



Leading Oracles for Price & Real-World Data (2025)
%201.svg)
%201.svg)

Why Oracles for Price & Real-World Data Matter in September 2025
DeFi, onchain derivatives, RWAs, and payments don’t work without reliable oracles for price & real-world data. In 2025, latency, coverage, and security disclosures vary widely across providers, and the right fit depends on your chain, assets, and risk tolerance. This guide helps teams compare the leading networks (and their trade-offs) to pick the best match, fast.
Definition (snippet-ready): A blockchain oracle is infrastructure that sources, verifies, and delivers off-chain data (e.g., prices, FX, commodities, proofs) to smart contracts on-chain.
We prioritized depth over hype: first-party data, aggregation design, verification models (push/pull/optimistic), and RWA readiness. Secondary focus: developer UX, fees, supported chains, and transparency. If you’re building lending, perps, stablecoins, options, prediction markets, or RWA protocols, this is for you.
How We Picked (Methodology & Scoring)
- Weights (100 pts): Liquidity/usage (30), Security design & disclosures (25), Coverage across assets/chains (15), Costs & pricing model (15), Developer UX/tooling (10), Support/SLAs (5).
- Data sources: Official product/docs, security/transparency pages, and audited reports. We cross-checked claims against widely cited market datasets where helpful. No third-party links appear in the body.
Last updated September 2025.
Top 10 Oracles for Price & Real-World Data in September 2025
1. Chainlink — Best for broad coverage & enterprise-grade security

Why Use It: The most battle-tested network with mature Price/Data Feeds, Proof of Reserve, and CCIP for cross-chain messaging. Strong disclosures and large validator/operator sets make it a default for blue-chip DeFi and stablecoins. docs.switchboard.xyz
Best For: Lending/stablecoins, large TVL protocols, institutions.
Notable Features:
- Price/Data Feeds and reference contracts
- Proof of Reserve for collateral verification
- CCIP for cross-chain token/data movement
- Functions/Automation for custom logic
Fees/Notes: Network/usage-based (LINK or billing models; varies by chain).
Regions: Global.
Alternatives: Pyth, RedStone.
Consider If: You need the most integrations and disclosures, even if costs may be higher. GitHub
2. Pyth Network — Best for real-time, low-latency prices

Why Use It: First-party publishers stream real-time prices across crypto, equities, FX, and more to 100+ chains. Pyth’s on-demand “pull” update model lets dApps request fresh prices only when needed—great for latency-sensitive perps/AMMs. Pyth Network
Best For: Perps/options DEXs, HFT-style strategies, multi-chain apps.
Notable Features:
- Broad market coverage (crypto, equities, FX, commodities)
- On-demand price updates to minimize stale reads
- Extensive multi-chain delivery and SDKs Pyth Network
Fees/Notes: Pay per update/read model varies by chain.
Regions: Global.
Alternatives: Chainlink, Switchboard.
Consider If: You want frequent, precise updates where timing matters most. Pyth Network
3. API3 — Best for first-party (direct-from-API) data

Why Use It: Airnode lets API providers run their own first-party oracles; dAPIs aggregate first-party data on-chain. OEV (Oracle Extractable Value) routes update rights to searchers and shares proceeds with the dApp—aligning incentives around updates. docs.api3.org+1
Best For: Teams that prefer direct data provenance and revenue-sharing from oracle updates.
Notable Features:
- Airnode (serverless) first-party oracles
- dAPIs (crypto, stocks, commodities)
- OEV Network to auction update rights; API3 Market for subscriptions docs.kava.io
Fees/Notes: Subscription via API3 Market; chain-specific gas.
Regions: Global.
Alternatives: Chainlink, DIA.
Consider If: You need verifiable source relationships and simple subscription UX. docs.kava.io
4. RedStone Oracles — Best for modular feeds & custom integrations
Why Use It: Developer-friendly, modular oracles with Pull, Push, and Hybrid (ERC-7412) modes. RedStone attaches signed data to transactions for gas-efficient delivery and supports custom connectors for long-tail assets and DeFi-specific needs.
Best For: Builders needing custom data models, niche assets, or gas-optimized delivery.
Notable Features:
- Three delivery modes (Pull/Push/Hybrid)
- Data attached to calldata; verifiable signatures
- EVM tooling, connectors, and RWA-ready feeds
Fees/Notes: Pay-as-you-use patterns; gas + operator economics vary.
Regions: Global.
Alternatives: API3, Tellor.
Consider If: You want flexibility beyond fixed reference feeds.
5. Band Protocol — Best for Cosmos & EVM cross-ecosystem delivery
Why Use It: Built on BandChain (Cosmos SDK), Band routes oracle requests to validators running Oracle Scripts (OWASM), then relays results to EVM/Cosmos chains. Good match if you straddle IBC and EVM worlds. docs.bandchain.org+2docs.bandchain.org+2
Best For: Cross-ecosystem apps (Cosmos↔EVM), devs who like programmable oracle scripts.
Notable Features:
- Oracle Scripts (OWASM) for composable requests
- Request-based feeds; IBC compatibility
- Libraries and examples across chains docs.bandchain.org
Fees/Notes: Gas/fees on BandChain + destination chain.
Regions: Global.
Alternatives: Chainlink, Switchboard.
Consider If: You want programmable queries and Cosmos-native alignment. docs.bandchain.org
6. DIA — Best for bespoke feeds & transparent sourcing
Why Use It: Trustless architecture that sources trade-level data directly from origin markets (CEXs/DEXs) with transparent methodologies. Strong for custom asset sets, NFTs, LSTs, and RWA feeds across 60+ chains. DIA+1
Best For: Teams needing bespoke baskets, niche tokens/NFTs, or RWA price inputs.
Notable Features:
- Two stacks (Lumina & Nexus), push/pull options
- Verifiable randomness and fair-value feeds
- Open-source components; broad chain coverage DIA
Fees/Notes: Custom deployments; some public feeds/APIs free tiers.
Regions: Global.
Alternatives: API3, RedStone.
Consider If: You want full transparency into sources and methods. DIA
7. Flare Networks — Best for real-world asset tokenization and decentralized data
Why Use It: Flare uses the Avalanche consensus to provide decentralized oracles for real-world assets (RWAs), enabling the tokenization of non-crypto assets like commodities and stocks. It combines high throughput with flexible, trustless data feeds, making it ideal for bridging real-world data into DeFi applications.
Best For: Asset-backed tokens, DeFi protocols integrating RWAs, cross-chain compatibility.
Notable Features:
- Advanced decentralized oracle network for real-world data
- Tokenization of commodities, stocks, and other RWAs
- Multi-chain support with integration into the Flare network
- High throughput with minimal latency
Fees/Notes: Variable costs based on usage and asset complexity.
Regions: Global.
Alternatives: Chainlink, DIA, RedStone.
Consider If: You want to integrate real-world assets into your DeFi protocols and need a robust, decentralized solution.
8. UMA — Best for optimistic verification & oracle-as-a-service
Why Use It: The Optimistic Oracle (OO) secures data by proposing values that can be disputed within a window—powerful for binary outcomes, KPIs, synthetic assets, and bespoke data where off-chain truth exists but doesn’t stream constantly. Bybit Learn
Best For: Prediction/insurance markets, bespoke RWAs, KPI options, governance triggers.
Notable Features:
- OO v3 with flexible assertions
- Any verifiable fact; not just prices
- Dispute-based cryptoeconomic security Bybit Learn
Fees/Notes: Proposer/disputer incentives; bond economics vary by use.
Regions: Global.
Alternatives: Tellor, Chainlink Functions.
Consider If: Your use case needs human-verifiable truths more than tick-by-tick quotes. Bybit Learn
9. Chronicle Protocol — Best for MakerDAO alignment & cost-efficient updates
Why Use It: Originated in the Maker ecosystem and now a standalone oracle network with Scribe for gas-efficient updates and transparent validator set (Infura, Etherscan, Gnosis, etc.). Strong choice if you touch DAI, Spark, or Maker-aligned RWAs. Chronicle Protocol
Best For: Stablecoins, RWA lenders, Maker-aligned protocols needing verifiable feeds.
Notable Features:
- Scribe reduces L1/L2 oracle gas costs
- Community-powered validator network
- Dashboard for data lineage & proofs Chronicle Protocol
Fees/Notes: Network usage; gas savings via Scribe.
Regions: Global.
Alternatives: Chainlink, DIA.
Consider If: You want Maker-grade security and cost efficiency. Chronicle Protocol
10. Switchboard — Best for Solana & multi-chain custom feeds
Why Use It: A multi-chain, permissionless oracle popular on Solana with Drag-and-Drop Feed Builder, TEEs, VRF, and new Oracle Quotes/Surge for sub-100ms streaming plus low-overhead on-chain reads—ideal for high-speed DeFi. docs.switchboard.xyz+1
Best For: Solana/SVM dApps, custom feeds, real-time dashboards, gaming.
Notable Features:
- Low-code feed builder & TypeScript tooling
- Oracle Quotes (no feed accounts/no write locks)
- Surge streaming (<100ms) and cross-ecosystem docs docs.switchboard.xyz
Fees/Notes: Some features free at launch; usage limits apply.
Regions: Global.
Alternatives: Pyth, Band Protocol.
Consider If: You want speed and customization on SVM/EVM alike. docs.switchboard.xyz+1
Decision Guide: Best By Use Case
- Regulated/Institutional & broad integrations: Chainlink.
- Ultra-low-latency trading: Pyth or Switchboard (Surge/Quotes). Pyth Network+1
- Custom, gas-efficient EVM delivery: RedStone.
- First-party sources & subscription UX: API3 (Airnode + dAPIs + OEV). docs.kava.io
- Cosmos + EVM bridge use: Band Protocol. docs.bandchain.org
- Bespoke feeds/NFTs/RWAs with transparent sources: DIA. DIA
- Permissionless, long-tail assets: Tellor. docs.kava.io
- Optimistic, assertion-based facts: UMA. Bybit Learn
- Maker/DAI alignment & gas savings: Chronicle Protocol. Chronicle Protocol
How to Choose the Right Oracle (Checklist)
- Region & chain support: Verify your target chains and L2s are supported.
- Coverage: Are your assets (incl. long-tail/RWAs) covered, or can you request custom feeds?
- Security model: Push vs. pull vs. optimistic; validator set transparency; dispute process.
- Costs: Update fees, subscriptions, gas impact; consider pull models for usage spikes.
- Latency & freshness: Can you control update cadence? Any SLAs/heartbeats?
- UX & tooling: SDKs, dashboards, error handling, testing sandboxes.
- Support & disclosures: Incident reports, status pages, proofs.
- Red flags: Opaque sourcing, no dispute/alerting, stale feeds, unclear operators.
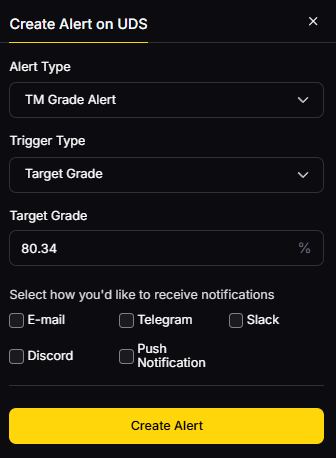
Use Token Metrics With Any Oracle
- AI Ratings to triage providers and prioritize integrations.
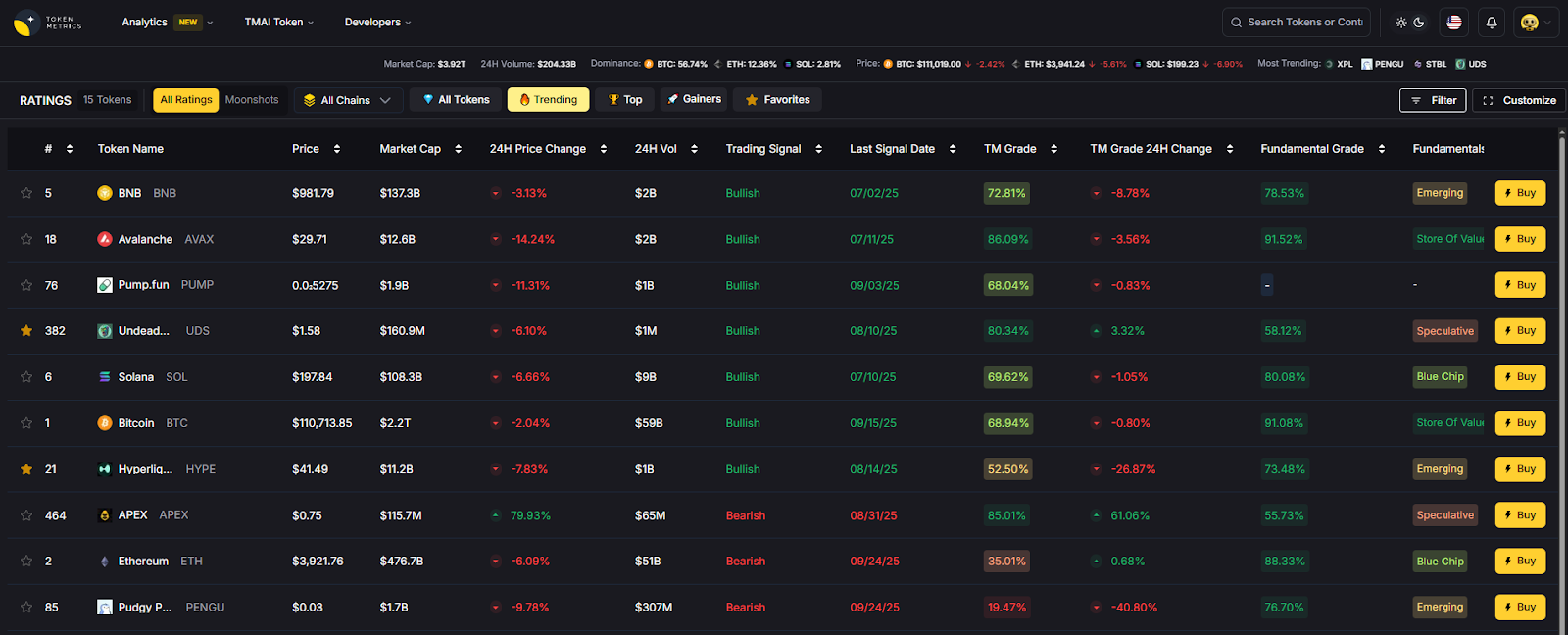
- Narrative Detection to spot momentum in perps/lending sectors powered by oracles.
- Portfolio Optimization to size positions by oracle risk and market beta.
- Alerts/Signals to monitor price triggers and on-chain flows.
Workflow: Research → Select → Execute on your chosen oracle/provider → Monitor with TM alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enforce 2FA and least-privilege on deployer keys; rotate API/market credentials.
- Validate feed params (deviation/heartbeat) and fallback logic; add circuit breakers.
- Document chain-specific KYC/AML implications if your app touches fiat/RWAs.
- For RFQs and custom feeds, formalize SLOs and alerting.
- Practice wallet hygiene: separate ops keys, testnets, and monitors.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Relying on a single feed without fallback or stale-price guards.
- Assuming all “price oracles” have identical latency/fees.
- Ignoring dispute windows (optimistic designs) before acting on values.
- Not budgeting for update costs when volatility spikes.
- Skipping post-deploy monitoring and anomaly alerts.
FAQs
What is a blockchain oracle in simple terms?
It’s middleware that fetches, verifies, and publishes off-chain data (e.g., prices, FX, commodities, proofs) to blockchains so smart contracts can react to real-world events.
Do I need push, pull, or optimistic feeds?
Push suits stable, shared reference prices; pull minimizes cost by updating only when needed; optimistic is great for facts that benefit from challenge periods (e.g., settlement outcomes). Pyth Network+1
Which oracle is best for low-latency perps?
Pyth and Switchboard (Surge/Quotes) emphasize real-time delivery; evaluate your chain and acceptable freshness. Pyth Network+1
How do fees work?
Models vary: subscriptions/markets (API3), per-update pull fees (Pyth), or gas + operator incentives (RedStone/Tellor). Always test under stress. docs.kava.io+2Pyth Network+2
Can I get RWA data?
Yes—Chainlink PoR, DIA RWA feeds, Chronicle for Maker-aligned assets, and others offer tailored integrations. Validate licensing and data provenance. docs.switchboard.xyz+2DIA+2
Conclusion + Related Reads
The “best” oracle depends on your chain, assets, latency needs, and budget. If you need broad coverage and disclosures, start with Chainlink. If you’re building latency-sensitive perps, test Pyth/Switchboard. For first-party provenance or custom baskets, look to API3, DIA, or RedStone. For long-tail, permissionless or bespoke truths, explore Tellor or UMA.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.