



Top On and Off-Ramp Providers (Fiat to Crypto) 2025
%201.svg)
%201.svg)

Why Fiat ↔ Crypto On/Off-Ramps Matter in September 2025
Getting money into and out of crypto should be fast, safe, and compliant. In 2025, wallets, dapps, exchanges, and fintechs increasingly rely on crypto on/off-ramp providers to convert fiat to tokens and cash back out to bank rails—all without forcing users to bounce between apps. Definition: an on-ramp lets users buy crypto with fiat; an off-ramp lets them sell crypto back to fiat and withdraw to bank accounts or cards. This guide is for product leaders, devs, and advanced users comparing coverage, fees, and risk controls across global options. We score providers on liquidity, security, asset/market coverage, costs, UX, and support, then recommend the best fits by use case. Secondary angles we considered: fiat to crypto onramp, crypto off-ramp, and common flows like “buy crypto with bank transfer.”
How We Picked (Methodology & Scoring)
- Liquidity (30%) – depth, uptime, and quote quality across assets/fiat rails.
- Security (25%) – audits, certifications, KYC/AML controls, trust center disclosures.
- Coverage (15%) – supported countries, payment methods, off-ramp payout rails.
- Costs (15%) – transparent fees/spreads; promos (e.g., USDC zero-fee tiers).
- UX (10%) – speed (KYC/settlement), embeddable widgets, developer docs.
- Support (5%) – docs, SLAs, live support, incident comms.
Data sources: official product/docs and security pages; licensing and disclosures; limited cross-checks with widely cited market datasets. We only link to official provider sites in this article. Last updated September 2025.
Top 10 Fiat ↔ Crypto On/Off-Ramp Providers in September 2025
1. Coinbase Onramp & Offramp — Best for USDC flows & regulated U.S./EU coverage
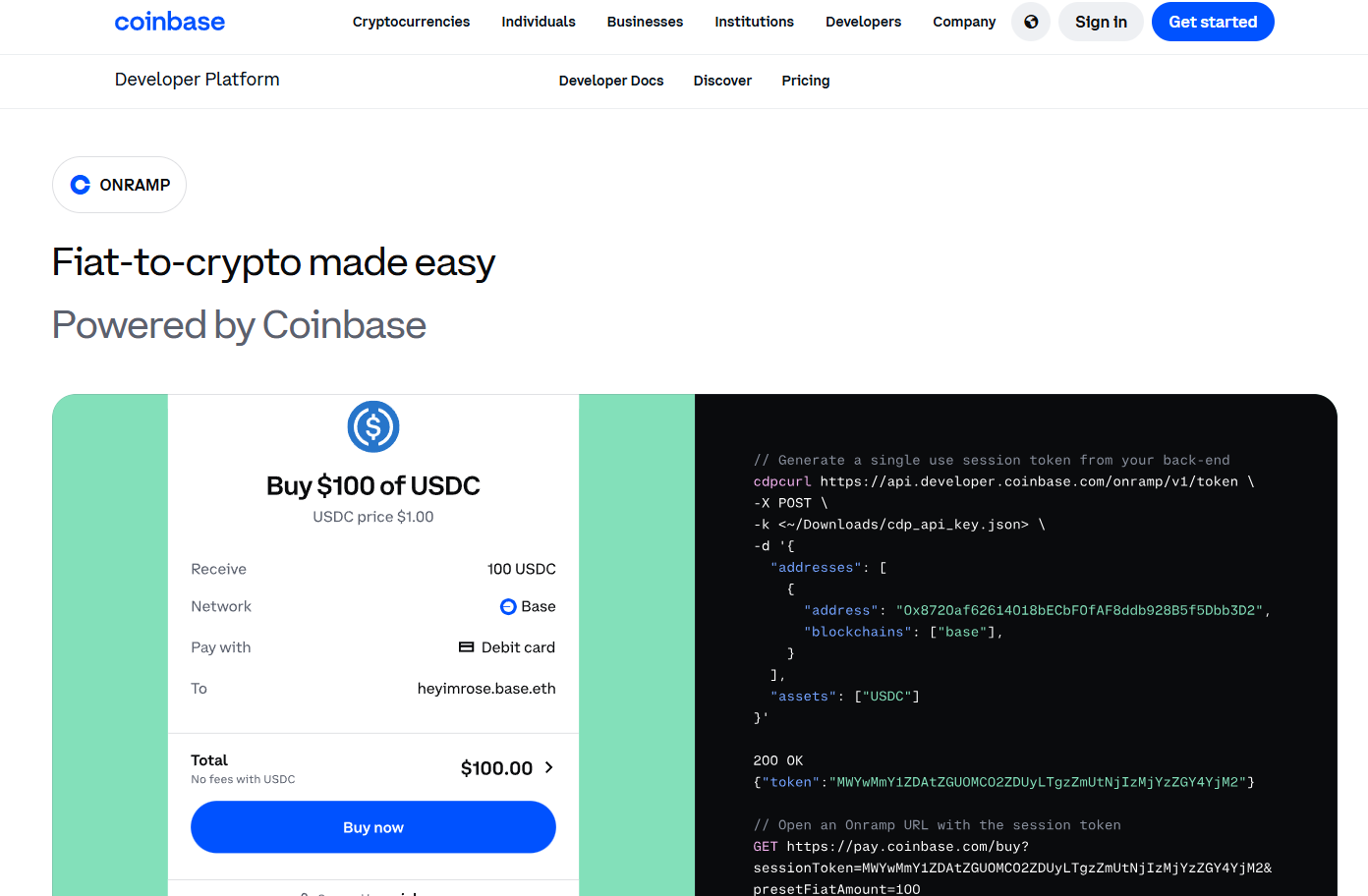
- Why Use It: Coinbase’s hosted Onramp and Offramp APIs let you embed buy/sell with bank rails and cards, including ACH cashouts, inside your app. Select apps can access zero-fee USDC onramp/offramp promotions and free USDC on Base. Coinbase+2Coinbase+2
- Best For: U.S./EU wallets & dapps, consumer fintechs, apps prioritizing compliance.
- Notable Features: hosted widgets; guest checkout for US (no account up to limits); ACH cashout; strong docs & SDKs. Coinbase Developer Docs
- Fees Notes: Standard fees vary by method; USDC promos may apply. Coinbase
- Regions: Global reach with strongest support in U.S./EU; method availability varies. Coinbase Developer Docs
- Consider If: You need a turnkey, regulated option with ACH off-ramp.
- Alternatives: MoonPay, Ramp Network.
2. MoonPay — Best for non-custodial UX & card coverage
- Why Use It: MoonPay offers fast card/Apple Pay/PayPal buys and a non-custodial off-ramp, letting users sell crypto while keeping control of keys. Good fit for wallets and NFT apps that want an embedded flow. MoonPay+1
- Best For: Self-custody wallets, NFT marketplaces, global card-first audiences.
- Notable Features: Onramp + off-ramp; non-custodial design; quick card settlement. MoonPay+1
- Fees Notes: Varies by payment method and region.
- Regions: Broad international availability; local method support varies.
- Consider If: You want non-custodial off-ramp with strong card acceptance.
- Alternatives: Transak, Banxa.
3. Ramp Network — Best for global coverage + fast KYC
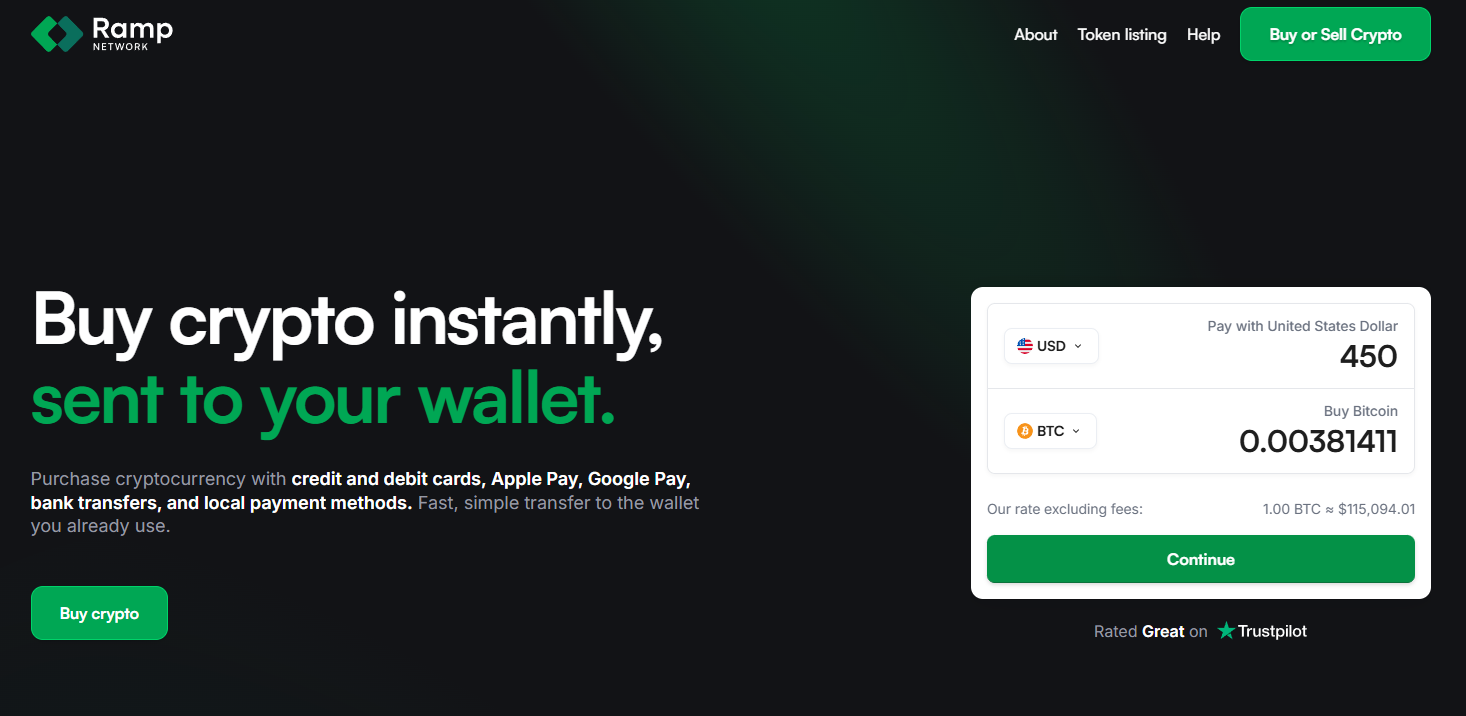
- Why Use It: Ramp supports 100+ assets and multiple local rails (cards, bank transfers, Pix, SPEI) with fast, document-free KYC in eligible markets and SOC/ISO certifications published via its Trust Center. rampnetwork.com+2ramp.network+2
- Best For: Wallets/dapps needing wide country coverage and quick onboarding.
- Notable Features: On & off-ramp; 100+ assets; local rails incl. Pix & SPEI payouts; strong security disclosures. ramp.network+1
- Fees Notes: Vary by method, asset, and geography.
- Regions: 150+ countries; some U.S. states support on-ramp only (no off-ramp). support.rampnetwork.com
- Consider If: You want breadth plus local rails in LATAM/EU.
- Alternatives: Transak, Alchemy Pay.
4. Transak — Best for developer tooling & hybrid use cases
- Why Use It: Transak offers on/off-ramp coverage (40+ off-ramp assets across 20+ networks) with over 64+ supported countries and Transak One to let users fund complex actions (e.g., stake/bridge) from fiat in one flow. Transak Docs+2Transak+2
- Best For: Developers needing a broad, configurable integration; DeFi apps.
- Notable Features: Off-ramp to bank; multi-network coverage; business (corporate) on/off-ramp; embeddable widgets. Transak+1
- Fees Notes: Vary by method; see widget quotes.
- Regions: 60+ countries; payment methods differ by market. Transak
- Consider If: You need both retail and corporate on/off-ramp options.
- Alternatives: Ramp Network, Banxa.
5. Banxa — Best for compliance-heavy enterprise & deep licensing
- Why Use It: Banxa emphasizes regulated operations with published USA MTL and global license lists, plus enterprise-grade AML/CTF and security disclosures. Strong for partners who need extensive compliance artifacts. Banxa+2Banxa+2
- Best For: Enterprises, wallets, and exchanges with strict compliance needs.
- Notable Features: On/off-ramp via API/widget; broad fiat/crypto support; license/AML pages; developer SDKs. Banxa+1
- Fees Notes: Pricing varies; transparent info pages provided. Banxa
- Regions: Global (entity-specific); U.S. coverage via MTL entity; details in license PDFs. Banxa
- Consider If: Your risk/compliance teams require detailed attestations.
- Alternatives: Zero Hash, Transak.
6. Alchemy Pay — Best for emerging markets & alternative wallets
- Why Use It: Alchemy Pay bridges fiat and crypto with on/off-ramp across 50+ countries (and expanding), focusing on emerging markets and a wide range of local wallets/payments. It’s actively growing U.S. coverage via new MTLs (e.g., Arizona, South Carolina). docs+2alchemypay.org+2
- Best For: Dapps targeting emerging markets; global apps needing local wallets.
- Notable Features: On/off-ramp; Apple/Google Pay & regional wallets; developer docs; business flows. alchemypay.org
- Fees Notes: Competitive, vary by payment rail.
- Regions: Global (check country list); growing U.S. state coverage via MTLs. alchemypay.org
- Consider If: You prioritize local payment methods in APAC/LATAM.
- Alternatives: Transak, Ramp Network.
7. Kraken — Best regulated exchange on/off-ramp (U.S./EU)
- Why Use It: Kraken provides fiat funding and withdrawals in USD/EUR/CAD with ACH, SEPA, and card rails, offering a straightforward path to buy/sell and cash out to bank. Useful if you want exchange liquidity plus strong support docs. Kraken+1
- Best For: Traders and users who prefer exchange-native fiat rails.
- Notable Features: ACH deposits (no fee for many U.S. clients), cash withdrawals, app guides. Kraken+2Kraken Support+2
- Fees Notes: Funding/withdrawal fees and holds depend on method (e.g., ACH hold windows). Kraken Support
- Regions: U.S./EU/Canada; ACH account linking not available in NY, WA, TX. Kraken
- Consider If: You want deep orderbook liquidity alongside fiat rails.
- Alternatives: Bitstamp, Coinbase.
8. Bitstamp — Best for EU banking rails & stable UX
- Why Use It: One of the longest-running exchanges, Bitstamp supports bank deposits (SEPA/International, ACH) and card purchases, plus fiat withdrawals to bank accounts. Simple, well-documented flows are ideal for EU and U.S. users wanting a clean on/off-ramp. Bitstamp+2Bitstamp+2
- Best For: EU users; U.S. users comfortable with exchange-based cashouts.
- Notable Features: ACH deposits/withdrawals, SEPA (incl. Instant SEPA), card & Apple/Google Pay availability. Bitstamp+2Bitstamp+2
- Fees Notes: See Bitstamp fee schedule; varies by method. Bitstamp
- Regions: EU/UK/US (availability by method).
- Consider If: You want familiar exchange UX with established bank rails.
- Alternatives: Kraken, Coinbase.
9. Stripe Crypto Onramp — Best embeddable onramp for U.S./EU apps
- Why Use It: Stripe’s fiat-to-crypto onramp is a customizable widget/hosted flow you can embed in wallets, NFT apps, and dapps—Stripe handles KYC, fraud, and payments. Ideal for teams already on Stripe. Note: onramp availability is U.S. (excl. Hawaii) + EU. Stripe Docs+2Stripe Docs+2
- Best For: U.S./EU dapps and platforms standardizing on Stripe.
- Notable Features: Embedded or hosted onramp; identity & fraud tooling; stablecoin payout stack. Stripe Docs
- Fees Notes: Stripe pricing applies; quotes shown in onramp UI.
- Regions: U.S. (minus HI) and EU currently. Stripe Docs
- Consider If: You need a polished onramp (no off-ramp) with Stripe stack.
- Alternatives: Coinbase Onramp, MoonPay.
10. Zero Hash — Best turnkey B2B infrastructure (regulated build-out)
- Why Use It: Zero Hash powers on/off-ramp for enterprises, abstracting licensing and regulatory complexity. B2B partners can convert between fiat and 60+ crypto assets, with quote controls and payout rails. zerohash.com+1
- Best For: Fintechs, banks, and platforms embedding compliant crypto.
- Notable Features: API-first; short path to market; configurable quotes; bank payouts. docs.zerohash.com
- Fees Notes: Enterprise pricing; volume-based.
- Regions: Coverage varies by solution and jurisdiction.
- Consider If: You need compliance + infra rather than a retail widget.
- Alternatives: Banxa, Coinbase (developer).
Decision Guide: Best By Use Case
- Regulated U.S. focus (ACH off-ramp): Coinbase Onramp & Offramp; Kraken. Coinbase Developer Docs+1
- Global card-first & non-custodial: MoonPay. MoonPay
- Wide country/payment coverage: Ramp Network, Transak, Alchemy Pay. rampnetwork.com+2Transak+2
- Enterprise/Banking compliance: Banxa, Zero Hash. Banxa+1
- EU banking rails: Bitstamp. Bitstamp
- Stripe-native apps (U.S./EU): Stripe Crypto Onramp. Stripe Docs
How to Choose the Right Fiat ↔ Crypto On/Off-Ramp (Checklist)
- Confirm region & method eligibility (ACH/SEPA/cards; off-ramp availability by country/state).
- Check asset/fiat coverage for your top flows (BTC, ETH, stablecoins, local fiat).
- Review security posture (SOC/ISO, trust center, KYC/AML, sanctions screening). Ramp
- Compare fees & spreads (and promos like zero-fee USDC) and settlement speeds. Coinbase
- Validate developer experience (docs, hosted vs. embedded, SDKs). Coinbase
- Ensure support & SLAs meet your needs (status pages, incident comms).
- Red flags: unclear licensing, no security disclosures, or “global” claims without a country/method matrix.
Use Token Metrics With Any On/Off-Ramp
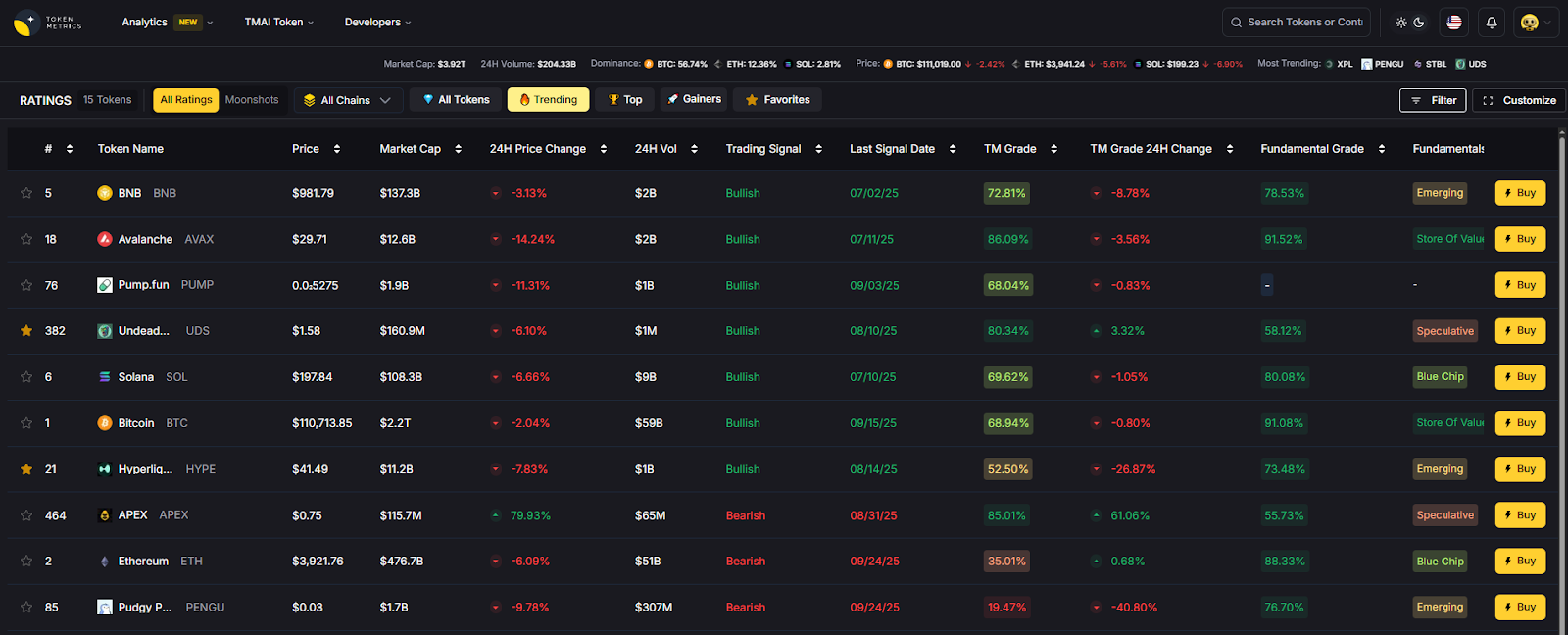
- AI Ratings: Screen top assets before you convert.
- Narrative Detection: Spot sector momentum early.
- Portfolio Optimization: Size positions to risk.
- Alerts/Signals: Get entries/exits without screen-watching.
Workflow: Research → Select ramp → Execute buy/sell → Monitor with alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enable 2FA and use strong unique passwords.
- Separate custody (self-custody vs. exchange) from ramp accounts as needed.
- Follow KYC/AML requirements; prepare source-of-funds docs for higher limits.
- For OTC/RFQ flows, lock quotes and confirm fees before sending. docs.zerohash.com
- Maintain wallet hygiene: test transfers, verify addresses, track gas/fees.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Assuming a provider supports both on- and off-ramp in your country (often not true). support.rampnetwork.com
- Ignoring ACH hold windows or payout timings when planning cashouts. Kraken Support
- Overlooking fees/spreads vs. headline “no fee” promos. Coinbase
- Embedding an onramp without sandbox/testing error states.
- Not checking licensing & security disclosures before integration. Banxa+1
FAQs
What is a crypto on-ramp vs. off-ramp?
An on-ramp lets users buy crypto with fiat (e.g., card, bank transfer). An off-ramp lets users sell crypto for fiat and withdraw to bank rails or cards. Coinbase
Which providers are best for U.S. ACH cashouts?
Coinbase Offramp and Kraken both support ACH, with method availability depending on state and account status. Coinbase Developer Docs+1
Does Stripe support off-ramp?
Stripe currently offers a fiat-to-crypto onramp (no off-ramp). It’s available in the U.S. (excluding Hawaii) and EU. Stripe Docs
Which options are strongest outside the U.S.?
For broad coverage and local rails, consider Ramp Network (Pix/SPEI), Transak (multi-network off-ramp), and Alchemy Pay (regional wallets). ramp.network+2Transak Docs+2
What about enterprise-grade compliance?
Banxa and Zero Hash publish license/compliance docs and are built for B2B integrations with higher assurance requirements. Banxa+1
Conclusion + Related Reads
The best choice depends on your region, payout rails, and risk posture. If you want a regulated U.S. ACH flow with strong docs, start with Coinbase. Need global coverage and local methods? Ramp, Transak, and Alchemy Pay shine. For enterprise and bank-grade requirements, Banxa and Zero Hash are strong bets. Exchange-based ramps via Kraken or Bitstamp work well if you also need deep liquidity.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.