



Best Insurance Protocols (DeFi & Custodial) 2025
%201.svg)
%201.svg)

Why Crypto Insurance Matters in September 2025
The search intent here is commercial investigation: investors want safe ways to protect on-chain and custodied assets. This guide ranks the best insurance protocols 2025 across DeFi and regulated custodial coverage so you can compare options quickly.
Definition: Crypto (DeFi) insurance helps cover losses from smart-contract exploits, exchange halts, custodian breaches, or specific parametric events; custodial insurance typically protects assets held by qualified trustees or platforms under defined “crime”/theft policies.
In 2025, larger treasuries and yield strategies are back, while counterparty and contract risk remain. We focus on real cover products, payout track records, and regulated custodial policies—using only official sources. Secondary considerations include DeFi insurance, crypto custodial insurance, and smart contract coverage capacity, claims handling, and regional eligibility.
How We Picked (Methodology & Scoring)
- Liquidity (30%): size/capacity, ability to pay valid claims; for custodians, insurance limits and capital backing.
- Security (25%): audits, disclosures, claim processes, regulated status where applicable.
- Coverage (15%): breadth of products (protocol, depeg, custody, parametric, etc.) and supported chains.
- Costs (15%): premiums/fees relative to cover; clear fee pages.
- UX (10%): buying experience, documentation, transparency.
- Support (5%): documentation, response channels, claims guidance.
Data sources: official product/docs, transparency/security pages, and audited/claims pages; market datasets only for cross-checks. Last updated September 2025.
Top 10 Crypto Insurance Providers in September 2025
1. Nexus Mutual — Best for broad DeFi coverage and claims history

- Why Use It: A member-owned mutual offering protocol, exchange halt, and depeg covers, with a transparent claims ledger and multi-year payout track record. Members vote on claims, and the docs detail cover wordings and product types. docs.nexusmutual.io+3nexusmutual.io+3docs.nexusmutual.io+3
- Best For: Advanced DeFi users, DAOs/treasuries, funds seeking bespoke on-chain risk cover.
- Notable Features: Claims history ledger; multiple cover products (protocol/exchange/depeg); membership + staking model. Nexus Mutual DAO+1
- Fees Notes: Membership fee required; premiums vary by product pool (see cover pages). docs.nexusmutual.io
- Regions: Global (KYC for membership). docs.nexusmutual.io
- Consider If: You’re comfortable with discretionary, member-voted claims.
- Alternatives: InsurAce, Neptune Mutual.
2. InsurAce — Best multi-chain DeFi marketplace
- Why Use It: Multi-chain cover marketplace with a wide menu of protocol/exchange risk options and an established brand. Useful for builders and users who want flexible terms across ecosystems. insurace.io
- Best For: Multi-chain DeFi participants, LPs, power users.
- Notable Features: Diverse cover catalog; staking/supply side; docs and dApp UI focused on ease of purchase. insurace.io
- Fees Notes: Premiums vary per pool/cover; check dApp quotes.
- Regions: Global (subject to app access and eligibility).
- Consider If: You prefer marketplace variety but can evaluate pool capacity.
- Alternatives: Nexus Mutual, Neptune Mutual.
4. Sherlock — Best for protocol teams needing post-audit coverage
- Why Use It: Full-stack security provider (audit contests, bounties) with Sherlock Shield coverage that helps protocols mitigate losses from smart-contract exploits. Strong fit for teams bundling audits + coverage. sherlock.xyz+1
- Best For: Protocol founders, security-first teams, DAOs.
- Notable Features: Audit marketplace; exploit coverage; payout process tailored for teams. sherlock.xyz
- Fees Notes: Pricing depends on scope/coverage; engage sales.
- Regions: Global.
- Consider If: You need coverage tightly integrated with audits.
- Alternatives: Chainproof, Nexus Mutual.
3. OpenCover— Best for Community-Driven, Transparent Coverage
Why Use It: OpenCover is a decentralized insurance protocol that leverages community-driven liquidity pools to offer coverage against smart contract exploits and other on-chain risks. Its transparent claims process and low-cost structure make it an attractive option for DeFi users seeking affordable and reliable insurance solutions.
Best For: DeFi users, liquidity providers, and investors looking for community-backed insurance coverage.
Notable Features:
- Community-governed liquidity pools
- Transparent and automated claims process
- Low-cost premiums
- Coverage for smart contract exploits and on-chain risks
Fees/Notes: Premiums are determined by the liquidity pool and the level of coverage selected.
Regions: Global (subject to dApp access).
Consider If: You value community governance and transparency in your insurance coverage.
Alternatives: Nexus Mutual, InsurAce.
5. Chainproof — Best for regulated smart-contract insurance
- Why Use It: A regulated insurer for non-custodial smart contracts, incubated by Quantstamp; positions itself with compliant, underwritten policies and 24/7 monitoring. chainproof.co+2quantstamp.com+2
- Best For: Enterprises, institutions, and larger protocols requiring regulated policies.
- Notable Features: Regulated insurance; Quantstamp lineage; monitoring-driven risk management. quantstamp.com+1
- Fees Notes: Premiums/policy terms bespoke.
- Regions: Global (subject to policy jurisdiction).
- Consider If: You need compliance-grade coverage for stakeholders.
- Alternatives: Sherlock, Nexus Mutual.
6. Nayms — Best on-chain insurance marketplace for brokers/carriers
- Why Use It: A regulated (Bermuda DABA Class F) marketplace to set up tokenized insurance pools and connect brokers, carriers, investors, and insureds—bringing alternative capital on-chain. nayms.com+1
- Best For: Brokers/carriers building crypto-native insurance programs; larger DAOs/TSPs.
- Notable Features: Segregated Accounts (SAC) structure; tokenized pools; full lifecycle (capital → premiums → claims). nayms.com+1
- Fees Notes: Platform/program fees vary; institutional setup.
- Regions: Global (Bermuda framework).
- Consider If: You’re creating—not just buying—insurance capacity.
- Alternatives: Chainproof, institutional mutuals.
7. Etherisc — Best for parametric flight/crop and specialty covers
- Why Use It: Pioneer in parametric blockchain insurance with live Flight Delay Protection and other modules (e.g., crop, weather, depeg). On-chain products with automated claims. Etherisc+2Flight Delay+2
- Best For: Travelers, agritech projects, builders of niche parametric covers.
- Notable Features: Flight delay dApp (Base/USDC); crop/weather modules; transparent policy pages. Flight Delay+1
- Fees Notes: Premiums quoted per route/peril.
- Regions: Global (product-specific availability).
- Consider If: You need clear, data-triggered payouts.
- Alternatives: Arbol (climate parametrics), Neptune Mutual.
8. Tidal Finance — Best for Coverage on Niche DeFi Protocols
Why Use It: Tidal Finance focuses on providing coverage for niche and emerging DeFi protocols, offering tailored insurance products for new and innovative projects. Tidal's dynamic risk assessments allow it to offer specialized coverage options for specific protocols.
Best For: Users and protocols seeking insurance for niche DeFi projects with specific risk profiles.
Notable Features:
- Coverage for high-risk, niche DeFi protocols
- Dynamic pricing based on real-time risk assessments
- Flexible policy terms
Fees/Notes: Premiums based on the risk profile of the insured protocol.
Regions: Global.
Consider If: You need tailored insurance coverage for emerging or specialized DeFi projects.
Alternatives: Nexus Mutual, Amulet Protocol.
9. Subsea (formerly Risk Harbor) — Best for automated, rules-based claims
- Why Use It: An algorithmic risk-management marketplace with objective, automated claims—reducing discretion and bias in payouts. (Risk Harbor rebranded to Subsea.) Subsea+1
- Best For: Users who prefer invariant, programmatic claim triggers.
- Notable Features: Automated payout logic; transparent market mechanics; simulator for underwriting/buying protection. simulator.riskharbor.com
- Fees Notes: Premiums and returns vary by pool.
- Regions: Global (dApp access).
- Consider If: You want automation over DAO voting.
- Alternatives: Neptune Mutual, Amulet.
10. BitGo Custody (with Insurance) — Best custodial coverage for institutions
- Why Use It: Qualified custody with up to $250M in digital-asset insurance capacity for assets where keys are held by BitGo Trust; clearly communicated policy framework and bankruptcy-remote structures. The Digital Asset Infrastructure Company+2The Digital Asset Infrastructure Company+2
- Best For: Funds, corporates, and service providers needing regulated custody plus insurance.
- Notable Features: Qualified custody; SOC reports; policy covers specific theft/loss scenarios. The Digital Asset Infrastructure Company
- Fees Notes: Custody/asset-based fees; insurance embedded at the custodian level.
- Regions: Global (jurisdiction-specific entities).
- Consider If: You want a regulated custodian with published insurance capacity.
- Alternatives: Gemini Custody, Anchorage Digital (note: no FDIC/SIPC). Gemini+1
Decision Guide: Best By Use Case
- Largest DeFi product breadth: Nexus Mutual, InsurAce. nexusmutual.io+1
- Fastest/parametric claims: Neptune Mutual, Etherisc. neptunemutual.com+1
- Regulated policy needs (enterprise): Chainproof, Nayms. chainproof.co+1
- Solana-first portfolios: Amulet. amulet.org
- Fully automated claims (no governance): Subsea (ex-Risk Harbor). Subsea
- Custodial with published insurance limits: BitGo; also Gemini Custody (hot+cold coverage). The Digital Asset Infrastructure Company+1
How to Choose the Right Crypto Insurance (Checklist)
- Verify eligibility/region and any KYC requirements.
- Check coverage type (protocol exploit, exchange halt, depeg, parametric, custody crime).
- Review capacity/liquidity and payout records/ledgers.
- Compare premiums/fees against insured amounts and deductibles.
- Evaluate claims process (discretionary vote vs. parametric/automated).
- Confirm security posture (audits, monitoring, disclosures).
- Test UX & support (docs, ticketing, community).
- Red flags: unclear policy wordings; promises of “FDIC-like” protection for crypto (rare/not applicable). Anchorage
Use Token Metrics With Any Insurance Provider
- AI Ratings to screen tokens and protocol risk signals.
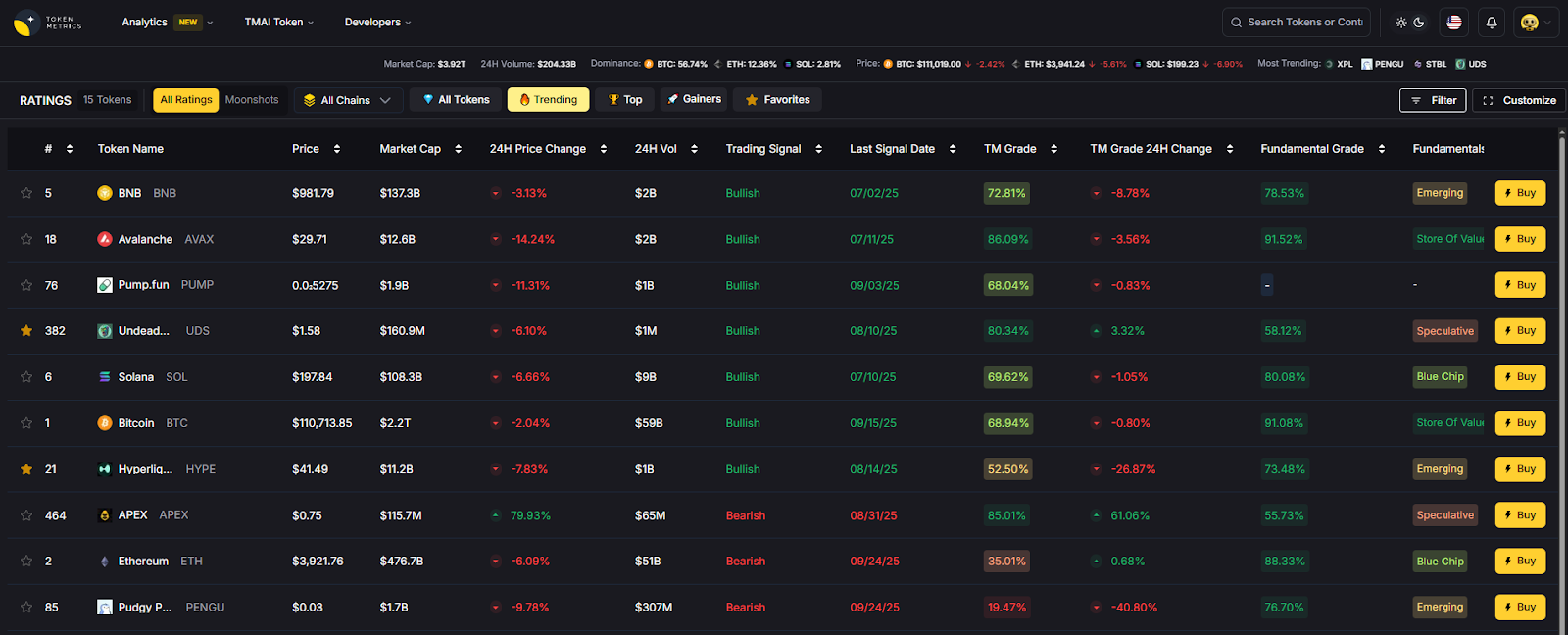
- Narrative Detection to spot shifting risk/coverage demand.
- Portfolio Optimization to size insured vs. uninsured exposures.
- Alerts to track incident news and coverage expiries.
Workflow: Research → Select cover/custody → Execute → Monitor with alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enable strong 2FA and segregate wallets for covered vs. uncovered positions.
- For custodial solutions, understand exact insurance scope and exclusions. Gemini
- Follow KYC/AML where required (e.g., Nexus Mutual membership). docs.nexusmutual.io
- For protocols, complement insurance with audits/bounties and incident response runbooks. sherlock.xyz
- Maintain wallet hygiene (hardware, allow-list, spend limits).
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Assuming all losses are covered—read policy wordings. Gemini
- Buying cover after an incident is known/underway.
- Ignoring chain/app coverage constraints.
- Letting cover lapse during major upgrades or liquidity migrations.
- Believing custodial insurance = FDIC/SIPC (it doesn’t). Anchorage
FAQs
What’s the difference between DeFi insurance and custodial insurance?
DeFi insurance protects on-chain actions (e.g., smart-contract exploits or depegs), often via discretionary voting or parametric rules. Custodial insurance covers specific theft/loss events while assets are held by a qualified custodian under a crime policy; exclusions apply. docs.nexusmutual.io+1
How do parametric policies work in crypto?
They pre-define an objective trigger (e.g., flight delay, protocol incident), enabling faster, data-driven payouts without lengthy investigations. Etherisc (flight) and Neptune Mutual (incident pools) are examples. Flight Delay+1
Is Nexus Mutual regulated insurance?
No. It’s a member-owned discretionary mutual where members assess claims and provide capacity; see membership docs and claim pages. docs.nexusmutual.io+1
Do custodial policies cover user mistakes or account takeovers?
Typically no—policies focus on theft from the custodian’s systems. Review each custodian’s definitions/exclusions (e.g., Gemini’s hot/cold policy scope). Gemini
What if I’m primarily on Solana?
Consider Amulet for Solana-native cover; otherwise, verify cross-chain support from multi-chain providers. amulet.org
Which providers are regulated?
Chainproof offers regulated smart-contract insurance; Nayms operates under Bermuda’s DABA framework for on-chain insurance programs. chainproof.co+1
Conclusion + Related Reads
If you need breadth and track record, start with Nexus Mutual or InsurAce. For parametric, faster payouts, look at Neptune Mutual or Etherisc. Building institutional-grade risk programs? Consider Chainproof or Nayms. If you hold assets with a custodian, confirm published insurance capacity—BitGo and Gemini Custody are good benchmarks.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
Sources & Update Notes
We verified every claim on official provider pages (product docs, policy pages, security/claims posts) and only used third-party sources for context checks. Updated September 2025.
- Nexus Mutual — Site, Cover Products, Claim Assessment, Claim History blog/pages. Nexus Mutual DAO+3nexusmutual.io+3docs.nexusmutual.io+3
- InsurAce — Official site. insurace.io
- Neptune Mutual — Docs (cover types), blog (parametric guide). neptunemutual.com+1
- Sherlock — Site, Sherlock Shield page. sherlock.xyz+1
- Chainproof — Official site, Quantstamp announcement. chainproof.co+1
- Nayms — About (SAC/DABA), Platform pages. nayms.com+1
- Etherisc — Main site, Flight Delay app/policies, Buy page. Etherisc+3Etherisc+3Flight Delay+3
- Amulet — Site, V1 docs/buy cover, V3 docs post. amulet.org+2amulet.org+2
- Subsea (ex-Risk Harbor) — Site; Risk Harbor simulator (for mechanism reference). Subsea+1
- BitGo — Insurance pages/blog; main site (qualified custody, $250M). The Digital Asset Infrastructure Company+2Official BitGo Blog+2
Gemini — Custody insurance page and blog. Gemini+1
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.