



Top Smart Contract Auditors (2025)
%201.svg)
%201.svg)

Why Smart Contract Security Auditors Matter in September 2025
Smart contracts are the critical rails of DeFi, gaming, and tokenized assets—one missed edge case can freeze liquidity or drain treasuries. If you’re shipping on EVM, Solana, Cosmos, or rollups, smart contract auditors provide an independent, methodical review of your code and architecture before (and after) mainnet. In one line: a smart contract audit is a systematic assessment of your protocol’s design and code to find and fix vulnerabilities before attackers do.
This guide is for founders, protocol engineers, PMs, and DAOs comparing audit partners. We combined SERP research with hands-on security signals to shortlist reputable teams, then selected the best 10 for global builders. Secondary considerations—like turnaround time, formal methods, and public report history—help you match the right firm to your stack and stage.
How We Picked (Methodology & Scoring)
- Liquidity (30%) – We favored firms that regularly secure large TVL protocols and L2/L3 infrastructure (a proxy for real-world risk tolerance).
- Security (25%) – Depth of reviews, formal methods, fuzzing/invariants, internal QA, and disclosure practices.
- Coverage (15%) – Chains (EVM, Solana, Cosmos, Move), ZK systems, cross-chain, and infra.
- Costs (15%) – Transparent scoping, rate signals, and value versus complexity.
- UX (10%) – Developer collaboration, report clarity, suggested fixes.
- Support (5%) – Follow-ups, retests, and longer-term security programs.
Data inputs: official service/docs pages, public audit report portals, rate disclosures where available, and widely cited market datasets for cross-checks. Last updated September 2025.
Top 10 Smart Contract Auditors in September 2025
1. OpenZeppelin — Best for Ethereum-native protocols & standards
- Why Use It: OpenZeppelin sets the bar for Ethereum security reviews, blending deep code review with fuzzing and invariant testing. Their team maintains widely used libraries and brings ecosystem context to tricky design decisions. Audits are collaborative and issue-tracked end to end. OpenZeppelin+2docs.openzeppelin.com+2
- Best For: DeFi protocols, token standards/bridges, ZK/infra components, L2/L3 projects.
- Notable Features: Multi-researcher line-by-line reviews; fuzzing & invariants; Defender integrations; public customer stories.
- Consider If: Demand may affect near-term availability; enterprise pricing.
- Alternatives: ConsenSys Diligence, Sigma Prime
- Regions: Global • Fees/Notes: Quote-based.
2. Trail of Bits — Best for complex, high-risk systems
- Why Use It: A security research powerhouse, Trail of Bits excels on complicated protocol architectures and cross-component reviews (on-chain + off-chain). Their publications and tools culture translate into unusually deep findings and actionable remediation paths. Trail of Bits+1
- Best For: Novel consensus/mechanisms, bridges, MEV-sensitive systems, multi-stack apps.
- Notable Features: Custom tooling; broad ecosystem coverage (EVM, Solana, Cosmos, Substrate, Starknet); thorough reporting.
- Consider If: Lead times can be longer; premium pricing.
- Alternatives: Runtime Verification, Zellic
- Regions: Global • Fees/Notes: Quote-based.
3. Sigma Prime — Best for Ethereum core & DeFi heavyweights

- Why Use It: Sigma Prime combines practical auditing with core protocol experience (they build Lighthouse, an Ethereum consensus client), giving them unusual depth in consensus-adjacent DeFi and infra. Strong track record across blue-chip protocols. Sigma Prime+1
- Best For: Lending/AMMs, staking/validators, client-adjacent components, LSTs.
- Notable Features: Deep EVM specialization; transparent technical writing; senior engineering bench.
- Consider If: Primary focus is EVM; limited non-EVM coverage compared to others.
- Alternatives: OpenZeppelin, ChainSecurity
- Regions: Global • Fees/Notes: Quote-based.
4. ConsenSys Diligence — Best for Ethereum builders wanting tooling + audit
- Why Use It: Backed by ConsenSys, Diligence pairs audits with developer-facing tools and education, making it ideal for teams that want process maturity (prep checklists, fuzzing, Scribble specs). Broad portfolio and clear audit portal. Consensys Diligence+2Consensys Diligence+2
- Best For: Early-to-growth stage Ethereum teams, rollup apps, token launches.
- Notable Features: Audit portal; Scribble specification; fuzzing; practical prep guidance.
- Consider If: Primarily Ethereum; non-EVM work may require scoping checks.
- Alternatives: OpenZeppelin, ChainSecurity
- Regions: Global • Fees/Notes: Quote-based.
5. ChainSecurity — Best for complex DeFi mechanisms & institutions
- Why Use It: Since 2017, ChainSecurity has audited many flagship DeFi protocols and works with research institutions and central banks—useful for mechanism-dense systems and compliance-sensitive partners. Public report library is extensive. chainsecurity.com+1
- Best For: Lending/leverage, automated market design, enterprise & research tie-ups.
- Notable Features: Senior formal analysis; large library of public reports; mechanism design experience.
- Consider If: Scheduling can book out during heavy DeFi release cycles.
- Alternatives: Sigma Prime, Runtime Verification
- Regions: Global • Fees/Notes: Quote-based.
6. Runtime Verification — Best for formal methods & proofs
- Why Use It: RV applies mathematical modeling to verify contract behavior—ideal when correctness must be proven, not just reviewed. Transparent duration guidance and verification-first methodology stand out for high-assurance finance and bridges. runtimeverification.com+1
- Best For: Bridges, L2/L3 protocols, safety-critical DeFi, systems needing formal guarantees.
- Notable Features: Design modeling; proof-oriented analysis; published methodology; verification experts.
- Consider If: Formal methods add time/scope; ensure timelines fit launch plans.
- Alternatives: Trail of Bits, ChainSecurity
- Regions: Global • Fees/Notes: Time/cost scale with LoC & rigor.
7. Spearbit (via Cantina) — Best for assembling elite ad-hoc review teams
- Why Use It: Spearbit curates a network of top security researchers and spins up tailored teams for high-stakes reviews. Public “Spearbook” docs outline a transparent process and base rates—useful for planning and stakeholder alignment. docs.spearbit.com+1
- Best For: Protocols needing niche expertise (ZK, MEV, Solana, Cosmos) or rapid talent assembly.
- Notable Features: Researcher leaderboard; portfolio of reports; flexible scoping; public methodology.
- Consider If: Marketplace model—experience can vary; align on leads and scope early.
- Alternatives: Zellic, Trail of Bits
- Regions: Global • Fees/Notes: Base rate guidance published; final quotes vary.
8. Zellic — Best for offensive-security depth & cross-ecosystem coverage
- Why Use It: Founded by offensive researchers, Zellic emphasizes real-world exploit paths and releases practical research/tools (e.g., Masamune). Strong results across EVM, cross-chain, and high-value targets. zellic.io+2zellic.io+2
- Best For: Cross-chain systems, DeFi with complicated state machines, performance-critical code.
- Notable Features: Offensive mindset; tool-assisted reviews; transparent research blog.
- Consider If: Premium scope; verify bandwidth for urgent releases.
- Alternatives: OtterSec, Trail of Bits
- Regions: Global • Fees/Notes: Quote-based.
9. OtterSec — Best for Solana, Move, and high-velocity shipping teams
- Why Use It: OtterSec partners closely with fast-shipping teams across Solana, Sui, Aptos, and EVM, with a collaborative style and visible customer logos across top ecosystems. Useful when you need pragmatic feedback loops and retests. OtterSec+1
- Best For: Solana & Move projects, cross-chain bridges, wallets, DeFi apps.
- Notable Features: Holistic review method; $1B+ in vulnerabilities patched (self-reported); active blog & reports.
- Consider If: Verify scope for non-Move/Solana; high demand seasons can fill quickly.
- Alternatives: Zellic, Halborn
- Regions: Global • Fees/Notes: Quote-based.
10. Halborn — Best for enterprise-grade programs & multi-service security
- Why Use It: Halborn serves both crypto-native and financial institutions with audits, pentesting, and advisory; SOC 2-type attestations and steady cadence of public assessments support enterprise procurement. Halborn+1
- Best For: Exchanges, fintechs, large DeFi suites, and teams needing full-stack security partners.
- Notable Features: Audit portal & reports; enterprise processes; broader security services.
- Consider If: Quote-based pricing; confirm dedicated smart-contract reviewers for your stack.
- Alternatives: ConsenSys Diligence, Trail of Bits
- Regions: Global • Fees/Notes: Quote-based.
Decision Guide: Best By Use Case
- Ethereum DeFi blue-chips: OpenZeppelin, Sigma Prime
- High-assurance/formal proofs: Runtime Verification, ChainSecurity
- Novel mechanisms / complex cross-stack: Trail of Bits
- Rapid team assembly / niche experts (ZK/MEV): Spearbit
- Solana & Move ecosystems: OtterSec, Zellic
- Enterprise programs & multi-service: Halborn, ConsenSys Diligence
- Audit + developer tooling/process: ConsenSys Diligence, OpenZeppelin
How to Choose the Right Smart Contract Auditors (Checklist)
- Confirm chain coverage (EVM/Solana/Cosmos/Move/ZK) and prior similar audits.
- Review public reports for depth, reproductions, and clarity of recommendations.
- Ask about fuzzing/invariants and formal methods on high-risk components.
- Validate availability & timelines vs. your launch and retest windows.
- Align on scope & deliverables (threat model, PoCs, retest, disclosure).
- Clarify pricing (fixed/LoC-based, review period, retests).
- Check secure comms (issue trackers, PGP, private repos) and follow-up support.
- Red flags: “rubber-stamp” promises, guaranteed pass, or refusal to publish a report summary.
Use Token Metrics With Any Auditor
- AI Ratings screen sectors and assets before you commit dev cycles.
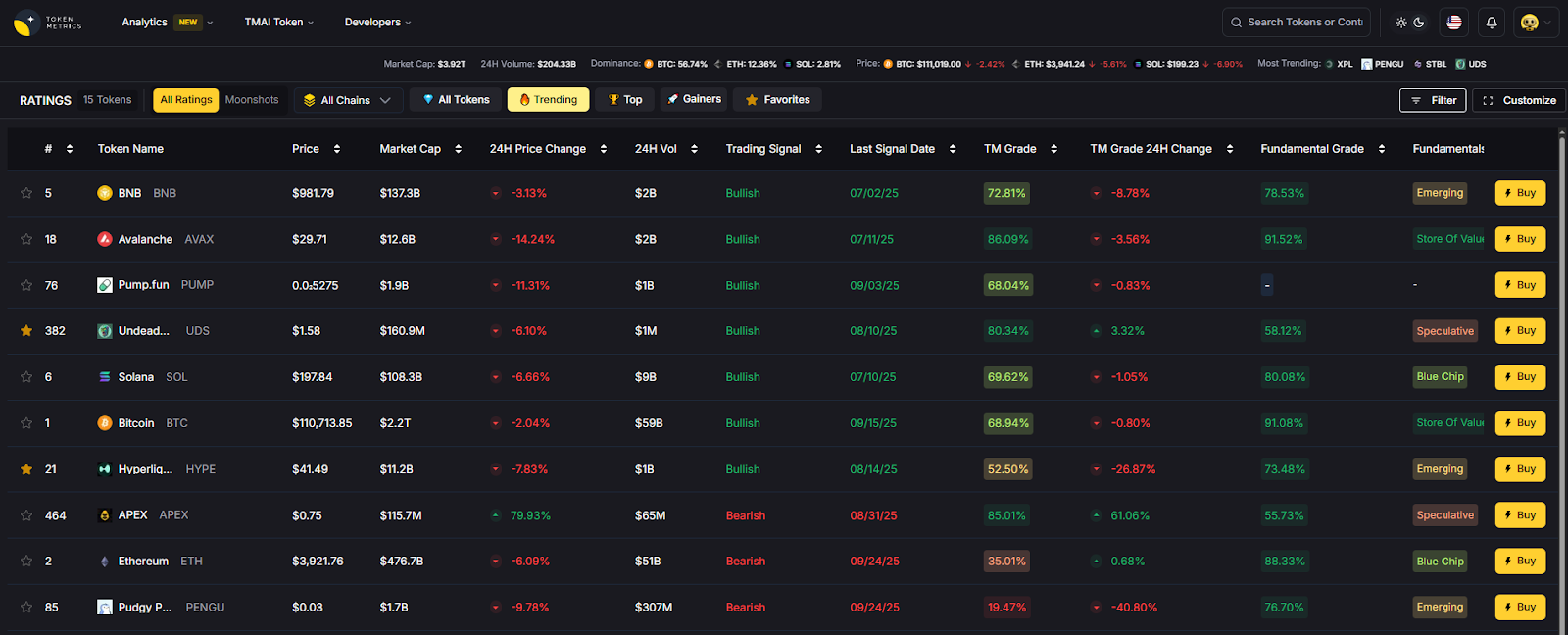
- Narrative Detection spots momentum so audits align with market timing.
- Portfolio Optimization balances audited vs. unaudited exposure.
- Alerts/Signals track unlocks, governance, and risk events post-launch.
Workflow: Research → Select auditor → Execute fixes/retest → Monitor with alerts.
Primary CTA: Start free trial

Security & Compliance Tips
- Enforce 2FA/hardware keys across repos and infra.
- Separate ops wallets from treasury; use MPC or HSM where appropriate.
- Align with KYC/AML and disclosures if raising or listing.
- Use bug bounties and continuous scanning after the audit.
- Practice key rotation, access reviews, and incident-response drills.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Treating an audit as a one-time checkbox instead of an iterative security program.
- Scoping only Solidity without reviewing off-chain components and oracles.
- Shipping major changes post-audit without a delta review.
- Publishing reports without fix verification.
- Ignoring test coverage, fuzzing, and invariant specs.
FAQs
What does a smart contract audit include?
Typically: architecture review, manual code analysis by multiple researchers, automated checks (linters, fuzzers), proof-of-concept exploits for issues, and a final report plus retest. Depth varies by scope and risk profile.
How long does an audit take?
From a few weeks to several months, depending on code size, complexity, and methodology (e.g., formal verification can extend timelines). Plan for time to remediate and retest before mainnet.
How much do audits cost?
Pricing is quote-based and driven by complexity, deadlines, and team composition. Some networks (e.g., Spearbit) publish base rate guidance to help with budgeting.
Do I need an audit if my code is forked?
Yes. Integration code, parameter changes, and new attack surfaces (bridges/oracles) can introduce critical risk—even if upstream code was audited.
Should I publish my audit report?
Most credible teams publish at least a summary. Public reports aid trust, listings, and bug bounty participation—while enabling community review.
What if we change code after the audit?
Request a delta audit and update your changelog. Major logic changes merit a retest; minor refactors may need targeted review.
Conclusion + Related Reads
Choosing the right auditor depends on your stack, risk tolerance, and timelines. For Ethereum-first teams, OpenZeppelin, Sigma Prime, and ConsenSys Diligence stand out. If you need high-assurance proofs or tricky mechanisms, look to Runtime Verification, ChainSecurity, or Trail of Bits. Solana/Move builders often pick OtterSec or Zellic. For flexible, elite review pods, Spearbit is strong.
Related Reads:
- Best Cryptocurrency Exchanges 2025
- Top Derivatives Platforms 2025
- Top Institutional Custody Providers 2025
Sources & Update Notes
We reviewed official audit/service pages, public report libraries, and process/rate disclosures for recency and scope fit. Third-party datasets were used only for cross-checks (no external links included). Updated September 2025.
- OpenZeppelin: Security Audits page; Defender Audit module; company homepage. OpenZeppelin+2docs.openzeppelin.com+2
- Trail of Bits: Blockchain services page; recent audit/industry posts. Trail of Bits+1
- Sigma Prime: Company site and engineering blog. Sigma Prime+1
- ConsenSys Diligence: Services page; audits portal; audit prep guidance. Consensys Diligence+2Consensys Diligence+2
- ChainSecurity: Services and report library. chainsecurity.com+1
- Runtime Verification: Smart contract audits; methodology pages. runtimeverification.com+1
- Spearbit (Cantina): Public process docs; base rate guidance. docs.spearbit.com+1
- Zellic: Services and research/blog (Masamune). zellic.io+2zellic.io+2
- OtterSec: Homepage, client examples, and contact/reports hub. OtterSec+1
Halborn: Homepage; audits & recent report examples; team/enterprise posture. Halborn+2Halborn+2
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.