



Avalanche (AVAX) Price Prediction 2025, 2030 - Forecast Analysis
%201.svg)
%201.svg)

In the ever-evolving world of cryptocurrencies, Avalanche (AVAX) has emerged as a prominent player. With its unique algorithm and features, AVAX has gained popularity among investors and traders alike.
Many people are now wondering what the future holds for Avalanche and whether its price will continue to rise.
In this article, we will delve into the various factors that can influence the price of AVAX and provide a comprehensive analysis of its price prediction for the coming years.
Avalanche (AVAX) Overview
Before we dive into the price prediction, let's take a moment to understand what Avalanche is all about. Avalanche is a decentralized smart contract platform that aims to be fast, affordable, and eco-friendly.
It utilizes a native utility token called AVAX, which serves as the primary medium of exchange within the ecosystem. The maximum supply of AVAX is capped at 720 million, with 360 million initially minted and sold through private and public sales. The remaining 360 million tokens are distributed as staking rewards over time.
Avalanche stands out from other blockchain networks due to its heterogeneous network of blockchains and validator sets. It uses a proof-of-stake (PoS) consensus mechanism, assisted by the unique Avalanche consensus protocol.
This protocol provides a scalable and secure environment for transactions, smart contracts, and network administration.
Historical Performance of Avalanche (AVAX)
To gain insights into the potential future price movements of AVAX, it is crucial to analyze its historical data. Over the past year, AVAX has experienced both bullish and bearish trends.

Starting from October 2022, the price of AVAX gradually declined, reaching a low of around $8.9, and it rebounded briefly in the few trading sessions in the last one year, touching a peak resistance at $21.51 at the beginning of 2023. Currently trading around $17.8
Avalanche (AVAX) Current Fundamentals
Before making any price predictions, it is essential to consider the current fundamentals of Avalanche. As of now, the price of AVAX stands at $17.8 with a market cap of $6,333,154,506.
The latest trading price for AVAX is $17.8, and the AVAX market is displaying a Fear & Greed Index of 65 (Greed). Over the past 30 days, AVAX has experienced 18 green days out of 30, indicating a positive trend. The volatility of AVAX is currently at 8.43%.
Avalanche (AVAX) Price Prediction - Scenario Analysis
To make accurate price predictions, it is crucial to consider different scenarios that can impact AVAX's price. Let's analyze two scenarios - a bullish and a bearish- to understand the potential price movements of AVAX better.
AVAX Price Prediction - Bullish Scenario
If the crypto market cap hits $3 Trillion, and if AVAX retains its current 0.41% dominance, its price could ascend to $34.67
In a more bullish scenario of the crypto market surging to $10 Trillion, AVAX's price could soar to a staggering $115.57, resulting in a potential 7x return for investors.
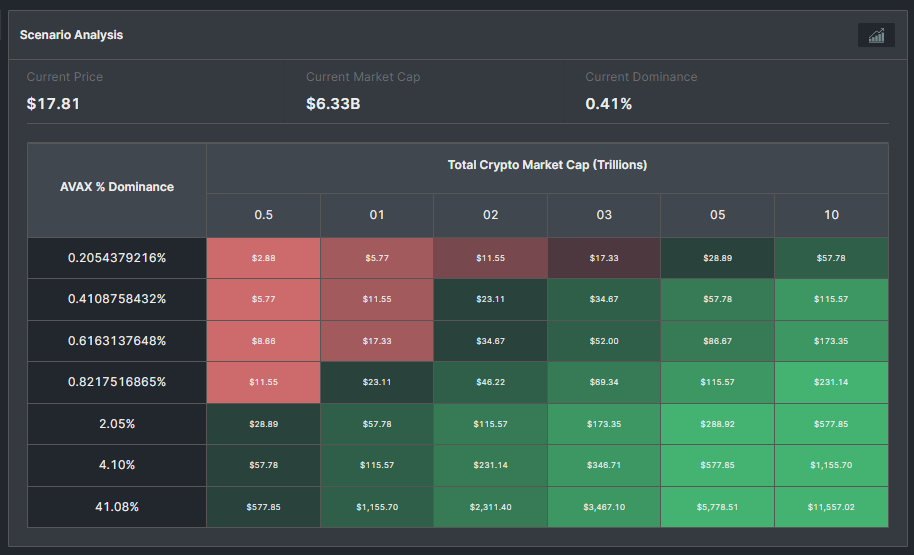
AVAX Price Prediction - Bearish Scenario
In a bearish scenario, where market conditions are unfavorable or there is increased competition, the price of AVAX may face downward pressure with a decreased dominance of 0.20%.
In this scenario, If the crypto market cap hits $3 Trillion, AVAX could trade around $17.33 in the short term and struggle to surpass $57.78 by 2030 even if the total crypto market cap surpasses the $10 Trillion mark.
It is essential to note that these scenarios are speculative and should not be considered financial advice. The cryptocurrency market is highly volatile, and prices can fluctuate rapidly.
Avalanche (AVAX) Price Prediction - Industry Expert Opinion
To gain further insights into AVAX's future price movements, it is essential to consider the opinions of industry experts. While price predictions can vary, many experts believe that AVAX has the potential for significant growth in the coming years.
Coincodex.com platform predicts Avalanche (AVAX) could reach $ 63.40 to $ 80.24 by 2030, and experts from Changelly forecast that it could reach minimum and maximum prices of $30.04 and $34.85 by the end of 2025. By the end of 2030, the price of AVAX could reach $185.25 to $221.39
Other industry analysts have varying opinions on the future price of AVAX. Ambcrypto.com predicts that Avalanche (AVAX) could reach $28.15 to $42.23 in 2030.
This long-term projection and an optimistic outlook are based on the belief that AVAX's ongoing developments and growing adoption will drive its value.
Note - Start Your Free Trial Today and Uncover Your Token's Price Prediction and Forecast on Token Metrics.
Is Avalanche (AVAX) Good to Invest?
Investing in cryptocurrency carries certain risks, including market volatility and regulatory uncertainty. However, many investors see potential in Avalanche due to its unique features, fast transaction speed, and the growing popularity of decentralized finance (DeFi) applications.
Before making any investment decisions, conducting thorough research, assessing your risk tolerance, and consulting with a financial advisor are crucial.
Risks and Rewards
As with any investment, risks and rewards are associated with investing in AVAX. The rewards of investing in AVAX include the potential for significant price appreciation, especially if the platform continues to gain adoption and attract more users.
Additionally, AVAX holders can earn staking rewards by participating in the network's proof-of-stake consensus mechanism.
However, it's important to note that investing in AVAX also carries risks. The cryptocurrency market is highly volatile, and AVAX's price can fluctuate quickly.
Regulatory changes, security breaches, and market sentiment can all impact AVAX's price. It's crucial to carefully assess these risks before making any investment decisions.
Ongoing Developments and Future Potential of Avalanche
Avalanche has been making significant strides in terms of development and partnerships. The platform has attracted several high-profile projects and collaborations, contributing to its growing ecosystem.
Ongoing developments, such as upgrades to the network and the introduction of new features, can further enhance the functionality and appeal of Avalanche.
Additionally, Avalanche's focus on scalability, affordability, and eco-friendliness positions it well to capitalize on the growing demand for decentralized applications and the broader adoption of blockchain technology. As the cryptocurrency market continues to evolve, Avalanche's potential for future growth remains promising.
Conclusion
In conclusion, Avalanche (AVAX) has shown strong potential as a decentralized smart contract platform. While price predictions can vary, it's clear that AVAX has the potential for significant growth in the coming years.
Investors should carefully consider the risks and rewards of investing in AVAX and conduct thorough research before making investment decisions. As with any investment, it's important to stay informed, diversify your portfolio, and consult with a financial advisor.
Frequently Asked Questions
Q1. How much will AVAX be worth in the future?
AVAX's future value will depend on market trends, adoption rates, technological developments, and overall crypto market health. In a bullish scenario of the total crypto market surging to $10 Trillion, AVAX's price could soar to a staggering $115.57.
Q2. What will Avalanche be worth in 2030?
Predicting Avalanche's 2030 value is speculative. The long-term price depends on adoption, tech innovation, and crypto ecosystem changes. Changelly forecast that, by the end of 2030, the price of AVAX could reach $185.25 to $221.39
Q3. Why is AVAX dropping?
AVAX may drop due to market volatility, negative news of recent security breaches, sell-offs, or broader economic factors impacting the cryptocurrency markets.
Q4. Is AVAX a good project?
Many consider AVAX a good project due to its fast transaction speeds, low fees, and eco-friendly proof-of-stake consensus mechanism.
Q5. What factors can affect the price of AVAX?
AVAX's price is influenced by market sentiment, adoption rates, network upgrades, regulatory news, and the performance of decentralized applications on its platform.
Q6. How can I analyze Avalanche price movements?
Analyzing Avalanche (AVAX) price movements and studying market trends is simple. You can check the Token Metrics platform for all the data, bullish and bearish trends, project tokenomics, and short-term price predictions, all in one place.
Q7. What do industry experts say about AVAX's future?
Industry experts are optimistic about AVAX's future, citing its strong development team, innovative technology, and growing ecosystem of applications.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other advice, and you should not treat any of the website's content as such.
Token Metrics does not recommend that any cryptocurrency should be bought, sold, or held by you. Conduct your due diligence and consult your financial advisor before making investment decisions.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.