



Best Custody Insurance Providers (2025)
%201.svg)
%201.svg)

Why Custody Insurance Matters in September 2025
Institutions now hold billions in digital assets, and regulators expect professional risk transfer—not promises. Custody insurance providers bridge the gap by transferring losses from theft, key compromise, insider fraud, and other operational failures to regulated carriers and markets. In one line: custody insurance is a specialized policy that helps institutions recover financial losses tied to digital assets held in custody (cold, warm, or hot) when defined events occur. As spot ETF flows and bank re-entries accelerate, boards want auditable coverage, clear exclusions, and credible capacity. This guide highlights who actually writes, brokers, and structures meaningful digital-asset custody insurance in 2025, and how to pick among them. Secondary considerations include capacity, claims handling, supported custody models, and regional eligibility across Global, US, EU, and APAC.
How We Picked (Methodology & Scoring)
- Scale/Liquidity (30%) — demonstrated capacity, panel depth (carriers/reinsurers/markets), and limits available for custody crime/specie.
- Security & Underwriting Rigor (25%) — due diligence on key management, operational controls, audits, and loss prevention expectations.
- Coverage Breadth (15%) — hot/warm/cold support, staking/slashing riders, social-engineering, wallet recovery, smart-contract add-ons.
- Costs (15%) — indicative premiums/deductibles vs. limits; structure efficiency (excess, towers, programs).
- UX (10%) — clarity of wordings, onboarding guidance, claims transparency.
- Support (5%) — global service footprint, specialist teams (DART/crypto units), and education resources.
We prioritized official product/security pages, disclosures, and market directories; third-party datasets were used only for cross-checks. Last updated September 2025.
Top 10 Custody Insurance Providers in September 2025
1. Evertas — Best for Dedicated Crypto Crime & Custody Cover

Why Use It: Evertas is a specialty insurer focused on crypto, offering A-rated crime/specie programs tailored to cold, warm, and hot storage with practitioner-level key-management scrutiny. Their policies target the operational realities of custodians and platforms, not just generic cyber forms. evertas.com+1
Best For: Qualified custodians, exchanges, trustees, prime brokers.
Notable Features:
- Crime/specie coverage across storage tiers. evertas.com
- Crypto-native underwriting of private-key processes. evertas.com
- Lloyd’s-backed capacity with global reach. evertas.com
Consider If: You need a crypto-first insurer vs. a generalist broker.
Alternatives: Marsh, Canopius.
Regions: Global.
2. Coincover — Best for Warranty-Backed Protection & Wallet Recovery

Why Use It: Coincover provides proactive fraud screening, disaster recovery for wallets, and warranty-backed protection that can sit alongside traditional insurance programs—useful for fintechs and custodians embedding safety into UX. Lloyd’s syndicates partnered with Coincover to launch wallet coverage initiatives. coincover.com+2coincover.com+2
Best For: B2B platforms, fintechs, MPC vendors, exchanges seeking embedded protection.
Notable Features:
- Real-time outbound transaction screening. coincover.com
- Wallet recovery and disaster-recovery tooling. coincover.com
- Warranty-backed protection that “makes it right” on covered failures. coincover.com
Consider If: You want prevention + recovery layered with traditional insurance.
Alternatives: Evertas, Marsh.
Regions: Global.
3. Marsh (DART) — Best Global Broker for Building Towers
Why Use It: Marsh’s Digital Asset Risk Transfer team is a top broker for structuring capacity across crime/specie/D&O and connecting clients to specialist markets. They also advertise dedicated solutions for theft of digital assets held by institutions. Marsh+1
Best For: Large exchanges, custodians, ETF service providers, banks.
Notable Features:
- Specialist DART team and market access. Marsh
- Program design across multiple lines (crime/specie/E&O). Marsh
- Solutions aimed at institutional theft protection. Marsh
Consider If: You need a broker to source multi-carrier, multi-region capacity.
Alternatives: Aon, Lloyd’s Market.
Regions: Global.
4. Aon — Best for Custody Assessments + Crime/Specie Placement
Why Use It: Aon’s digital-asset practice brokers crime/specie, D&O, E&O, and cyber, and offers custody assessments and loss-scenario modeling—useful for underwriting readiness and board sign-off. Aon+1
Best For: Banks entering custody, prime brokers, tokenization platforms.
Notable Features:
- Crime & specie for theft of digital assets. Aon
- Custody assessments and PML modeling. Aon
- Cyber/E&O overlays for staking and smart-contract exposure. Aon
Consider If: You want pre-underwriting hardening plus market reach.
Alternatives: Marsh, Evertas.
Regions: Global.
5. Munich Re — Best for Reinsurance-Backed Crime & Staking Risk
Why Use It: As a top global reinsurer, Munich Re provides digital-asset crime policies designed for professional custodians and platforms, with coverage spanning external hacks, employee fraud, and certain third-party breaches—often supporting primary carriers. Munich Re
Best For: Carriers building programs; large platforms needing robust backing.
Notable Features:
- Comprehensive crime policy for custodians and trading venues. Munich Re
- Options for staking and smart-contract risks. Munich Re
- Capacity and technical guidance at program level. Munich Re
Consider If: You’re assembling a tower requiring reinsurance strength.
Alternatives: Lloyd’s Market, Canopius.
Regions: Global.
6. Lloyd’s Market — Best Marketplace to Source Specialist Syndicates
Why Use It: Lloyd’s is a global specialty market where syndicates (e.g., Atrium) have launched crypto wallet/custody solutions, often in partnership with firms like Coincover. Access via brokers to build bespoke custody crime/specie programs with flexible limits. Lloyds+1
Best For: Firms needing bespoke wording and multi-syndicate capacity.
Notable Features:
- Marketplace access to expert underwriters. Lloyds
- Wallet/custody solutions pioneered by syndicates. Lloyds
- Adjustable limits and layered structures. Lloyds
Consider If: You use a broker (Marsh/Aon) to navigate syndicates.
Alternatives: Munich Re (reinsurance), Canopius.
Regions: Global.
7. Canopius — Best Carrier for Cross-Class Custody (Crime/Specie/Extortion)
Why Use It: Canopius underwrites digital-asset custody coverage and has launched cross-class products (crime/specie/extortion). They’re also active in APAC via Lloyd’s Asia and have public case studies on large Asian capacity deployments. Canopius+3Canopius+3Canopius+3
Best For: APAC custodians, global platforms seeking single-carrier leadership.
Notable Features:
- Digital-asset custody product on Lloyd’s Asia. Canopius
- Cross-class protection with extortion elements. Canopius
- Demonstrated large committed capacity in Hong Kong. Canopius
Consider If: You want a lead carrier with APAC presence.
Alternatives: Lloyd’s Market, Evertas.
Regions: Global/APAC.
8. Relm Insurance — Best Specialty Carrier for Digital-Asset Businesses
Why Use It: Bermuda-based Relm focuses on emerging industries including digital assets, offering tailored specialty programs and partnering with web3 security firms. Useful for innovative custody models needing bespoke underwriting. Relm Insurance+2Relm Insurance+2
Best For: Web3 platforms, custodians with non-standard architectures.
Notable Features:
- Digital-asset specific coverage and insights. Relm Insurance
- Partnerships with cyber threat-intel providers. Relm Insurance
- Bermuda specialty flexibility for novel risks. Relm Insurance
Consider If: You need bespoke terms for unique custody stacks.
Alternatives: Evertas, Canopius.
Regions: Global (Bermuda-domiciled).
9. Breach Insurance — Best for Exchange/Platform Embedded Coverage
Why Use It: Breach builds regulated crypto insurance products like Crypto Shield for platforms and investors, and offers institutional “Crypto Shield Pro” and platform-embedded options—useful for exchanges and custodians seeking retail-facing coverage. breachinsured.com+3breachinsured.com+3breachinsured.com+3
Best For: Exchanges, retail platforms, SMB crypto companies.
Notable Features:
- Regulated products targeting custody at qualified venues. breachinsured.com
- Institutional policy options (Pro). breachinsured.com
- Wallet risk assessments to prep for underwriting. breachinsured.com
Consider If: You want customer-facing protection aligned to your stack.
Alternatives: Coincover, Aon.
Regions: US/Global.
10. Chainproof — Best Add-On for Smart-Contract/Slashing Risks
Why Use It: While not a custody crime policy, Chainproof (incubated by Quantstamp; reinsured backing) offers regulated insurance for smart contracts and slashing—valuable as an adjunct when custodians support staking or programmatic flows tied to custody. Chainproof+2Chainproof+2
Best For: Custodians/exchanges with staking, DeFi integrations, or on-chain workflows.
Notable Features:
- Regulated smart-contract and slashing insurance. Chainproof+1
- Backing and provenance via Quantstamp ecosystem. quantstamp.com
- Bermuda regulatory progress noted in 2024-25. bma.bm
Consider If: You need to cover the on-chain leg alongside custody.
Alternatives: Munich Re (staking), Marsh.
Regions: Global.
Decision Guide: Best By Use Case
- Regulated U.S. programs & towers: Marsh, Aon, Lloyd’s Market. Marsh+2Aon+2
- Crypto-native underwriting: Evertas. evertas.com
- APAC leadership capacity: Canopius (Lloyd’s Asia). Canopius
- Embedded protection/wallet recovery: Coincover. coincover.com
- Reinsurance strength for large towers: Munich Re. Munich Re
- Retail/platform-facing add-ons: Breach Insurance. breachinsured.com
- On-chain/Slashing riders: Chainproof. Chainproof
- Specialty/innovative risk placements: Relm Insurance. Relm Insurance
How to Choose the Right Custody Insurance (Checklist)
- Confirm eligible regions/regulators (US/EU/APAC) and your entity domicile.
- Map storage tiers (cold/warm/hot/MPC) to coverage and sub-limits.
- Validate wordings/exclusions (internal theft, collusion, social engineering, vendor breaches).
- Align limits/deductibles with AUM, TVL, and worst-case loss scenarios.
- Ask for claims playbooks and incident response timelines.
- Review audits & controls (SOC 2, key ceremonies, disaster recovery).
- Query reinsurance backing and panel stability.
- Red flags: vague wordings; “cyber-only” policies for custody crime; no clarity on key compromise.
Use Token Metrics With Any Custody Insurance Provider
AI Ratings to vet venues and counterparties you work with.
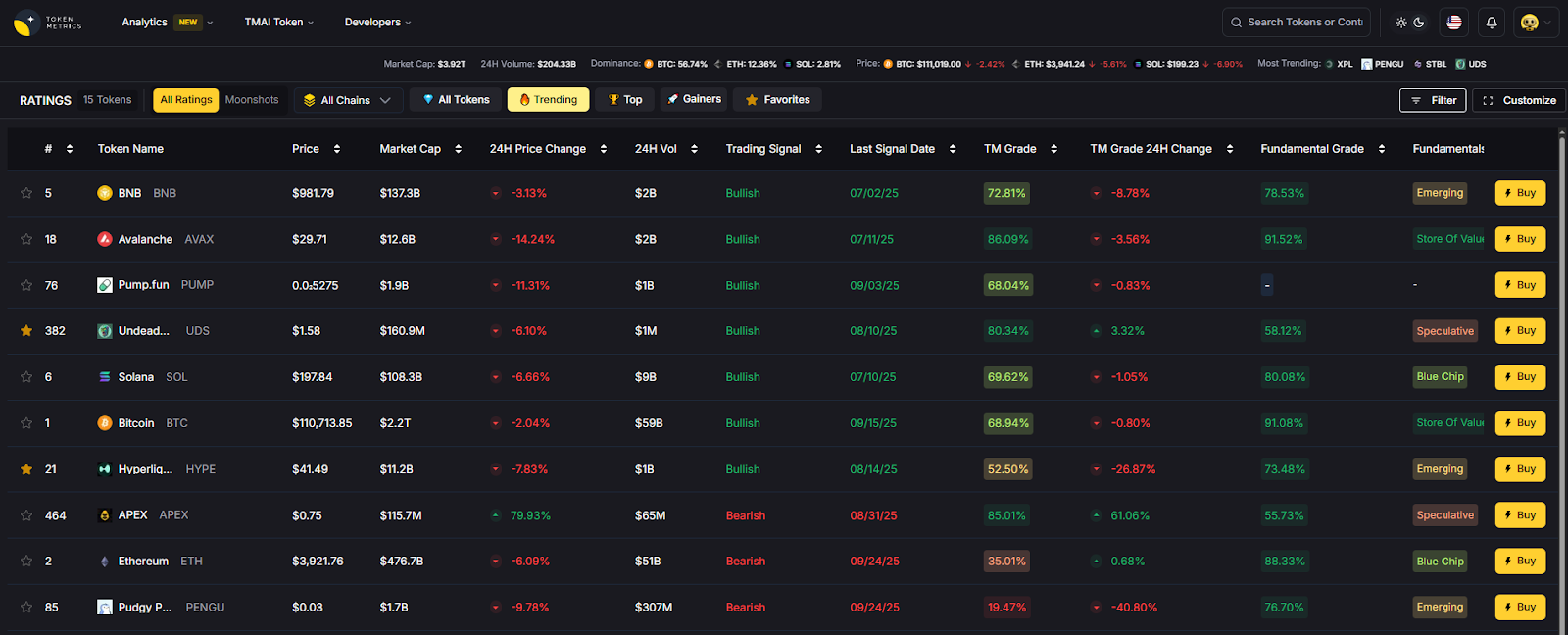
Narrative Detection to identify risk-on/off regimes impacting exposure.
Portfolio Optimization to size custody-related strategies.
Alerts/Signals to monitor market stress that could correlate with loss events.
Workflow: Research → Select provider via broker → Bind coverage → Operate and monitor with Token Metrics alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enforce MPC/hardware-isolated keys and dual-control operations.
- Use 2FA, withdrawal whitelists, and policy controls across org accounts.
- Keep KYC/AML and sanctions screening current for counterparties.
- Practice RFQ segregation and least-privilege for ops staff.
- Run tabletop exercises for incident/claims readiness.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Assuming cyber insurance = custody crime coverage.
- Buying limits that don’t match hot-wallet exposure.
- Skipping vendor-risk riders for sub-custodians and wallet providers.
- Not documenting key ceremonies and access policies.
- Waiting until after an incident to engage a broker/insurer.
FAQs
What does crypto custody insurance cover?
Typically theft, key compromise, insider fraud, and sometimes extortion or vendor breaches under defined conditions. Coverage varies widely by wording; verify hot/warm/cold definitions and exclusions. Munich Re
Do I need both crime and specie?
Crime commonly addresses employee dishonesty and external theft; specie focuses on physical loss/damage to assets in secure storage. Many carriers blend elements for digital assets—ask how your program handles each. Canopius
Can staking be insured?
Yes—some reinsurers/insurers offer staking/slashing riders or separate policies; smart-contract risk often requires additional cover like Chainproof. Munich Re+1
How much capacity is available?
Depends on controls and market appetite. Lloyd’s syndicates and reinsurers like Munich Re can support sizable towers when risk controls are strong. Lloyds+1
How do I reduce premiums?
Improve key-management controls, segregate duties, minimize hot exposure, complete independent audits, and adopt continuous monitoring/fraud screening (e.g., Coincover-style prevention). coincover.com
Are exchanges’ “insured” claims enough?
Not always—check if coverage is platform-wide, per-customer, warranty-backed, or contingent. Ask for wordings, limits, and who the named insureds are. The Digital Asset Infrastructure Company
Conclusion + Related Reads
If you need a crypto-first insurer, start with Evertas. Building a global tower? Engage Marsh or Aon across the Lloyd’s Market and reinsurers like Munich Re. For APAC-localized capacity, consider Canopius; for embedded protection, weigh Coincover or Breach. Add Chainproof if staking/DeFi exposure touches custody workflows.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
Sources & Update Notes
We reviewed official product/security pages, market announcements, and carrier/broker practice pages. We avoided third-party blogs for claims and linked only to official sites for verification. Updated September 2025; we’ll re-screen capacity and regional eligibility quarterly.
- Evertas — Insurance pages; “What is Crypto Insurance?”. evertas.com+1
- Coincover — Product pages; Lloyd’s press release on wallet policy. coincover.com+1
- Marsh — DART practice; digital-asset theft solution. Marsh+1
- Aon — Digital-asset practice and custody assessments. Aon+1
- Munich Re — Digital Asset Comprehensive Crime/Staking/Smart-contract. Munich Re
- Lloyd’s — Market directory; wallet insurance announcement. Lloyds+1
- Canopius — Crypto custody product; Lloyd’s Asia launch; APAC capacity news. Canopius+2Canopius+2
- Relm Insurance — Digital-asset specialty pages and insights. Relm Insurance+1
- Breach Insurance — Product pages (Crypto Shield, Pro, assessments). breachinsured.com+2breachinsured.com+2
- Chainproof — Regulated smart-contract/slashing insurance; Quantstamp provenance; Bermuda regulator notes. Chainproof+2quantstamp.com+2
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.