



🚀 Announcing the Launch of the Token Metrics API & SDK — Powered by $TMAI
%201.svg)
%201.svg)


Introducing the Token Metrics API: Power Your Crypto Tools with AI-Driven Intelligence
We’re thrilled to announce one of our most important product launches to date: the Token Metrics API is now live.
This powerful crypto API gives developers, quant traders, and crypto startups direct access to the core AI infrastructure that powers the Token Metrics platform. Whether you’re building trading agents, investor dashboards, research tools, or mobile apps, our API and SDKs provide everything you need to build with real-time crypto data and intelligence—right out of the box.
For the first time, you can plug into the same AI API that drives our ratings, signals, and predictions—and embed it directly into your products, tools, or internal systems.
🔍 What’s Inside the Token Metrics API?
Our crypto API is designed to give you high-performance access to the exact data models we use in-house:
✅ AI Trading Signals
Access bullish and bearish calls across thousands of tokens. These API endpoints are powered by machine learning models trained on historical price action, sentiment data, and blockchain activity.
✅ Investor & Trader Grades
Through our API, you can pull dynamic 0–100 grades on any token. Designed for long-term or short-term views, these scores factor in volatility, momentum, market cap trends, and our proprietary AI predictions.
✅ AI Reports & Conversation Crypto Agent
Query the API to generate custom reports and insights using our smart crypto assistant. Analyze market trends, token health, and investment opportunities—without writing your own models.
✅ Token Performance Data
Retrieve token-level analytics like ROI, predictive volatility, and asset rankings. Perfect for powering dashboards, investor tools, or internal models.
✅ Market Sentiment Models
Use the API to access our AI-modeled sentiment engine, built from social media, news data, and trend signals—ideal for gauging crowd psychology.
All Token Metrics API endpoints are RESTful, fast, and easy to integrate. SDKs for Python, Node.js, and other environments help developers onboard quickly.
🛠️ What You Can Build With the Token Metrics API
Our users are already building next-gen tools and automation using the Token Metrics API:
- 🤖 CEX Trading Agents — Automate entries and exits with real-time signals and token grades
- ⛓️ DEX Arbitrage Engines — Scan price differences across DeFi and act instantly
- 📊 Analytics Dashboards — Build data-driven tools with predictive metrics and visualizations
- 💬 Alert Bots for Telegram & Discord — Deliver actionable alerts using our signal API
- 📱 Web & Mobile Crypto Apps — Enhance portfolios and research apps with AI intelligence
With just a few lines of code and an API key, you can turn static crypto apps into dynamic, intelligent systems.
💸 Affordable Pricing & $TMAI Utility
We’ve designed our crypto API pricing to be flexible and accessible:
- Plans start at $99/month, with high usage limits
- Save up to 35% when you pay with our native token, $TMAI
- All tiers include access to powerful AI tools and real-time crypto data
Whether you're a solo dev or scaling a trading startup, there’s a plan built for you. Paying with $TMAI also deepens your utility in the Token Metrics ecosystem—this is just the beginning of native token perks.
🧪 Try the Token Metrics API for Free
Not ready to commit? Try our free API tier with:
- Limited endpoints to explore
- Access to live documentation and test queries
- Sample code and SDKs for instant implementation
Start exploring at tokenmetrics.com/api
🌐 Why We Built This Crypto API
Token Metrics has always been focused on empowering smarter investing. But as the market evolves, we believe the future lies in infrastructure, automation, and open access.
That’s why we built the Token Metrics API—to give developers access to the exact AI systems we use ourselves. Our models have been fine-tuned over years, and now, that same intelligence can power your platform, tools, or trading agents.
Whether you're building research platforms, signal-based apps, or automated execution tools—this API is your edge.
⚡ Start Building with Token Metrics API for FREE→ tokenmetrics.com/api
The crypto market never sleeps—and with the Token Metrics API, neither do your tools.
AI Agents in Minutes, Not Months

.svg)


%201.svg)
Create Your Free Token Metrics Account


.png)
Recent Posts

Best Liquid Restaking Tokens & Aggregators (2025)
Who this guide is for. Investors and builders comparing best liquid restaking tokens (LRTs) and aggregators to earn ETH staking + restaking rewards with on-chain liquidity.
Top three picks.
- ether.fi (eETH/weETH): Non-custodial, deep integrations, clear docs. (ether.fi)
- Renzo (ezETH): Multi-stack (EigenLayer + Symbiotic/Jito), transparent 10% rewards fee. (docs.renzoprotocol.com)
- Kelp DAO (rsETH): Broad DeFi reach; explicit fee policy for direct ETH deposits. (kelp.gitbook.io)
One key caveat. Fees, redemption paths, and regional access vary by protocol—check official docs and terms before depositing.
Introduction
Liquid restaking lets you restake staked assets (most often ETH) to secure Actively Validated Services (AVSs) while receiving a liquid restaking token you can use across DeFi. The value prop in 2025: stack base staking yield + restaking rewards, with composability for lending, LPing, and hedging. In this commercial-investigational guide, we compare the best liquid restaking tokens and the top aggregators that route deposits across operators/AVSs, with an emphasis on verifiable fees, security posture, and redemption flow. We weigh scale and liquidity against risk controls and documentation quality to help you pick a fit for your region, risk tolerance, and toolstack.
How We Picked (Methodology & Scoring)
- Liquidity — 30%: On-chain depth, integrations, and redemption mechanics.
- Security — 25%: Audits, docs, risk disclosures, validator design.
- Coverage — 15%: AVS breadth, multi-stack support (EigenLayer/Symbiotic/Jito), asset options.
- Costs — 15%: Transparent fee schedules and user economics.
- UX — 10%: Clarity of flows, dashboards, and docs.
- Support — 5%: Status pages, help docs, comms.
Evidence sources: official websites, docs, pricing/fees and security pages, and status/terms pages; third-party datasets used only to cross-check volumes. Last updated November 2025.
Best Liquid Restaking Tokens & Aggregators in November 2025 (Comparison Table)
* Regions are “Global” unless a provider geoblocks specific jurisdictions in their terms. Always verify eligibility in your country.
Top 10 Liquid Restaking Tokens & Aggregators in November 2025
1. ether.fi — Best for deep integrations & non-custodial design
Why use it: ether.fi’s eETH/weETH are widely integrated across DeFi, and the project publishes clear technical docs on protocol fees and validator design. Liquid Vaults add strategy optionality while keeping restaking accessible. (ether.fi)
Best for: DeFi power users, liquidity seekers, builders needing broad integrations.
Notable features: Non-custodial staking; restaking support; Liquid Vaults; documentation and terms around protocol fees. (etherfi.gitbook.io)
Fees Notes: Protocol fee on rewards; vault-level fees vary by strategy. (etherfi.gitbook.io)
Regions: Global*
Consider if: You want deep liquidity and docs; always review fee tables and redemption queues.
Alternatives: Renzo, Kelp DAO.
2. Renzo — Best for multi-stack coverage (EigenLayer + Symbiotic/Jito)
Why use it: Renzo’s ezETH is among the most recognizable LRTs and the docs clearly state a 10% rewards fee, while the app highlights support beyond EigenLayer (e.g., Symbiotic/Jito lines). Strong multichain UX. (docs.renzoprotocol.com)
Best for: Users wanting straightforward economics and chain-abstracted access.
Notable features: Clear fee policy (10% of restaking rewards); multi-stack support; app UX across chains. (docs.renzoprotocol.com)
Fees Notes: 10% of restaking rewards; details in docs. (docs.renzoprotocol.com)
Regions: Global*
Consider if: You prefer transparent fees and broader stack exposure.
Alternatives: ether.fi, Mellow.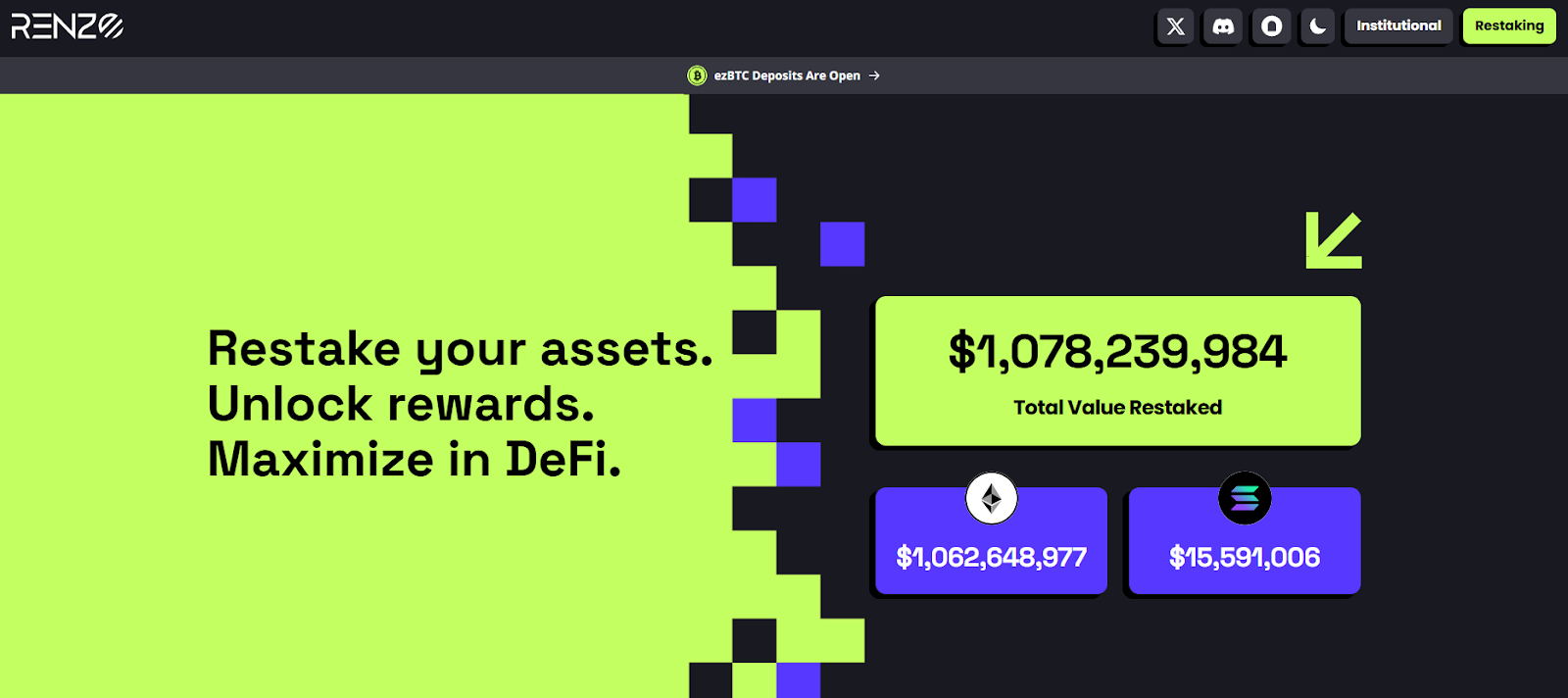
3. Kelp DAO — Best for broad DeFi distribution (rsETH)
Why use it: Kelp emphasizes reach (rsETH used across many venues). Official docs state a 10% fee on rewards for direct ETH deposits, with no fee on LST deposits, making it friendly to LST holders. (kelpdao.xyz)
Best for: LST holders, LPs, and integrators.
Notable features: rsETH liquid token; LST and ETH deposit routes; active integrations. (kelpdao.xyz)
Fees Notes: 10% on ETH-deposit rewards; no fee on LST deposits per docs. (kelp.gitbook.io)
Regions: Global*
Consider if: You want flexibility between ETH and LST deposit paths.
Alternatives: Renzo, Swell.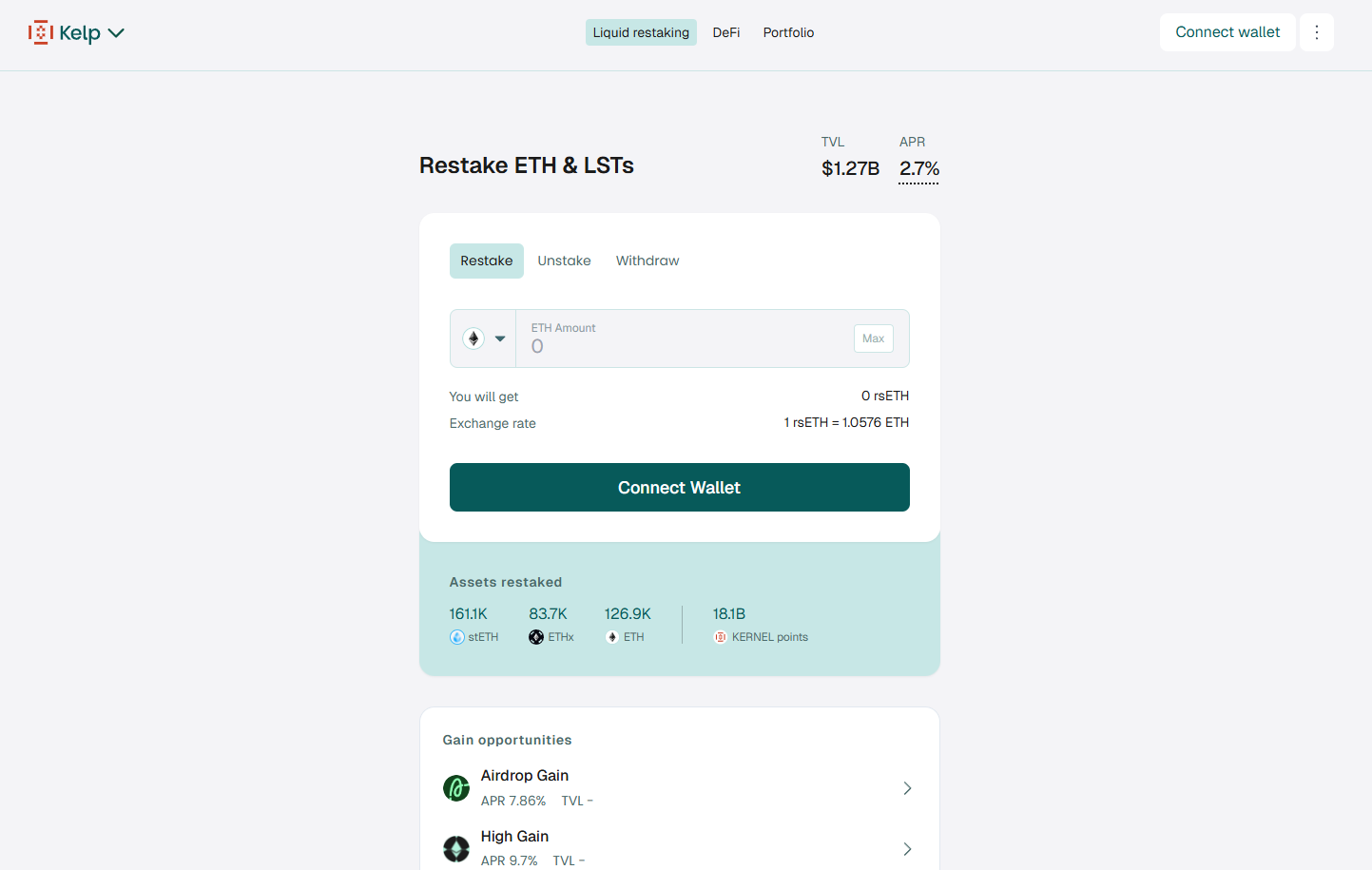
4. Puffer — Best for redemption optionality (pufETH)
Why use it: Puffer’s docs explain how AVS fees accrue to pufETH and outline operator/guardian roles. Public risk work notes an “immediate redemption” option with a fee when liquidity is available, plus queued exit. (docs.puffer.fi)
Best for: Users wanting explicit redemption choices and a technical spec.
Notable features: pufETH nLRT; operator/guardian model; based L2 plans. (Puffer: Building the Future of Ethereum)
Fees Notes: AVS/operator fees accrue; immediate redemption may incur a fee. (docs.puffer.fi)
Regions: Global*
Consider if: You value documented mechanics and redemption flexibility.
Alternatives: ether.fi, Bedrock.
5. Swell — Best for restaking-native ecosystem (rswETH)
Why use it: Swell’s rswETH is their native LRT for EigenLayer; launch comms detailed fee-holiday parameters and security posture. Swellchain materials emphasize restaking-first ecosystem tooling. (swellnetwork.io)
Best for: DeFi users who want a restaking-centric stack.
Notable features: rswETH; ecosystem focus; audits referenced in launch post. (swellnetwork.io)
Fees Notes: Historical launch promo; check current fee schedule in app/docs. (swellnetwork.io)
Regions: Global*
Consider if: You want an LRT aligned with a restaking-native L2 vision.
Alternatives: Kelp DAO, Renzo.
6. Bedrock — Best for institutional-grade infra (uniETH)
Why use it: Bedrock’s uniETH is a non-rebasing, value-accrual LRT with a published fee policy (10% on block/MEV rewards) and EigenLayer alignment. Docs are explicit about token mechanics. (docs.bedrock.technology)
Best for: Institutions and users who prefer clear token economics.
Notable features: uniETH; docs and audits repository; multi-asset roadmap. (docs.bedrock.technology)
Fees Notes: 10% commission on block/MEV rewards; restaking commission TBD via governance. (docs.bedrock.technology)
Regions: Global*
Consider if: You want explicit fee language and non-rebasing accounting.
Alternatives: Puffer, ether.fi.
7. YieldNest — Best for curated basket exposure (ynETH)
Why use it: Docs describe ynETH as an nLRT with a curated basket of AVS categories, plus a protocol model where a fee is taken from staking/restaking rewards. MAX vaults and DAO governance are outlined. (docs.yieldnest.finance)
Best for: Users who want diversified AVS exposure through one token.
Notable features: ynETH; MAX vaults (ynETHx); governance/fee transparency. (docs.yieldnest.finance)
Fees Notes: Protocol fee on staking/restaking rewards per docs. (docs.yieldnest.finance)
Regions: Global*
Consider if: You prefer basket-style AVS diversification.
Alternatives: Mellow, Renzo.
8. Mellow Protocol — Best for strategy vaults with explicit fees (strETH)
Why use it: Mellow provides strategy vaults for restaking with clear fee terms: 1% platform + 10% performance baked into vault accounting, and visible TVL. (mellow.finance)
Best for: Users who want managed strategies with transparent fee splits.
Notable features: Curated strategy vaults; institutional risk curators; TVL transparency. (mellow.finance)
Fees Notes: 1% platform fee (pro-rated) + 10% performance fee. (docs.mellow.finance)
Regions: Global*
Consider if: You value explicit, vault-level fee logic.
Alternatives: YieldNest, InceptionLRT.
9. InceptionLRT — Best for native + LST restaking routes
Why use it: Inception exposes native ETH and LST restaking paths, with branded vault tokens (e.g., inETH) and Symbiotic integrations for certain routes. Site and app pages outline flows. (inceptionlrt.com)
Best for: Users wanting both native and LST restake options from one dashboard.
Notable features: Native ETH restake; LST restake; app-based delegation flows. (inceptionlrt.com)
Fees Notes: Fees vary by vault/route; review app/docs before deposit. (inceptionlrt.com)
Regions: Global*
Consider if: You want flexible inputs (ETH or LST) with aggregator UX.
Alternatives: Mellow, YieldNest.
10. Restake Finance — Best for modular LRT approach (rstETH)
Why use it: Project messaging emphasizes a modular liquid restaking design focused on EigenLayer with rstETH as its token. Governance-driven roadmap and LRT utility are core themes. (MEXC)
Best for: Early adopters exploring modular LRT architectures.
Notable features: rstETH LRT; DAO governance; EigenLayer focus. (MEXC)
Fees Notes: Fees/policies per official materials; review before use. (MEXC)
Regions: Global*
Consider if: You want a DAO-led modular LRT approach.
Alternatives: Renzo, Bedrock.
Decision Guide: Best By Use Case
- Deep integrations & liquidity: ether.fi, Renzo. (ether.fi)
- Most transparent fee schedule: Renzo (10% rewards fee), Mellow (1% + 10%). (docs.renzoprotocol.com)
- LST holders (no fee on LST deposits): Kelp DAO. (kelp.gitbook.io)
- Redemption flexibility (instant option + queue): Puffer. (LlamaRisk)
- Restaking-native ecosystem bet: Swell (rswETH/Swellchain). (swellnetwork.io)
- Institutional docs & non-rebasing accounting: Bedrock (uniETH). (docs.bedrock.technology)
- Basket-style AVS exposure: YieldNest (ynETH). (docs.yieldnest.finance)
- Strategy vaults with explicit fees: Mellow. (docs.mellow.finance)
- Native + LST aggregator UX: InceptionLRT. (inceptionlrt.com)
- Modular LRT exploration: Restake Finance. (MEXC)
How to Choose the Right Liquid Restaking Token (Checklist)
- Region eligibility: Confirm geoblocks/terms for your country.
- Asset coverage: ETH only or multi-asset; LST deposits supported.
- Fee transparency: Rewards/performance/platform fees clearly stated.
- Redemption path: Immediate exit fee vs. queue, and typical timing.
- Security posture: Audits, docs, risk disclosures, operator set.
- Integrations: Lending/DEX/LP venues for liquidity management.
- Stack choice: EigenLayer only or Symbiotic/Jito as well.
- UX/docs: Clear FAQs, step-by-step flows, status/terms.
- Support: Help center or community channels with updates.
Red flags: Opaque fee language; no docs on withdrawals; no audits or terms.
Use Token Metrics With Any LRT
- AI Ratings to screen assets and venues by quality and momentum.
- Narrative Detection to catch early shifts in restaking themes.
- Portfolio Optimization to balance exposure across LRTs vs. LSTs.
- Alerts & Signals to time rebalances and exits.
Workflow: Research → Select provider → Execute on-chain → Monitor with alerts.
Prefer diversified exposure? Explore Token Metrics Indices.
Security & Compliance Tips
- Use verified URLs and signed fronts; bookmark dApps.
- Understand redemption mechanics (instant vs. queue) and fees. (LlamaRisk)
- Read fee pages before deposit; some charge on rewards, others on performance/platform. (docs.renzoprotocol.com)
- Review audits/risk docs where available; check operator design.
- If LPing LRT/ETH, monitor depeg risk and oracle choice.
- Avoid approvals you don’t need; regularly revoke stale allowances.
- Confirm region eligibility and tax implications.
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Treating LRTs like 1:1 ETH with zero risk.
- Ignoring withdrawal queues and exit windows.
- Chasing points/boosts without reading fee docs.
- LPing volatile LRT pairs without hedge.
- Overconcentrating in one operator/AVS route.
- Skipping protocol terms or assuming U.S. access by default.
How We Picked (Methodology & Scoring)
We scored each provider using the weights above, focusing on official fee pages, docs, and security materials. We shortlisted ~20 projects and selected 10 with the strongest mix of liquidity, disclosures, and fit for this category. Freshness verified November 2025 via official resources.
FAQs
What is a liquid restaking token (LRT)?
An LRT is a liquid receipt for restaked assets (usually ETH) that accrues base staking plus AVS restaking rewards and can be used across DeFi.
Are LRTs safe?
They carry smart-contract, operator, and AVS risks in addition to staking risks. Read audits, fee pages, and redemption docs before depositing.
What fees should I expect?
Common models include a percent of rewards (e.g., 10% at Renzo) or platform + performance fees (e.g., 1% + 10% at Mellow). Always check the latest official docs. (docs.renzoprotocol.com)
What’s the difference between EigenLayer vs. Symbiotic/Jito routes?
They’re different restaking stacks and AVS ecosystems. Some providers support multiple stacks to diversify coverage. (docs.renzoprotocol.com)
How do redemptions work?
Most use queued exits; some offer instant liquidity with a fee when available (e.g., Puffer). Review the protocol’s redemption section. (LlamaRisk)
Can U.S. users access these protocols?
Terms vary by protocol and may change. Always check the provider’s website and terms for your jurisdiction.
Conclusion + Related Reads
If you want liquidity + integrations, start with ether.fi or Renzo. Prefer explicit fee logic in a managed strategy? Look at Mellow. Want basket exposure? Consider YieldNest. For redemption flexibility, Puffer stands out. Match the fee model, stack coverage, and redemption flow to your risk and liquidity needs.
Related Reads:

Top AMM Concentrated Crypto Liquidity Managers (2025)
Who this guide is for: DeFi liquidity providers seeking automated management of concentrated liquidity positions on AMMs like Uniswap v3, v4, and other CLAMMs (Concentrated Liquidity Automated Market Makers).
Top three picks:
- Gamma Strategies — Best for multi-chain automated vault strategies with proven track record
- Arrakis Finance — Best for institutional-grade liquidity management and token launch support
- Steer Protocol — Best for off-chain compute and cross-chain strategy deployment
Key caveat: Concentrated liquidity managers cannot eliminate impermanent loss; they optimize range management to maximize fee generation, but market volatility can still result in divergence loss. Always verify supported chains and fee structures before depositing.
Introduction: Why AMM Concentrated Liquidity Managers Matter in November 2025
Concentrated liquidity has transformed DeFi capital efficiency since Uniswap v3's 2021 launch, allowing liquidity providers to concentrate capital within specific price ranges for higher fee generation. However, managing these positions requires active monitoring, frequent rebalancing, and sophisticated strategies to remain in-range and profitable—a challenge for most LPs.
AMM concentrated liquidity managers are protocols that automate the complex task of managing concentrated liquidity positions across decentralized exchanges. These platforms use algorithmic strategies to rebalance ranges, compound fees, and optimize capital deployment, transforming concentrated liquidity from an active management burden into a passive income opportunity.
With Uniswap v4's January 2025 launch introducing hooks and new customization capabilities, the concentrated liquidity management landscape has expanded dramatically. LPs now need solutions that can navigate multiple AMMs, chains, and strategy types while maximizing returns and minimizing risks like impermanent loss and out-of-range periods.
This guide evaluates the leading concentrated liquidity managers serving retail LPs, DAOs, and protocols in 2025, helping you select platforms that align with your risk tolerance, capital requirements, and yield objectives.
How We Picked (Methodology & Scoring)
We evaluated 20+ concentrated liquidity management platforms and selected the top 10 based on weighted criteria:
- Liquidity Under Management — 30%: Total value locked (TVL) and managed positions across chains
- Security & Track Record — 25%: Audit history, operational history, security incidents
- Strategy Diversity — 15%: Range of automated strategies and customization options
- Chain & Protocol Coverage — 15%: Supported blockchains and DEX integrations
- Fees & Transparency — 10%: Performance fees, withdrawal fees, and cost clarity
- UX & Accessibility — 5%: Interface quality, documentation, and ease of use
Data sources: Official protocol documentation, pricing pages, security audit reports, blockchain explorers, and TVL data from DefiLlama (cross-checked only; not linked in article body).
Last updated: November 2025
Best AMM Concentrated Liquidity Managers in November 2025 (Comparison Table)
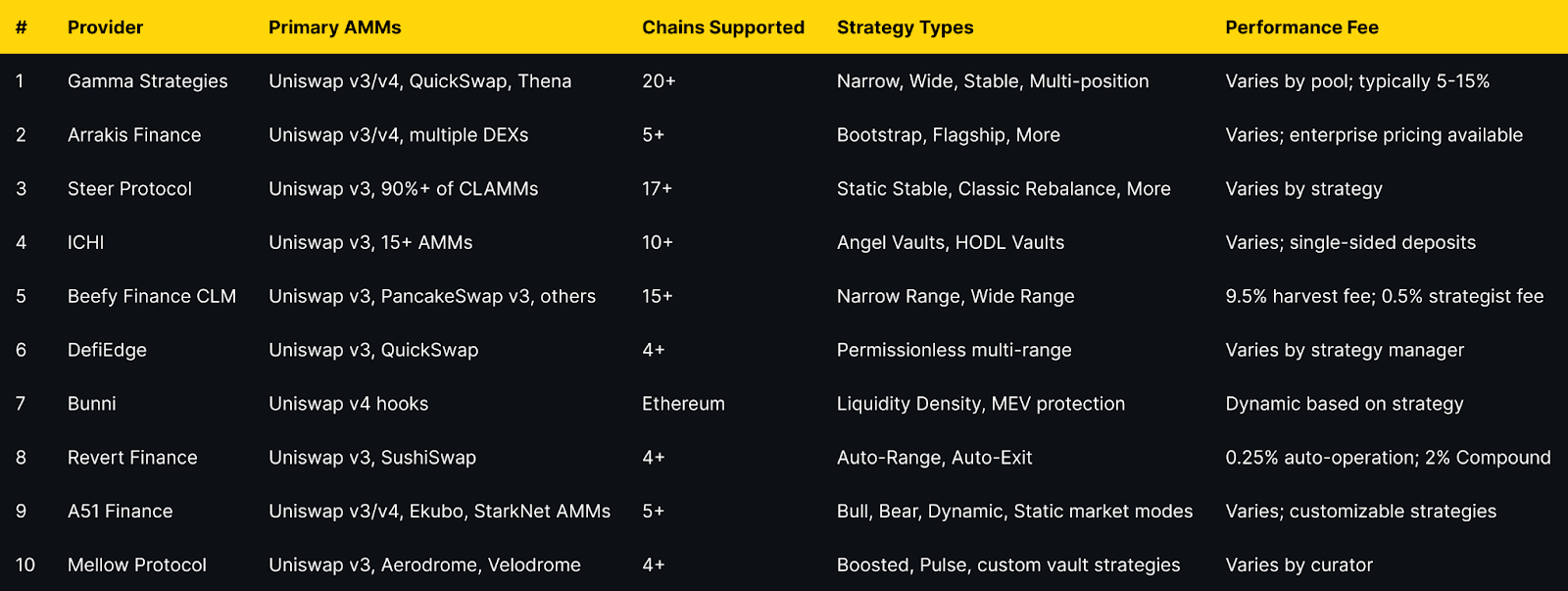
Top 10 AMM Concentrated Liquidity Managers in November 2025
1. Gamma Strategies — Best for Multi-Chain Automated Vaults
Why Use It
Gamma Strategies operates as the most established concentrated liquidity manager with over four years of production history since March 2021. Their Hypervisor vault system automatically rebalances positions, compounds fees, and manages ranges across 20+ blockchains and multiple AMM protocols. Gamma's non-custodial approach means LPs retain control while benefiting from algorithmic management that maximizes capital efficiency and fee generation.
Best For
- Multi-chain liquidity providers seeking diversified exposure
- DAOs and protocols requiring active liquidity management
- LPs wanting automated fee compounding without manual intervention
- Users preferring ERC-20 LP tokens over NFT positions
Notable Features
- Hypervisor smart contracts with automated rebalancing
- Supports dual-position and multi-position strategies (up to 20 positions on Uniswap v4)
- ERC-20 LP tokens for composability in DeFi
- Integration with major DEXs including Uniswap v3/v4, QuickSwap, Thena, Beamswap
- GAMMA token staking for fee-sharing
Consider If: Supported on 20+ chains but fee structures vary by pool; verify specific pool performance fees before depositing. Some pools charge 10-15% of generated fees.
Regions: Global; no geographic restrictions
Alternatives: Arrakis Finance, Steer Protocol
2. Arrakis Finance — Best for Institutional Liquidity Management
Why Use It
Arrakis Finance delivers MEV-aware onchain market making specifically designed for token issuers and institutional liquidity providers. Their Arrakis Pro service offers white-glove liquidity management with strategic templates including Bootstrap for TGE, Flagship for mature projects, and Treasury Diversification for passive accumulation. Arrakis has become the go-to solution for protocols like ether.fi, Euler, and Stargate seeking professional-grade liquidity infrastructure.
Best For
- Token launch teams needing TGE liquidity support
- Protocols managing protocol-owned liquidity (POL)
- Institutional LPs requiring custom strategy execution
- Projects seeking multi-DEX liquidity deployment
Notable Features
- Four strategy templates: Bootstrap, Flagship, Treasury Diversification, Custom
- Multi-DEX support (Uniswap v3/v4, PancakeSwap v3, and others)
- MEV-aware rebalancing algorithms
- Modules for concentrated liquidity across chains
- Enterprise-grade support and customization
Consider If: Primarily targets institutional clients; retail LPs may find Arrakis V1 (older version) more accessible than Arrakis Pro. Performance fees vary and often involve revenue-sharing arrangements.
Fees Notes: Enterprise pricing; contact for specific fee structures
Regions: Global; primarily serves protocols and DAOs
Alternatives: Gamma Strategies, Steer Protocol

3. Steer Protocol — Best for Off-Chain Compute Strategies
Why Use It
Steer Protocol distinguishes itself through decentralized off-chain computation that enables sophisticated strategy execution without on-chain gas overhead. Supporting 17+ chains and over 90% of concentrated liquidity AMMs, Steer provides automated range management using strategies like Elastic Expansion (Bollinger Bands), Moving Volatility Channel (Keltner), and Static Stable for pegged assets. Their infrastructure powers liquidity automation for platforms like QuickSwap, Taiko, and Kinetic.
Best For
- LPs seeking advanced technical analysis-based strategies
- Cross-chain liquidity providers
- Projects requiring custom liquidity shapes and automation
- Users wanting minimal gas costs for strategy execution
Notable Features
- Off-chain compute protocol reducing on-chain execution costs
- Support for TypeScript, Rust, and Go strategy development
- Multiple strategy families: Static Stable, Classic Rebalance, Volatility Channel, Elastic Expansion
- Integration with 90%+ of CLAMMs
- White-label infrastructure for protocols
Consider If: Strategy complexity may require more sophisticated understanding; best for LPs comfortable with advanced AMM concepts.
Fees Notes: Varies by strategy and deployment; network fees apply
Regions: Global; no restrictions
Alternatives: DefiEdge, Gamma Strategies
4. ICHI — Best for Single-Sided Deposits
Why Use It
ICHI's Yield IQ vaults revolutionize concentrated liquidity provision by accepting single-token deposits, eliminating the need for LPs to hold both sides of a trading pair. Using algorithmic strategies that maintain an 80:20 ratio, ICHI enables users to earn concentrated liquidity fees while effectively holding a single asset. Their Angel Vaults create buy-side liquidity that supports price stability for project tokens.
Best For
- LPs wanting single-token exposure without impermanent loss on both sides
- Projects seeking buy-side liquidity support
- Long-term holders wanting to earn yield without selling tokens
- DAOs managing treasury diversification
Notable Features
- Single-sided liquidity deposits (Angel Vaults and HODL Vaults)
- Automated rebalancing with Chainlink Keepers
- 80:20 asset ratio maintenance
- Support for 15+ AMMs across 10+ networks
- Integration with concentrated liquidity incentive programs
Consider If: 80:20 rebalancing means you'll still experience some token ratio changes; not pure single-asset exposure. Best for those comfortable with managed rebalancing.
Fees Notes: Varies by vault; performance fees typically 5-10% of yields
Regions: Global; available on multiple L1s and L2s
Alternatives: DefiEdge, Gamma Strategies
5. Beefy Finance CLM — Best for Yield Optimizer Integration
Why Use It
Beefy's Concentrated Liquidity Manager (CLM) extends their proven auto-compounding infrastructure to concentrated liquidity pools, providing automated range management integrated with Beefy's broader yield optimization ecosystem. Their "Cow Token" system converts non-fungible CL positions into fungible ERC-20 tokens while maximizing capital utilization through strategies that keep positions in-range and fully active.
Best For
- Existing Beefy users expanding into concentrated liquidity
- LPs seeking integrated yield farming and CLM
- Multi-chain passive investors
- Users wanting fungible CL position tokens
Notable Features
- Integration with Beefy's yield optimizer ecosystem
- Supports 15+ chains including BSC, Arbitrum, Polygon, Base, Avalanche
- Narrow and wide range strategies
- ERC-20 "Cow Tokens" for fungible CL positions
- Automatic fee compounding
Consider If: 9.5% harvest fee is higher than some competitors; suitable for long-term holders where compounding benefits outweigh fees.
Fees Notes: 9.5% performance fee on harvest; 0.5% to strategist; variable harvest call fee
Regions: Global; multi-chain support
Alternatives: Gamma Strategies, A51 Finance
6. DefiEdge — Best for Strategy Marketplace
Why Use It
DefiEdge creates a permissionless layer over concentrated liquidity AMMs where strategy managers can deploy custom strategies supporting up to 20 price ranges and built-in limit orders. This marketplace approach allows LPs to select from community-created strategies or deploy their own, providing unprecedented flexibility in concentrated liquidity management.
Best For
- Advanced LPs wanting custom multi-range strategies
- Strategy managers seeking to monetize their expertise
- Users requiring limit order functionality
- Projects needing tailored liquidity deployment
Notable Features
- Support for up to 20 simultaneous price ranges
- Built-in limit order functionality
- Permissionless strategy creation marketplace
- Real-time position monitoring interface
- Automatic integration with incentive protocols like Merkl
Consider If: More complex than single-strategy platforms; requires evaluating individual strategy manager performance.
Fees Notes: Varies by strategy manager; typically 5-15% performance fees
Regions: Global; primarily Ethereum, Polygon, Optimism, Arbitrum
Alternatives: A51 Finance, Gamma Strategies
7. Bunni — Best for Uniswap v4 Innovation
Why Use It
Bunni emerged as the leading Uniswap v4 hook implementation, using programmable Liquidity Density Functions (LDFs) to create custom liquidity shapes within concentrated ranges. Their Shapeshifting feature dynamically adjusts positions, while MEV protection through am-AMM auctions and Surge Fees recaptures value that would otherwise go to arbitrageurs. Bunni also rehypothecates idle capital to Aave and Yearn for additional yield.
Best For
- Early adopters of Uniswap v4 infrastructure
- LPs seeking MEV-protected concentrated liquidity
- Advanced users wanting programmable liquidity shapes
- Projects requiring dynamic fee structures
Notable Features
- Liquidity Density Functions for custom liquidity distribution
- Shapeshifting for dynamic position adjustment
- MEV protection via am-AMM mechanism and dynamic fees
- Rehypothecation to Aave/Yearn for additional yield
- Auto-compounding of fees and rewards
Consider If: Currently Ethereum-focused with Uniswap v4; may expand to other chains. Newer platform compared to established players like Gamma.
Fees Notes: Dynamic fees based on volatility and strategy; typical range 5-20% of yields
Regions: Global; Ethereum mainnet
Alternatives: Gamma Strategies (Uniswap v4 support), Arrakis Finance
8. Revert Finance — Best for Analytics-First Management
Why Use It
Revert Finance combines powerful analytics tools with automated management features, enabling LPs to backtest strategies, analyze top-performing positions, and then deploy automation like Auto-Range (automatic rebalancing) and Auto-Exit (stop-loss protection). Their Initiator tool allows LPs to simulate historical performance before committing capital, making Revert ideal for data-driven liquidity providers.
Best For
- Analytical LPs wanting to backtest before deploying
- Users seeking automated stop-loss protection (Auto-Exit)
- LPs wanting to copy successful positions
- Investors prioritizing transparency and performance tracking
Notable Features
- Comprehensive analytics suite with backtesting
- Auto-Range for automated rebalancing
- Auto-Exit for stop-loss automation
- Position management tools (add/withdraw/claim)
- Top Positions discovery for copying successful strategies
Consider If: Automation features (Auto-Range/Exit) charge 0.25% per operation; may not trigger if gas costs exceed fees. Best for larger positions.
Fees Notes: 2% auto-compound fee; 0.25% per auto-operation (Range/Exit); 0.65% swap fee
Regions: Global; Ethereum, Polygon, Optimism, Arbitrum
Alternatives: Gamma Strategies, Steer Protocol
9. A51 Finance — Best for Strategy Customization
Why Use It
A51 Finance (formerly Unipilot) offers autonomous liquidity provisioning with highly customizable parameters including market modes (Bull, Bear, Dynamic, Static), rebasing strategies, and liquidity distribution patterns. Supporting Uniswap v3/v4 and expanding to StarkNet, A51 empowers LPs to design advanced strategies using hooks while addressing loss-versus-rebalancing (LVR) through sophisticated hedging mechanisms.
Best For
- Advanced LPs wanting full strategy customization
- Multi-chain liquidity providers (EVM + StarkNet)
- Users requiring market-mode specific strategies
- Projects needing flexible liquidity allocation
Notable Features
- Market mode selection: Bull, Bear, Dynamic, Static
- Customizable rebasing and exit preferences
- Multiple liquidity distribution options (exponential, flat, single-tick)
- Hedging through borrowing and options
- Support for Uniswap v4 hooks
Consider If: Complexity requires deeper understanding of concentrated liquidity mechanics; best for experienced LPs.
Fees Notes: Varies by strategy; typically performance-based
Regions: Global; EVM chains and StarkNet
Alternatives: DefiEdge, Steer Protocol
10. Mellow Protocol — Best for Institutional Vaults
Why Use It
Mellow Protocol provides infrastructure for institutional-grade vaults with sophisticated curator models where professional risk managers and funds deploy strategies on behalf of LPs. While their focus has shifted toward broader vault infrastructure, Mellow's ALM toolkit remains integrated with Aerodrome and Velodrome, offering optimized range management with automated reward harvesting on SuperChain DEXs.
Best For
- Institutional LPs seeking professional management
- Aerodrome and Velodrome liquidity providers
- Users wanting curator-managed strategies
- Projects requiring compliance-ready vault infrastructure
Notable Features
- Institutional-grade vault infrastructure
- Integration with Aerodrome/Velodrome on Base and Optimism
- Curator marketplace with professional risk management
- Automated reward harvesting and compounding
- Audited by ChainSecurity and BlockSec
Consider If: Less focused on pure CLM compared to dedicated platforms; best for users seeking broader DeFi yield strategies including staking and lending.
Fees Notes: Varies by curator and vault; typically 10-20% performance fees
Regions: Global; primarily Ethereum, Optimism, Base, Arbitrum
Alternatives: Arrakis Finance, Gamma Strategies
Decision Guide: Best By Use Case
- Best for Multi-Chain Coverage → Gamma Strategies, Steer Protocol
- Best for Token Launches (TGE) → Arrakis Finance, ICHI (Angel Vaults)
- Best for Single-Sided Deposits → ICHI
- Best for Lowest Management Fees → Revert Finance (for analytics + selective automation)
- Best for Uniswap v4 Hooks → Bunni, Gamma Strategies
- Best for Analytics & Backtesting → Revert Finance
- Best for Institutional Management → Arrakis Finance, Mellow Protocol
- Best for Strategy Customization → A51 Finance, DefiEdge
- Best for BSC & Multi-Chain Yield → Beefy Finance CLM
- Best for Aerodrome/Velodrome on SuperChain → Mellow Protocol, Steer Protocol
How to Choose the Right Concentrated Liquidity Manager (Checklist)
Before selecting a CLM platform, verify:
- ☑ Chain Compatibility — Confirm the platform supports your target blockchain and DEX
- ☑ Strategy Alignment — Match strategy types (narrow/wide range, stable pairs, volatile pairs) to your goals
- ☑ Fee Structure Transparency — Understand performance fees, harvest fees, and withdrawal costs
- ☑ Track Record & TVL — Check operational history, total value managed, and security incidents
- ☑ Audit Status — Verify smart contracts have been audited by reputable firms
- ☑ Token Pairs Supported — Confirm your desired liquidity pools are available
- ☑ Rebalancing Frequency — Understand how often positions are rebalanced and gas cost implications
- ☑ Exit Flexibility — Check withdrawal timeframes, fees, and liquidity availability
- ☑ Performance Metrics — Review historical APRs accounting for impermanent loss
- ☑ Composability Needs — If using LP tokens elsewhere, verify ERC-20 support vs. NFTs
Red Flags:
- 🚩 No audits or anonymous teams without established track record
- 🚩 Unclear fee structures or hidden withdrawal penalties
- 🚩 Very high performance fees (>20%) without justified value-add
- 🚩 Limited chain support if you need multi-chain exposure
Use Token Metrics With Any Concentrated Liquidity Manager
Token Metrics complements your concentrated liquidity strategy by providing:
AI Ratings — Screen tokens for quality and momentum before selecting trading pairs for liquidity provision
Narrative Detection — Identify emerging DeFi themes early to position liquidity in high-growth sectors
Portfolio Optimization — Balance concentrated liquidity positions across chains and risk profiles
Alerts & Signals — Time liquidity entries and exits based on technical and on-chain indicators
Workflow Example:
- Research → Use Token Metrics AI to identify high-quality token pairs
- Select CLM → Choose appropriate concentrated liquidity manager based on chain and strategy
- Deploy → Provide liquidity through automated vault or custom range
- Monitor → Track performance with Token Metrics alerts for rebalancing or exit signals
Start free trial to screen assets and optimize your concentrated liquidity strategy with AI-powered insights.

Security & Compliance Tips
Protect Your Concentrated Liquidity Positions:
- Verify Contract Addresses — Always confirm official contract addresses on protocol documentation before depositing; bookmark official sites
- Check Audit Reports — Review smart contract audits from firms like Consensys, ChainSecurity, Hydn, or BlockSec before using new platforms
- Start Small — Test new CLM platforms with modest capital before committing significant liquidity
- Monitor Phishing — Be wary of fake CLM interfaces; never share seed phrases or sign suspicious transactions
- Understand Permissions — Review what approvals you're granting; consider using revoke.cash to audit token approvals
- Track IL Exposure — Concentrated liquidity amplifies impermanent loss; monitor positions regularly and understand divergence loss implications
- Diversify CLM Providers — Don't concentrate all liquidity with a single manager; spread risk across multiple audited platforms
- Check Rebalancing Limits — Understand if CLMs have daily rebalancing limits or gas thresholds that might delay adjustments
- Verify Withdrawal Process — Test small withdrawals to ensure liquidity is accessible and fees match expectations
- Stay Informed — Follow CLM protocol announcements for security updates, parameter changes, or migration requirements
This article is for research and educational purposes only, not financial advice. Always conduct your own due diligence and consider consulting with financial advisors before providing liquidity.
Beginner Mistakes to Avoid
- Ignoring Impermanent Loss — CLMs optimize fee generation but cannot eliminate IL; highly volatile pairs will still result in divergence loss
- Chasing High APRs Without Context — Displayed APRs often exclude impermanent loss and may reflect short-term incentives, not sustainable yields
- Not Understanding Fee Structures — Performance fees compound over time; a 15% fee on yields can significantly impact long-term returns
- Depositing Without Strategy Alignment — Narrow ranges earn higher fees but require more active management; ensure strategy matches your risk tolerance
- Overlooking Gas Costs — Rebalancing and compounding operations cost gas; on Ethereum mainnet, frequent rebalancing may erode returns for small positions
- Assuming "Set and Forget" — While automated, CLM positions require periodic review; market regime changes may necessitate strategy adjustments
- Not Tracking Net Performance — Always calculate returns vs. simply holding tokens; CLM fees + IL may underperform holding in ranging markets
- Concentrating in Illiquid Pairs — Low-volume pairs may have insufficient fee generation to cover management costs and rebalancing slippage
FAQs
What is a concentrated liquidity manager?
A concentrated liquidity manager (CLM) is a DeFi protocol that automates the management of concentrated liquidity positions on AMMs like Uniswap v3. CLMs handle range selection, rebalancing, fee compounding, and position optimization, converting active liquidity provision into a passive strategy. They typically provide ERC-20 LP tokens representing managed positions, making them composable across DeFi.
Are concentrated liquidity managers safe?
Security varies by platform. Established CLMs like Gamma Strategies, Arrakis, and Steer have multiple audits and years of operational history without major exploits. However, smart contract risk always exists; never deposit more than you can afford to lose, and prioritize audited platforms with proven track records. Review audit reports and monitor protocol security updates.
What fees do concentrated liquidity managers charge?
Most CLMs charge performance fees ranging from 5-15% of generated yields. Some add harvest fees (like Beefy's 9.5%), automation fees (Revert's 0.25% per operation), or swap fees for rebalancing. Always review the specific fee structure before depositing, as fees compound over time and can significantly impact net returns.
Which chains support concentrated liquidity managers?
Major CLMs support Ethereum, Polygon, Arbitrum, Optimism, and Base. Gamma Strategies leads with 20+ chains including BSC, Avalanche, Fantom, and newer L2s. Steer Protocol supports 17+ chains with 90%+ CLAMM coverage. Always verify your target chain is supported before selecting a CLM platform.
Can I use concentrated liquidity managers on mobile?
Most CLMs offer web interfaces compatible with mobile wallets like MetaMask Mobile, Coinbase Wallet, or WalletConnect. However, complex features like strategy backtesting (Revert) or custom position building may be better suited for desktop. Core functions like depositing, withdrawing, and monitoring positions work well on mobile.
Do CLMs work with Uniswap v4?
Yes. Gamma Strategies, Bunni, and A51 Finance support Uniswap v4, which launched in January 2025. Bunni is the leading v4 hook implementation, offering advanced features like Liquidity Density Functions. Arrakis is also developing v4 modules. Expect more CLMs to add v4 support as the protocol matures.
How do CLMs handle impermanent loss?
CLMs cannot eliminate impermanent loss—they optimize range management to maximize fee generation that can offset IL. Some platforms (Bunni, ICHI) offer specific strategies to mitigate IL through MEV protection or single-sided deposits, but divergence loss remains inherent to providing liquidity in volatile pairs.
What's the difference between CLMs and regular yield optimizers?
Regular yield optimizers (like Beefy for Uniswap v2) auto-compound rewards from liquidity mining programs. CLMs specifically manage concentrated liquidity positions, handling range selection and rebalancing. Some platforms (Beefy CLM) combine both, offering concentrated liquidity management integrated with yield optimization.
Conclusion + Related Reads
Concentrated liquidity managers have matured into essential DeFi infrastructure, transforming active LP strategies into accessible passive income opportunities. For multi-chain diversification and proven track record, Gamma Strategies remains the industry standard. Token launch teams and protocols requiring institutional-grade management should consider Arrakis Finance, while those seeking cutting-edge Uniswap v4 features can explore Bunni. LPs prioritizing single-sided deposits will find ICHI most suitable, and analytics-focused investors should evaluate Revert Finance.
Remember that no CLM eliminates impermanent loss—they optimize for fee generation and capital efficiency. Always verify fee structures, audit status, and supported chains before deploying capital. Start with smaller positions to understand platform mechanics and performance before scaling up.
Related Reads:

Best Crypto Liquidity Management & Market-Making Tools (2025)
Who this guide is for. Token teams, exchanges, funds, and DAOs comparing liquidity management and market-making tools to tighten spreads, balance inventories, and support healthy markets.
Top three picks.
- Flowdesk — compliance-first platform + MMaaS across 140+ venues. (flowdesk.co)
- Keyrock — full-stack liquidity (MM, OTC, LP mgmt, NFTs). (Keyrock)
- Wintermute — leading algorithmic liquidity partner across CeFi/DeFi. (wintermute.com)
One key caveat. Fees and engagement models vary widely (retainer, inventory loan/call, performance); confirm scope, reporting, and legal terms before signing. (flowdesk.co)
Introduction: Why Crypto Liquidity Management & Market-Making Tools Matter in November 2025
In crypto, liquidity management and market-making tools keep order books tight, reduce slippage, and stabilize price discovery across centralized and decentralized venues. The primary keyword here is liquidity management and market-making tools, and the right stack blends execution algorithms, risk controls, analytics, and clear reporting so projects can support listings and users can trade efficiently.
In 2025, onchain liquidity is increasingly concentrated and active on AMMs while institutions expect 24/7 coverage and API connectivity across spot, perps, and options. Mature providers now offer compliance-forward processes, automated vaults for concentrated liquidity, and multi-venue execution with transparent documentation. This guide ranks ten credible options, explains trade-offs (costs, custody, venues), and gives you a practical checklist to choose confidently.
Best Crypto Liquidity Management & Market-Making Tools in November 2025 (Comparison Table)

Evidence for venue coverage and capabilities appears in provider sections below.
Top 10 Crypto Liquidity Management & Market-Making Tools in November 2025
1. Flowdesk — Best for compliance-first MMaaS at global scale
Why Use It. Flowdesk runs a compliance-first market-making and OTC platform with proprietary execution algos and integrations across 140+ centralized and decentralized exchanges, suitable for token issuers that need unified coverage and reporting. (flowdesk.co)
Best For. Token issuers; exchanges; DAOs with multi-venue liquidity needs; teams prioritizing compliance.
Notable Features. Low-latency infrastructure; MMaaS with 24/7 teams; 140+ venue connectivity; internal policies & compliance center. (flowdesk.co)
Consider If. You want documented models (retainer vs loan/call) and clear KPIs before engagement. (flowdesk.co)
Fees Notes. Custom; contract-based; network/exchange fees apply.
Regions. Global; subject to local licensing and restrictions (France DASP registration referenced on site). (flowdesk.co)
Alternatives. Keyrock; GSR.

2. Keyrock — Best for full-stack liquidity (MM, OTC, LP, NFTs)
Why Use It. Keyrock delivers market making, OTC trading, treasury solutions, and liquidity pool management for token issuers and venues; it also offers NFT liquidity and publishes security awareness and terms. (Keyrock)
Best For. Issuers needing both CeFi and DeFi coverage; platforms adding NFT or LP liquidity.
Notable Features. Liquidity pool management; OTC/options; NFT liquidity; research/insights. (Keyrock)
Consider If. You want a single counterparty handling MM + LP mgmt with documented terms. (Keyrock)
Fees Notes. Custom; scope-based; network/exchange fees may apply.
Regions. Global; services subject to applicable laws and platform eligibility.
Alternatives. Flowdesk; Wintermute.

3. Wintermute — Best for algorithmic crypto liquidity at scale
Why Use It. Wintermute is a leading algorithmic trading firm and liquidity partner that supports efficient markets across centralized and decentralized venues, with a broader ventures arm for strategic projects. (wintermute.com)
Best For. Larger token issuers and institutions that want deep, programmatic liquidity and breadth of venues.
Notable Features. Algorithmic MM; OTC; venture support; expanding US presence. (fnlondon.com)
Consider If. You need institutional processes and policy engagement in the US market. (fnlondon.com)
Fees Notes. Custom; inventory/retainer structures typical.
Regions. Global.
Alternatives. GSR; FalconX.

4. GSR — Best for crypto liquidity + risk management depth
Why Use It. GSR offers market-making and risk management across spot and derivatives, working with exchanges, token issuers, and institutions; it publishes regular research and insights. (gsr.io)
Best For. Issuers seeking experienced MM with derivatives coverage and institutional process.
Notable Features. Trading + market making services; exchange connectivity; research hub. (gsr.io)
Consider If. You need structured reporting and risk frameworks across venues.
Fees Notes. Custom; scope-based; exchange/network fees apply.
Regions. Global.
Alternatives. Wintermute; Flowdesk.
5. FalconX — Best prime brokerage + deep crypto liquidity access
Why Use It. FalconX is a prime broker with $2T+ executed and access to 400+ tokens, offering unified spot/derivs/FX execution, OTC, and APIs (WebSocket/FIX/REST). (falconx.io)
Best For. Institutions wanting a single counterparty with RFQ, streaming, and FIX integration.
Notable Features. Deep liquidity pool; algorithmic/TWAP tools; ETF issuer liquidity support; Talos integrations. (falconx.io)
Consider If. You want prime services plus execution algos rather than a pure MM retainer.
Fees Notes. Custom; execution- and volume-based; venue/network fees apply.
Regions. Global (token availability may vary). (falconx.io)
Alternatives. Cumberland; GSR.
6. Cumberland (DRW) — Best for institutional OTC and options
Why Use It. A DRW subsidiary active since 2014 in digital assets, Cumberland provides 24/7 institutional liquidity across spot, listed derivatives, bilateral options, and NDFs, with relationship coverage. (cumberland.io)
Best For. Institutions needing OTC block liquidity and derivatives structures.
Notable Features. OTC/RFQ; BTC/ETH options; futures basis; DRW backing. (cumberland.io)
Consider If. You need large, bespoke trades and derivatives hedging under institutional processes.
Fees Notes. Custom; RFQ spreads/commissions; venue/network fees apply.
Regions. Global, subject to applicable regulations.
Alternatives. FalconX; Wintermute.
7. Auros — Best for HFT-driven market-making with bespoke design
Why Use It. Auros combines high-frequency trading and strategic market making across CeFi and DeFi with bespoke OTC and transparency-oriented reporting for token stability. (Auros)
Best For. Projects seeking a partner for token launch support and stability across venues.
Notable Features. HFT + MM stack; CeFi/DeFi coverage; insights & reporting. (Auros)
Consider If. You want tailored strategies and comms during volatility.
Fees Notes. Custom; scope-based; network/venue fees apply.
Regions. Global.
Alternatives. Kairon Labs; GSR.
8. Kairon Labs — Best issuer-focused market-making + advisory
Why Use It. Kairon Labs provides algorithmic market making, liquidity provision, partnerships, and advisory for issuers, with educational content on MM models (designated vs principal). (kaironlabs.com)
Best For. Small–mid cap issuers needing hands-on guidance plus execution.
Notable Features. Issuer-centric services; partnerships support; model education. (kaironlabs.com)
Consider If. You want advisory plus MM under one roof.
Fees Notes. Custom; scope-based; exchange/network fees apply.
Regions. Global.
Alternatives. Auros; Flowdesk.
9. Hummingbot — Best open-source framework for DIY market making
Why Use It. Hummingbot is an open-source Python framework to run automated strategies on any CEX/DEX, with built-in templates for pure market making and perpetual MM and extensive docs. (hummingbot.org)
Best For. Developers, quant hobbyists, and small desks wanting DIY automation.
Notable Features. Strategy library; Docker/API quickstarts; Miner rewards marketplace. (hummingbot.org)
Consider If. You accept self-hosting and operational overhead instead of a service contract.
Fees Notes. Software is free; trading/withdrawal/network fees still apply.
Regions. Global (open-source).
Alternatives. Arrakis (for LP vaults); Keyrock (for managed LP).
10. Arrakis Finance — Best for automated onchain LP management (Uni v3 & more)
Why Use It. Arrakis provides automated LP vaults and Arrakis Pro strategies for token issuers to manage concentrated liquidity with rebalancing and inventory targeting. (arrakis.finance)
Best For. Projects prioritizing DeFi AMM depth and capital efficiency on Uniswap v3-style DEXs.
Notable Features. Ongoing inventory management; automated rebalancing; issuer-specific vault programs. (arrakis.finance)
Consider If. You need onchain, non-custodial liquidity programs over CeFi MM retainers.
Fees Notes. Protocol/vault fees; gas costs on supported chains.
Regions. Global (onchain).
Alternatives. Hummingbot (DIY); GSR (CeFi/MM).
Decision Guide: Best By Use Case
- Regulated, compliance-first MMaaS: Flowdesk. (flowdesk.co)
- One-stop liquidity incl. NFTs & LP mgmt: Keyrock. (Keyrock)
- Algorithmic MM at institutional scale: Wintermute or GSR. (wintermute.com)
- Prime brokerage + FIX/WebSocket execution: FalconX. (falconx.io)
- OTC blocks + options structures: Cumberland (DRW). (cumberland.io)
- Launch support with HFT expertise: Auros. (Auros)
- Issuer-centric MM + advisory: Kairon Labs. (kaironlabs.com)
- DIY automation (open-source): Hummingbot. (hummingbot.org)
- Onchain concentrated liquidity programs: Arrakis Finance. (arrakis.finance)
How to Choose the Right Crypto Liquidity Management & Market-Making Tool (Checklist)
- Region eligibility & licensing: Confirm provider registrations and legal terms in your jurisdictions.
- Venue coverage: CeFi exchanges, perps venues, and DeFi AMMs you actually need.
- Inventory model: Retainer vs. inventory loan/call; required collateral and risks. (flowdesk.co)
- Execution stack: APIs (FIX/WebSocket/REST), algos, latency, and monitoring. (falconx.io)
- Onchain LP management: If DeFi-first, evaluate vault design, rebalancing, and transparency. (arrakis.finance)
- Reporting & SLAs: Daily/weekly liquidity KPIs, spread targets, uptime, incident process.
- Security & compliance: Insider-trading controls, conflict-of-interest policies, audits/policies page. (flowdesk.co)
- Costs & fees: Understand spread capture, performance fees, platform fees, and gas.
- Offboarding plan: Access to accounts, revocation of keys, vault migrations, and documentation.
Red flags: No written terms, vague reporting, or inability to name supported venues.
Use Token Metrics With Any Crypto Liquidity Provider
- AI Ratings to screen assets by quality and momentum before listings.
- Narrative Detection to catch early theme shifts that can impact liquidity.
- Portfolio Optimization to size inventory across chains and LPs.
- Alerts & Signals to time entries/exits and rebalance LP ranges.
Workflow: Research in Token Metrics → Select provider → Execute on-chain/CeFi → Monitor with alerts.
Start free trial to screen assets and time entries with AI.
Security & Compliance Tips
- Prefer partners that publish policies/compliance pages and name registrations. (flowdesk.co)
- Segregate exchange accounts and use least-privilege API keys; rotate regularly.
- For DeFi vaults, verify non-custodial design, fee schedules, and admin controls. (arrakis.finance)
- Confirm reporting cadence (inventory, spreads, volume, venue list).
- Use official domains and channels to avoid impersonation. (Keyrock)
- Understand engagement models (retainer vs loan/call) and associated risks. (flowdesk.co)
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Signing without clear KPIs (spread, depth, venue list).
- Ignoring region restrictions or licensing.
- Overlooking DeFi vault mechanics (rebalance rules, fees, inventories). (arrakis.finance)
- Mixing treasury and MM wallets without operational controls.
- Choosing CeFi-only when you need AMM depth (or vice versa).
- Underestimating implementation: APIs, custody, exchange listings, oracle feeds.
How We Picked (Methodology & Scoring)
We scored each provider using the following weights:
- Liquidity — 30% (depth, spreads, execution venues)
- Security — 25% (controls, disclosures, compliance posture)
- Coverage — 15% (CeFi/DeFi, spot/derivs, chain support)
- Costs — 15% (fee clarity, model fit, onchain costs)
- UX — 10% (integration, tooling, reporting)
- Support — 5% (24/7 coverage, responsiveness)
Data sources: official product, docs, pricing/terms, security/policies, and status pages; reputable market datasets used only to cross-check scale and venues. Last updated November 2025.
FAQs
What are liquidity management and market-making tools?
Software platforms and service providers that supply bids/asks, balance inventory, and manage onchain liquidity so markets remain liquid with tighter spreads and lower slippage (CeFi and DeFi).
Are managed market makers or DIY bots safer?
Managed providers handle execution, risk, and reporting under contracts; DIY bots like Hummingbot provide control but require operational expertise and monitoring. Choose based on team capacity and risk tolerance. (hummingbot.org)
How do providers charge?
Common models include retainers, inventory loan/call structures, execution fees/spreads, and protocol/vault fees on DeFi. Clarify model, caps, and KPI targets before engagement. (flowdesk.co)
Can I combine CeFi MM with DeFi vaults?
Yes. Many issuers use a CeFi MM for order books plus an onchain LP manager (e.g., Arrakis) for AMM depth, with shared reporting and risk limits. (arrakis.finance)
Do these tools work in the US/EU/APAC?
Most providers are global but subject to local regulations, listings, and counterparty restrictions. Check each provider’s terms/compliance pages and confirm venue eligibility. (flowdesk.co)
Conclusion + Related Reads
If you want compliance-centric, multi-venue coverage, start with Flowdesk or Keyrock. For institutional scale, add Wintermute or GSR. If you need prime services and execution, consider FalconX or Cumberland. For DIY or onchain-first, evaluate Hummingbot and Arrakis.
Related Reads (Token Metrics):


Get Your Brand in Front of 150,000+ Crypto Investors!

9450 SW Gemini Dr
PMB 59348
Beaverton, Oregon 97008-7105 US
.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Products
Subscribe to Newsletter
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.