



Bullish vs Bearish - A Comparative Analysis of Market Trends
%201.svg)
%201.svg)


When it comes to investing, bullish and bearish are two terms that investors often come across. These two terms are used to describe the market outlook or individual asset, and understanding their fundamental differences is crucial for making informed investment decisions.
In this article, we will delve deeper into the meanings and differences between Bullish and Bearish trends. So, buckle up and keep reading to learn more about the fundamental differences between the two.
What is the Bullish Trend?
The bullish trend is a term used in financial markets to describe a positive or optimistic outlook on the market or a particular asset like stocks or crypto. In a bullish trend, the market or asset is experiencing a steady increase in value, with buyers outnumbering sellers.
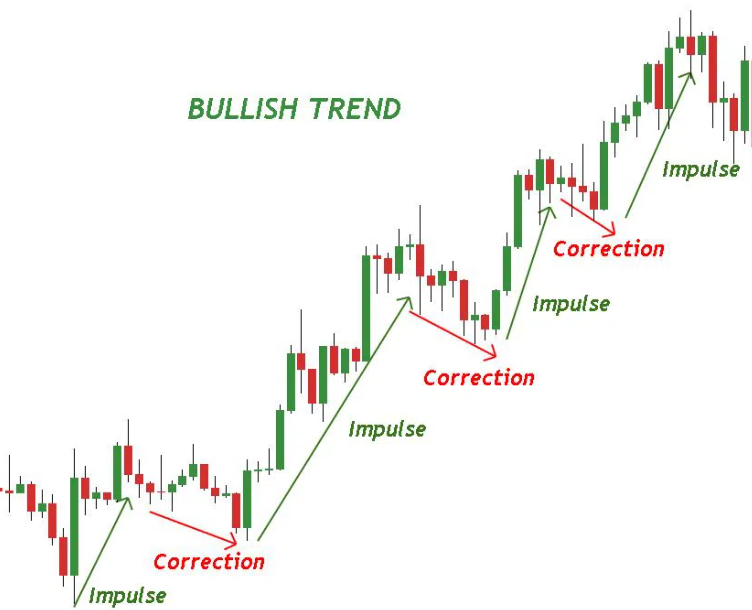
This often results in higher stock or crypto prices, increased trading volumes, and positive sentiment among investors. The bullish trend can be influenced by a variety of factors, including strong earnings growth, a positive economic outlook, and favorable government policies.
What is the Bearish Trend?
The bearish trend is a term commonly used in financial markets to describe a negative or pessimistic outlook on the market or a particular asset. Unlike the bullish trend, which is characterized by an increase in value, the bearish trend is marked by a decrease in value, lower stock/crypto prices, and negative sentiment among investors.

This bearish trend can be influenced by a variety of factors, including economic downturns, declining earnings, and unfavorable policies and regulations.
Bullish vs Bearish - Fundamental Differences
Now that we have understood the basic definitions let's look at the fundamental differences between the two.
1. Market Sentiment - The primary difference between Bullish and Bearish trends is the market sentiment. Bullish trends indicate positive sentiments, whereas Bearish trends indicate negative sentiments. The market sentiment is often driven by various factors such as economic conditions, political events, and company performance.
2. Price Movement - Another significant difference between Bullish and Bearish trends is the direction of price movement. In a Bullish trend, the prices of assets rise steadily, while in a Bearish trend, prices fall.
3. Trading Volume - The trading volume is an important indicator of market trends. A higher trading volume is often associated with Bullish trends, indicating increased investor participation and positive sentiment. On the other hand, a lower trading volume is often associated with Bearish trends, indicating decreased investor participation and negative sentiment.
4. Investor Behavior - Investor behavior is also an important factor that distinguishes Bullish and Bearish trends. In a Bullish trend, investors are more likely to buy digital assets, hoping to sell them at a higher price in the future. In contrast, in a Bearish trend, investors are more likely to sell digital assets, fearing a further decline in prices.
5. Timeframe - The duration of Bullish and Bearish trends can vary significantly. Bullish trends can last for months or even years, while Bearish trends can also last for extended periods.
6. Implications - Bullish and Bearish trends have significant implications for investors. A Bullish trend indicates a positivity for the market, leading to increased investments and higher asset prices. On the other hand, a Bearish trend indicates a negative approach, leading to decreased investments and lower asset prices.
How to Analyze Bullish and Bearish Patterns?
Analyzing bullish and bearish patterns is a key component of successful investing. To identify these patterns, investors use technical analysis, which involves examining charts and data to determine market trends.
Bullish patterns may include higher highs and higher lows, while bearish patterns may include lower highs and lower lows. Other indicators that investors may look for include support and resistance levels, moving averages, and volume.
It's important to note that these patterns are not foolproof and should be used in conjunction with fundamental analysis, which involves examining a company's financial health and other factors that may impact its future growth prospects.
Examples of Bullish and Bearish Trend
Over time, the market has witnessed numerous bullish and bearish trends, with some being particularly noteworthy. Let's take a look at some real-life examples of such trends in the market.
Example of Bullish Trend - In late 2017, the price of Bitcoin experienced an unprecedented surge, rising from around $1,000 at the beginning of the year to nearly $20,000 by December. This was fueled by increased interest and adoption of cryptocurrencies, particularly by institutional investors. The bullish trend continued into early 2018, with the total market capitalization of all cryptocurrencies reaching an all-time high.
Example of Bearish Trend - One classic example of a bearish trend in Ethereum was the period from January 2018 to December 2018. During this time, the price of Ethereum experienced a significant correction, dropping from an all-time high of around $1,400 in January 2018 to around $85 by December 2018.
This bearish trend was fueled by several factors, including the general market downturn, concerns over scalability and network congestion, and increased competition from other blockchain projects. However, since then, Ethereum has seen a recovery and has undergone significant upgrades, such as the transition to Ethereum 2.0, which has increased interest and adoption of the platform.
Frequently Asked Questions (FAQs)
1. How can I identify a Bullish or Bearish trend?
You can identify a Bullish or Bearish trend by analyzing the price movements and trading volumes of the asset over a specific period. If the prices are rising, and the trading volumes are high, it indicates a Bullish trend. Conversely, if the prices are falling, and the trading volumes are low, it indicates a Bearish trend.
2. How can I profit from a Bullish or Bearish trend?
You can profit from a Bullish or Bearish trend by buying or selling assets at the right time. In a Bullish trend, you can buy stocks at a lower price and sell them at a higher price when the trend ends. In a Bearish trend, you can sell stocks at a higher price and buy them back at a lower price when the trend ends.
3. Is it possible to have a Bullish and Bearish trend at the same time?
Yes, it is possible to have a Bullish and Bearish trend in different sectors of the market simultaneously. For instance, the technology sector can have a Bullish trend while the energy sector has a Bearish trend.
4. How do market trends impact my investments?
Market trends have a significant impact on your investments. If you invest during a Bullish trend, you are more likely to see positive returns. In contrast, if you invest during a Bearish trend, you may incur losses.
5. How can I prepare for market trends?
You can prepare for market trends by staying updated with economic and political news that impact the market. Additionally, you can diversify your portfolio to minimize risks and invest in long-term assets.
6. Can Bullish and Bearish trends change quickly?
Yes, market trends can change quickly, and it's crucial to stay updated with the latest news and trends. It's advisable to set stop-loss orders to minimize losses during sudden market changes.
The Bottom Line
In conclusion, understanding the fundamental differences between bullish and bearish sentiment can be helpful in making informed investment decisions. By considering economic indicators, company-specific news, and your own investment goals and risk tolerance, you can determine whether you're bullish or bearish on a particular asset or the overall market.
Remember that while these views can be useful, they are not infallible, and it's important to remain vigilant and adaptable in a constantly evolving market. Investing involves risks, and it's essential to consult a financial advisor before making any investment decisions.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other sort of advice and you should not treat any of the website's content as such.
Token Metrics does not recommend that any cryptocurrency should be bought, sold, or held by you. Do conduct your own due diligence and consult your financial advisor before making any investment decisions.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)
Recent Posts







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.