



Altcoins Bull Run: How to Prepare and Profit in 2025
%201.svg)
%201.svg)


Introduction: The Next Altcoin Bull Run
Altcoin bull runs are some of the most exciting periods in cryptocurrency, delivering life‑changing gains for prepared investors. These cycles often follow or coincide with Bitcoin rallies, as capital flows into smaller, high‑growth tokens in search of outsized returns.
In 2025, with AI‑powered platforms, institutional adoption, and innovative sectors like DeFi, AI tokens, and real‑world assets (RWAs) driving growth, the stage is set for a potentially historic altcoin bull run. This guide explains how to prepare, what to watch for, and how tools like Token Metrics can help you capitalize on this opportunity.
What Triggers an Altcoin Bull Run?
Understanding what drives these rallies is key to recognizing when one begins.
- Bitcoin’s Rally & Consolidation:
Historically, altcoins outperform when Bitcoin dominance peaks and stabilizes, freeing capital for riskier plays. - Narrative‑Driven Growth:
Sectors like AI tokens (e.g., TMAI), Layer 2 scaling solutions, and DeFi protocols often spark renewed investor interest. - Increased Institutional Involvement:
The rise of crypto ETFs, staking products, and venture capital fuels liquidity for altcoins. - Retail FOMO (Fear of Missing Out):
Bull runs accelerate when mainstream investors pile in, chasing early winners.
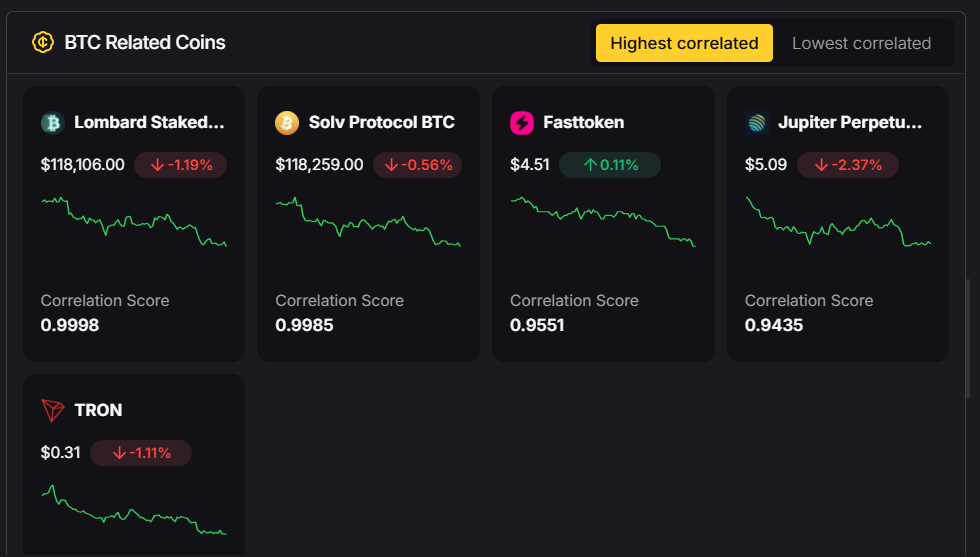
Signs an Altcoin Bull Run Is Starting
- Rising Altcoin Market Cap: Watch for increasing total market cap outside Bitcoin, signaling inflows to smaller coins.
- Bitcoin Dominance Decline: A drop in BTC dominance often correlates with altcoin rallies.
- AI‑Detected Trend Shifts: Platforms like Token Metrics can identify early momentum signals across hundreds of tokens.
- On‑Chain Activity Surge: Rising active wallets, transactions, and developer contributions are bullish indicators.
How to Prepare for the Next Bull Run
Preparation is everything. Here’s how to position yourself before the market takes off:
1. Build a Diversified Portfolio:
Combine large‑cap coins (Ethereum, Solana) with high‑potential small‑caps like Token Metrics AI (TMAI) or narrative‑driven DeFi tokens.
2. Use AI‑Powered Analytics:
Token Metrics leverages over 80 data points per token—including technicals, fundamentals, and sentiment—to help you spot early movers before the crowd.
3. Set Entry and Exit Plans:
Define profit targets and stop‑loss levels before entering trades to avoid emotional decisions during volatility.
4. Stay Liquid:
Keep a portion of your portfolio in stablecoins to seize opportunities during sharp pullbacks.
Top Narratives for the 2025 Bull Run
The next altcoin season will likely be driven by powerful narratives:
- AI Tokens: Projects like Token Metrics AI (TMAI) and Fetch.ai (FET) combining blockchain and artificial intelligence.
- Real‑World Asset Tokenization: Platforms enabling real estate, commodities, and equity tokenization.
- DeFi Evolution: Next‑gen decentralized finance protocols offering higher yields and lower fees.
- Layer 2 Scaling: Solutions like Polygon (MATIC) and Arbitrum (ARB) improving blockchain efficiency.
Strategies to Maximize Profits
- Dollar‑Cost Averaging (DCA):
Invest gradually to reduce exposure to volatility while building positions in high‑conviction tokens. - Swing Trading:
Use short‑ to mid‑term trades to capture profits during parabolic moves. Token Metrics trading signals can help identify ideal entry and exit points. - Staking & Yield Farming:
Earn passive income on proof‑of‑stake tokens and DeFi platforms while holding long‑term assets. - Portfolio Rebalancing:
Periodically adjust allocations to lock in profits and maintain risk‑reward balance.
Managing Risk in a Bull Run
With great opportunity comes great risk. Here’s how to protect your gains:
- Set Stop‑Loss Orders: Prevent catastrophic losses in case of sudden market reversals.
- Take Profits Early: Secure gains incrementally instead of waiting for perfect tops.
- Avoid Overleveraging: High leverage can amplify losses as quickly as profits.
- Rely on Data: Use Token Metrics’ AI‑powered portfolio tools to track performance and adjust based on market signals.
The Role of Token Metrics in Bull Run Investing
Token Metrics is an essential tool for navigating altcoin bull markets, offering:
- AI‑Generated Ratings: Scoring tokens based on fundamentals, technical analysis, and on‑chain data.
- Narrative Detection: Identifying hot sectors like AI or DeFi before they trend.
- Portfolio Optimization: Helping you allocate capital efficiently across high‑potential assets.
- Real‑Time Alerts: Notifications for bullish or bearish momentum shifts.
This data‑driven approach helps investors stay ahead of the crowd and avoid emotional decision‑making during fast‑moving markets.
Common Mistakes to Avoid
- Chasing Pumps: Don’t buy tokens already up several hundred percent without understanding their fundamentals.
- Ignoring Fundamentals: Popularity alone doesn’t guarantee long‑term success—use platforms like Token Metrics for deep analysis.
- Lack of an Exit Plan: Have clear profit targets and stick to them.
The Future of Altcoin Bull Runs
As crypto matures, AI‑enhanced analytics, regulatory clarity, and wider institutional adoption are likely to make future altcoin seasons more sustainable and inclusive.
In 2025, the winners will be those who combine smart preparation, narrative awareness, and AI‑powered tools like Token Metrics to maximize returns.
Conclusion
The 2025 altcoins bull run could be one of the most lucrative in crypto history, but success requires preparation, strategy, and discipline.
By diversifying across high‑potential narratives, using AI‑driven insights from Token Metrics, and following a clear plan, you can profit from explosive growth while managing risk effectively.
In altcoin bull runs, timing, data, and psychology are everything—get them right, and the opportunities are limitless.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.