforms embedding realtime payments. Lightspark
- Best For: Fintechs, exchanges, marketplaces, and PSPs embedding Bitcoin/Lightning.
- Notable Features: Managed nodes; Predict routing; UMA support; role-based access; audit-ready reporting. Lightspark
- Consider If: You need predictable Lightning performance at scale.
- Fees/Regions: Starter 0.50%; Enterprise 0.30–0.15% with volume tiers; Global. Lightspark
- Alternatives: OpenNode, Coinbase Commerce (non-Lightning).
8. Crypto.com Pay — Best for ecosystem reach and co-marketing
- Why Use It: Merchant app + plugins, catalog placement, and cash settlement with zero crypto price risk claims; strong brand for consumer trust. Crypto.com
- Best For: Retail, entertainment, and brands wanting exposure to Crypto.com’s user base.
- Notable Features: API & plugins (Shopify/WooCommerce); recurring for app users; in-store app acceptance; security certifications displayed. Crypto.com
- Consider If: You want marketing reach alongside payments.
- Fees/Regions: Availability and settlement options vary by jurisdiction; “300M+ USD processed per annum” marketing stat on site. Crypto.com
- Alternatives: Coinbase Commerce, BitPay.
9. TripleA — Best for compliance-first global merchants (MAS-licensed)
- Why Use It: Singapore-based gateway emphasizing licensing and compliance (MAS Major Payment Institution), with global acceptance and fiat settlement. eServices
- Best For: Regulated industries, cross-border ecommerce, APAC reach.
- Notable Features: Merchant APIs; ecommerce plugins; settlement to bank accounts; multi-asset support. Triple-A – Triple-A
- Consider If: Licensing and audits matter more than long-tail altcoins.
- Fees/Regions: Pricing by quote; Licensed in Singapore; Global coverage. eServices
- Alternatives: BitPay, CoinGate.
10. Alchemy Pay — Best hybrid fiat-crypto acceptance with wide country reach
- Why Use It: Hybrid rails (on/off-ramp + crypto payments) covering 173 countries, with fiat settlement and SDKs for web/app flows; active U.S. licensing expansion. Alchemy Pay+2Alchemy Pay+2
- Best For: Global ecommerce, super-apps, and platforms needing both purchase and checkout rails.
- Notable Features: Checkout SDK; QR/wallet payments; off-ramp payouts; partner integrations. docs
- Consider If: You want one vendor for ramps + crypto acceptance.
- Fees/Regions: Pricing via sales; jurisdictional variability noted; Global/APAC focus with growing U.S. coverage. xinwen.alchemypay.org+1
- Alternatives: Crypto.com Pay, Coinbase Commerce.
Decision Guide: Best By Use Case
- Regulated U.S./EU brands: BitPay, TripleA, Coinbase Commerce. BitPay+2eServices+2
- Global altcoin coverage: CoinPayments, CoinGate, NOWPayments. CoinPayments+2Best Bitcoin & Crypto Payment Processor+2
- Lightning/micropayments: OpenNode, Lightspark. OpenNode+1
- Ecosystem reach/co-marketing: Crypto.com Pay. Crypto.com
- All-in-one ramps + acceptance: Alchemy Pay. Alchemy Pay
- Simple 1% flat fee and easy links: Coinbase Commerce. Coinbase Help
How to Choose the Right crypto payment processors for merchants (Checklist)
- Confirm regional eligibility and licensing (e.g., U.S., EU, APAC).
- Compare processing + conversion + payout fees (not just headline rates).
- Decide on settlement (crypto vs. fiat) and supported currencies.
- Check plugin coverage (Shopify, WooCommerce) and API maturity.
- Review security posture (custody model, certifications, disclosures).
- Validate support/SLA and refund workflows.
- Red flags: vague fees, no docs/status page, or unclear settlement policies.
Use Token Metrics With Any crypto payment processors for merchants
- AI Ratings: screen coins and chains your customers actually use.
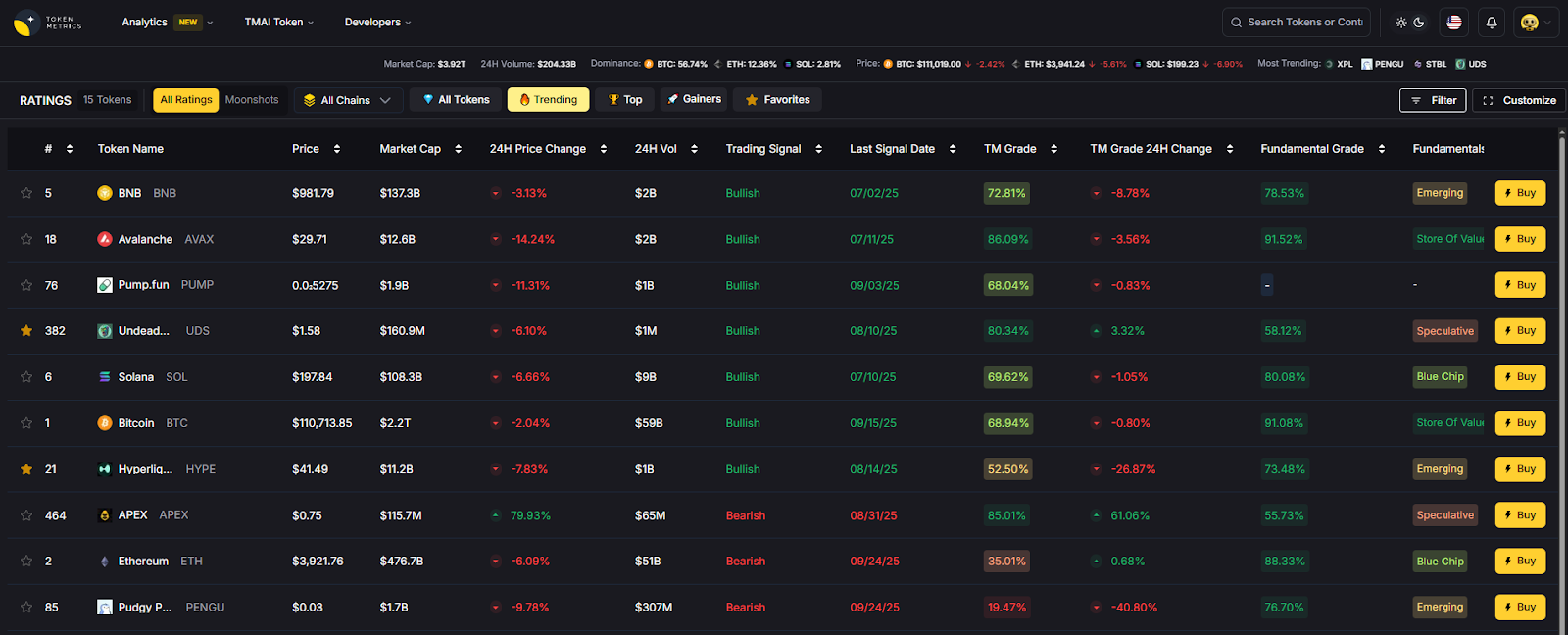
- Narrative Detection: spot momentum (e.g., stablecoin or Lightning surges).
- Portfolio Optimization: model treasury exposure if you keep a crypto balance.
- Alerts & Signals: monitor market moves that affect checkout conversions.
Workflow: Research in TM → Pick a processor → Go live → Monitor with alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enable 2FA and role-based access on the merchant dashboard.
- Choose custody/settlement that fits your risk (self-custody vs. managed, fiat vs. crypto).
- Follow KYC/AML and tax rules in each operating region.
- For RFQ/OTC conversions, document rates/partners.
- Keep wallet hygiene (whitelists, limited hot-wallet balances).
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Chasing the lowest “headline rate” while ignoring conversion/payout fees.
- Forgetting to test refunds, partial payments, and expired invoices.
- Launching without clear settlement currency and payout timing.
- Relying on a single chain/asset when your audience uses others.
- Ignoring jurisdictional limitations and licensing disclosures.
FAQs
What is a crypto payment processor for merchants?
A service that lets businesses accept digital assets (e.g., BTC, USDC) and settle in crypto or fiat while handling pricing, invoicing, and basic compliance/reporting.
Are crypto fees lower than card fees?
Often yes—many gateways list ~0.5–1% base rates, though network and conversion/payout fees can apply. Compare total effective cost per order. Best Bitcoin & Crypto Payment Processor+2CoinPayments+2
Can I receive USD/EUR instead of crypto?
Most processors offer instant conversion and fiat settlement to bank accounts in supported regions. Check your vendor’s settlement currencies and schedules. OpenNode+1
Which is best for Lightning or micro-payments?
OpenNode and Lightspark are built around Lightning for instant, low-cost payments, with enterprise options and APIs. OpenNode+1
Is self-hosting a gateway possible?
Yes—projects like BTCPay Server exist for technical teams, but managed gateways reduce operational burden and add fiat settlement options.
Conclusion + Related Reads
Merchants should match checkout rails to customer demand: go BitPay/Coinbase Commerce for simplicity and brand trust, CoinGate/CoinPayments/NOWPayments for broad asset coverage, OpenNode/Lightspark for Lightning speed, and Alchemy Pay/Crypto.com Pay for hybrid rails and reach. Test fees and settlement with a pilot, then scale.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Decentralized Exchanges (DEXs) by Liquidity & UX (2025)
- Top Institutional Custody Providers 2025
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.