



Best Crypto API: Power Your Apps with Data, Signals, and AI
%201.svg)
%201.svg)


What Makes a Crypto API the “Best”?
The best cryptocurrency API isn’t just about raw data. It’s about empowering your application to perform faster, smarter, and more reliably. A truly great crypto API balances:
- Depth of Coverage – Spot, DeFi tokens, and on-chain metrics.
- Speed – Real-time, low-latency updates that can handle market volatility.
- Intelligence – Analytics and AI-driven signals that go beyond price feeds.
- Scalability – Infrastructure that grows with your user base.
- Reliability – High uptime and SLA-backed performance guarantees.
Whether you’re building a high-frequency crypto trading bot, a DeFi portfolio tracker, or a research platform, choosing the right API means aligning features with your mission.
Key Features to Look for in a Crypto API
Before selecting a crypto API, evaluate these criteria:
- Real-Time & Historical Data – Do you get both sub-second updates and multi-year backtesting datasets?
- On-Chain Analytics – Can you track wallet behavior, liquidity shifts, or whale flows?
- AI-Powered Insights – Does the API offer predictive signals, ratings, or trend forecasts?
- Ease of Integration – Look for clean docs, SDKs, and community examples.
- Reliability & Uptime – Providers should publish incident histories and SLA commitments.
- Pricing & Scalability – Free tiers for testing, plus paid plans that make sense as you scale.
- Compliance & Security – Encrypted endpoints and strong authentication are a must.
📌 Tip for builders: Always start with multiple free crypto APIs and benchmark them in your stack before committing long term.
Comparing Leading Crypto APIs: Strengths & Weaknesses

- CoinGecko & CoinMarketCap
- Strengths: Huge token coverage, easy for price tickers and charts.
- Weaknesses: Limited historical and on-chain analytics, slower refresh rates.
- Strengths: Huge token coverage, easy for price tickers and charts.
- CryptoCompare
- Strengths: Deep historical trade data, useful for backtesting.
- Weaknesses: Less emphasis on predictive insights or AI.
- Strengths: Deep historical trade data, useful for backtesting.
- Glassnode
- Strengths: Advanced on-chain metrics (network health, wallet flows).
- Weaknesses: Best for researchers, less suited to trading bots or dashboards.
- Strengths: Advanced on-chain metrics (network health, wallet flows).
- Alchemy & Infura
- Strengths: Node-level blockchain access, ideal for dApps and DeFi projects.
- Weaknesses: Provide raw blockchain data, not trading analytics.
- Strengths: Node-level blockchain access, ideal for dApps and DeFi projects.
- Token Metrics API
- Strengths: Combines real-time prices, AI trading signals, ratings, portfolio analytics, and on-chain intelligence in one API.
- Weaknesses: Free tier has rate limits (scalable through paid plans).
- Strengths: Combines real-time prices, AI trading signals, ratings, portfolio analytics, and on-chain intelligence in one API.
Why Token Metrics API Stands Out
Most crypto APIs specialize in one dimension (prices, exchange data, or on-chain metrics). Token Metrics unifies them all and adds AI intelligence on top.
- Comprehensive Coverage – Prices, historical datasets, indices, grades, and on-chain data.
- AI Trading Signals – Unique bull/bear calls and predictive analytics unavailable in traditional APIs.
- Portfolio Intelligence – Ratings and indices that give context to raw numbers.
- Enterprise-Ready – Encrypted endpoints, authentication, and scalable infrastructure.
- Developer Friendly – Clear docs, quick-start guides, and responsive support.
📌 Put simply: most crypto APIs give you data. Token Metrics gives you data + intelligence.

Use Cases: From AI Crypto Trading Bots to Research Dashboards
- AI Trading Bots – Execute strategies using both real-time prices and predictive signals.
- DeFi Dashboards – Aggregate wallet flows, liquidity data, and token ratings.
- Crypto Research Tools – Combine historical OHLC data with Token Metrics grades.
- AI Agents – Power AI apps with actionable signals, not just raw feeds.
- Enterprise Analytics – Build institutional dashboards with indices and compliance-ready datasets.
Best Practices for Implementing a Crypto API
- Prototype Across Providers – Test CoinGecko, Token Metrics, and others in parallel.
- Abstract Your Integration – Use a middleware layer to make switching APIs easier.
- Secure Your Keys – Store credentials safely and rotate them regularly.
- Plan for Scale – Rate limits hit fast; design for bursts in traffic.
- Leverage AI-Enhanced APIs – This is where user expectations are heading.
📌 For production apps: always monitor crypto API latency and uptime with tools like Datadog or Grafana.
Beyond Token Metrics: Other Useful Resources
While Token Metrics API offers an all-in-one solution, developers can also explore other resources for specialized needs:
- Dune Analytics – Great for custom SQL-based blockchain queries.
- DefiLlama API – Free API focused on DeFi protocol yields and TVL.
- Santiment API – Alternative on-chain and sentiment analytics.
- TradingView – Charting and integration options for front-end visualizations.
📌 Strategy tip: many developers combine multiple APIs—Token Metrics for signals + CoinGecko for breadth + DefiLlama for yields—to cover all angles.

Frequently Asked Questions About Crypto APIs
Which crypto API is best overall?
If you want real-time data plus AI-powered insights, crypto api is used. Token Metrics Api is the strongest all-in-one option. For niche use cases, CoinGecko is good for prices, Glassnode for on-chain analytics.
Is Token Metrics API free?
Yes, the free tier is perfect for prototyping. Paid plans unlock faster throughput, more history, and advanced endpoints.
How is Token Metrics different from CoinGecko?
CoinGecko tracks prices broadly. Token Metrics layers AI signals, indices, and predictive analytics for trading and research.
Can I build a trading bot with Token Metrics API?
Yes—many developers use the low-latency price feeds and predictive signals to power automated strategies.
Scaling With Paid Plans and X.402
As your project grows, Token Metrics offers flexible upgrade paths:
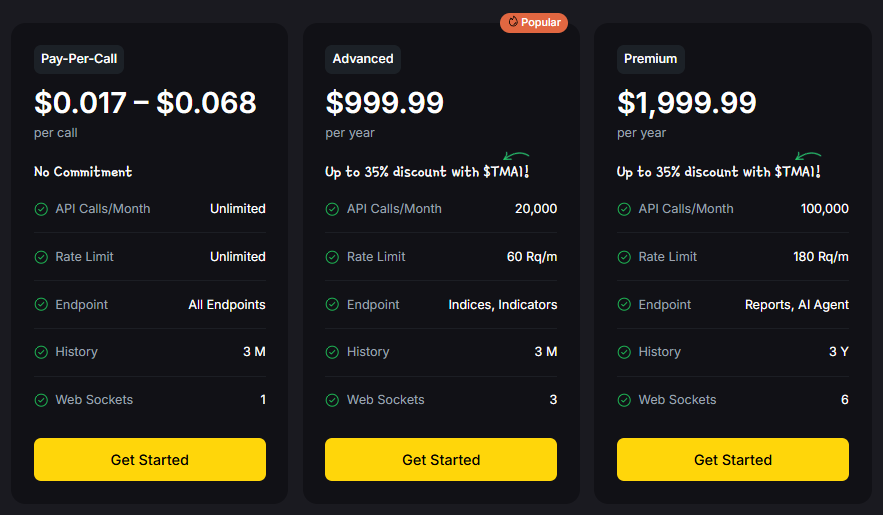
- Pay-Per-Call (X.402) – As low as $0.017 per call, no commitment. Unlimited calls, all endpoints, and 3 months of historical data.
- Advanced Plan ($999.99/year) – 20,000 calls/month, access to indices & indicators, 3 WebSockets.
- Premium Plan ($1,999.99/year) – 100,000 calls/month, all endpoints including AI Agent & Reports, 3 years of historical data, and 6 WebSockets.
With up to 35% discounts when paying in TMAI tokens, scaling is cost-efficient.
📌 Why X.402 matters: Instead of locking into an annual plan, you can scale gradually with pay-per-call pricing—perfect for startups and experimental apps.
Build Smarter, Scale Easier
The best crypto API doesn’t just serve data—it helps your app think, act, and adapt. With Token Metrics, you start free, learn fast, and scale seamlessly. Combine it with other specialized APIs when needed, and you’ll have a development stack that’s both powerful and future-proof.
👉 Grab Your Free Token Metrics API Key and Start Building
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.