



Crypto HODL: The Long-Term Investment Strategy for Building Wealth in 2025
%201.svg)
%201.svg)

Introduction to HODL
If you’ve spent any time in cryptocurrency communities, you’ve likely seen the term HODL. Originally a misspelling of “hold” on an online Bitcoin forum in 2013, HODL has become much more than a typo—it’s now a core investment philosophy for crypto enthusiasts worldwide.
In 2025, HODLing remains one of the most effective long-term strategies for building wealth in cryptocurrency. By holding onto fundamentally strong assets through market volatility, investors can capture long-term gains while avoiding emotional, short-term trading mistakes. This article explores what HODLing means, why it works, the best assets to HODL, and how platforms like Token Metrics can help optimize your strategy.
What Does HODL Mean?
HODL means buying and holding cryptocurrency for an extended period, regardless of short-term price fluctuations. Unlike traders who attempt to time the market, HODLers adopt a long-term mindset, trusting that the value of quality assets will increase over time.
This strategy is rooted in the belief that blockchain technology and digital assets are here to stay, and that short-term market noise shouldn’t derail long-term conviction.
The Psychology Behind HODLing
Crypto markets are notoriously volatile, with sudden price swings that can lead to emotional decision-making. HODLing combats this by:
- Avoiding Panic Selling: Reducing the risk of selling at a loss during downturns.
- Maintaining Discipline: Encouraging investors to stick to their long-term plans.
- Embracing Market Cycles: Understanding that crypto goes through bull and bear phases, but strong assets tend to recover and grow over time.
By committing to HODLing, investors can overcome emotional biases and stay focused on their long-term goals.
Why HODL Works in 2025
- Capturing Long-Term Gains:
Historically, assets like Bitcoin and Ethereum have rewarded long-term holders with substantial returns, despite short-term volatility. - Lower Trading Costs:
By minimizing active trading, HODLers save on transaction fees and reduce tax implications from frequent trades. - Compounding Growth:
Holding allows you to benefit from price appreciation and participate in opportunities like staking or earning yield on your crypto. - Simplicity:
HODLing is straightforward—buy quality assets, store them securely, and wait.
Best Cryptocurrencies to HODL in 2025
While any coin can be HODLed, the best long-term candidates are projects with strong fundamentals, proven track records, and growing ecosystems:
- Bitcoin (BTC):
Known as digital gold, Bitcoin remains the most secure and widely adopted cryptocurrency, making it a cornerstone of any HODL portfolio.
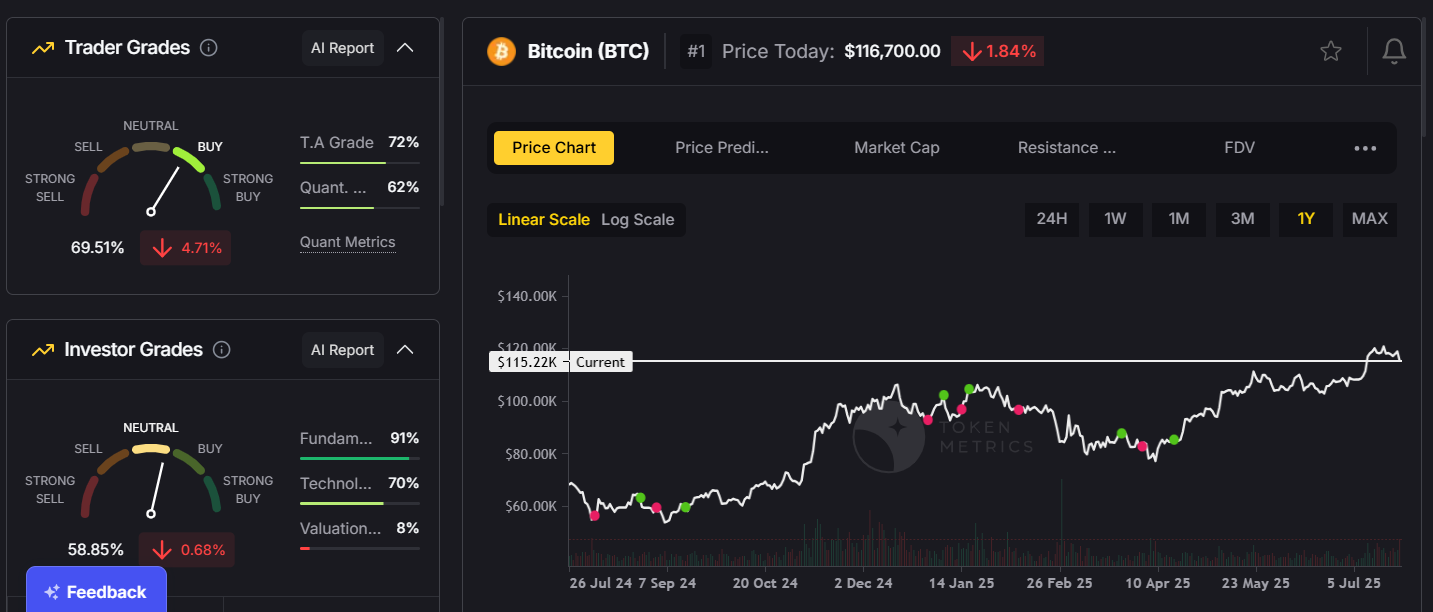
- Ethereum (ETH):
As the leading smart contract platform, Ethereum powers thousands of decentralized applications and remains a dominant force in DeFi and NFTs.
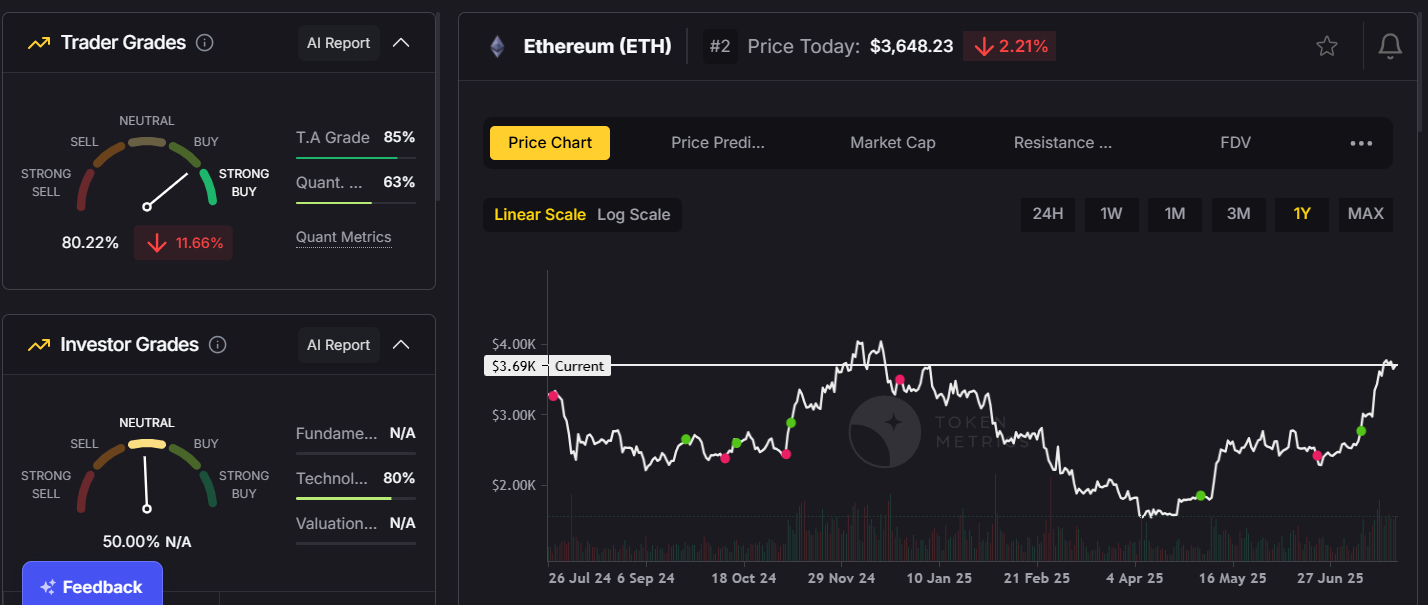
- Token Metrics AI (TMAI):
An innovative AI-driven analytics token that combines blockchain and artificial intelligence, helping investors make smarter decisions.
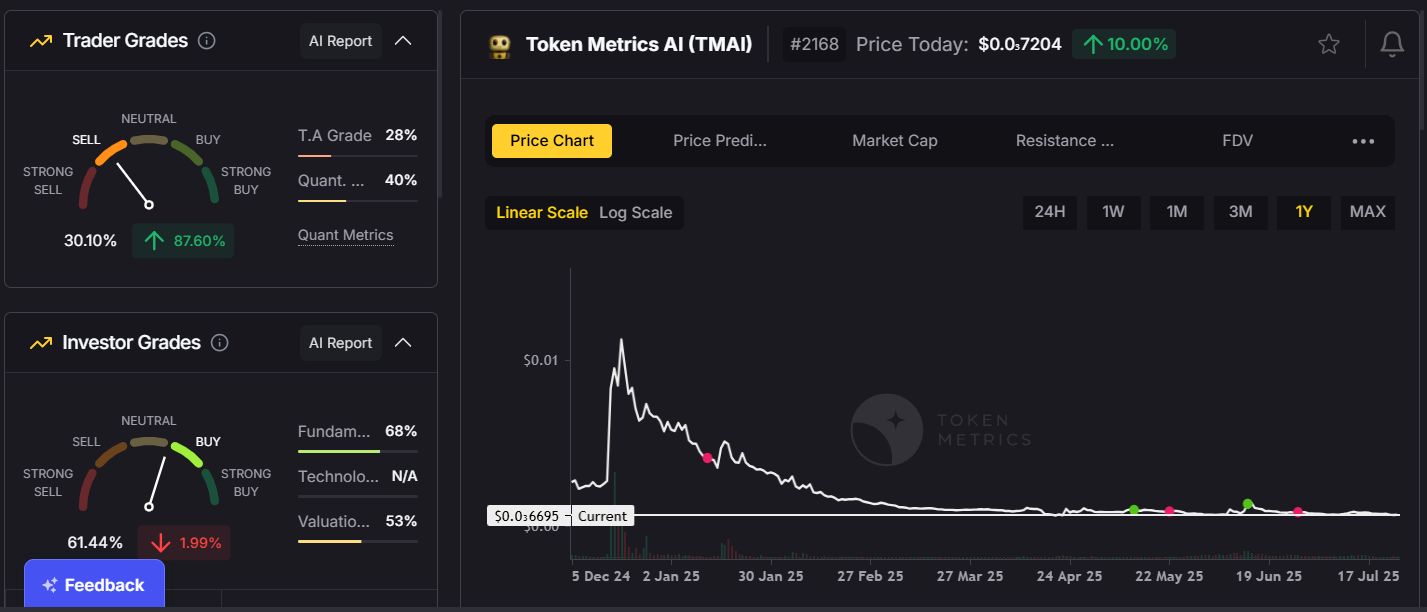
- Polygon (MATIC) and Arbitrum (ARB):
Scaling solutions with growing adoption and strong developer ecosystems.
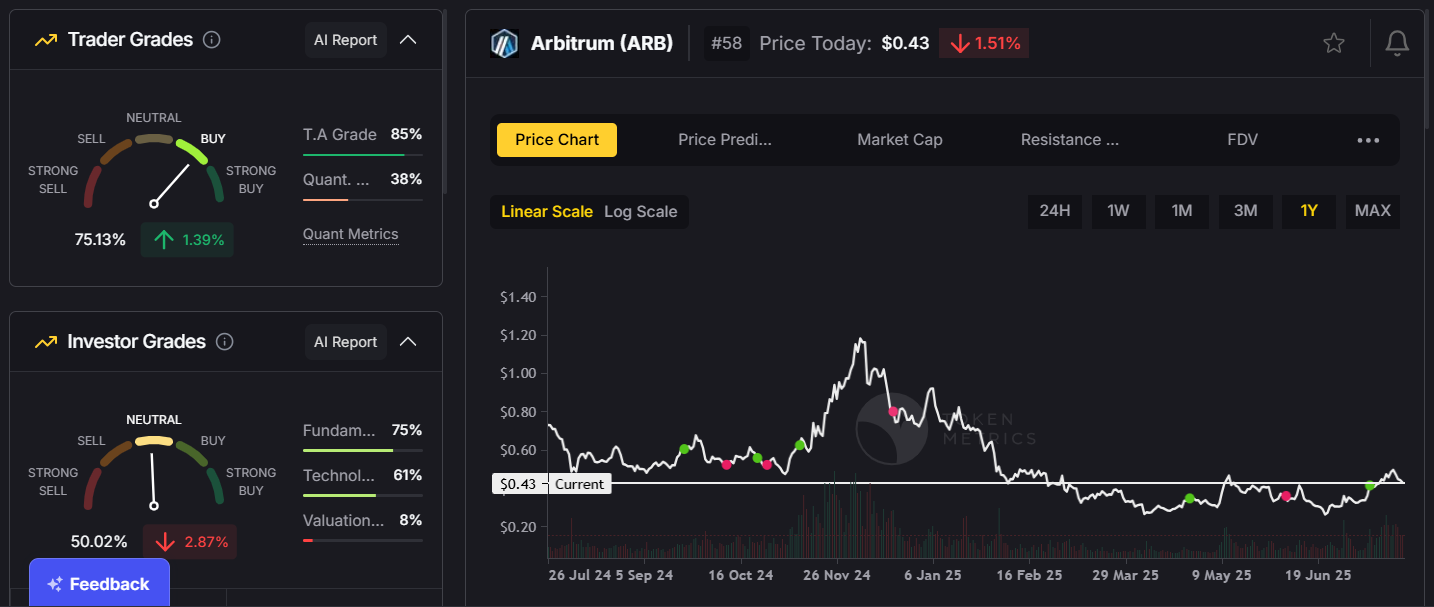
These coins offer long-term growth potential, making them excellent candidates for a HODL strategy.
How to Build a Successful HODL Strategy
- Do Your Research:
Focus on coins with real-world utility, active development teams, and strong communities. - Diversify Your Holdings:
Don’t put all your funds into one asset. Balance between large-cap (BTC, ETH) and emerging tokens (AI coins, Layer 2 solutions). - Use Token Metrics for Insights:
Leverage AI-powered analytics to evaluate assets, get coin ratings, and track portfolio performance. Token Metrics provides data on over 80 key metrics per token, helping you choose the right assets to HODL. - Secure Your Assets:
Use hardware wallets for long-term storage and enable two-factor authentication (2FA) on exchange accounts. - Rebalance Periodically:
While HODLing implies holding for the long term, periodic rebalancing ensures your portfolio remains aligned with your investment goals.
HODLing vs. Active Trading
While active trading can generate quick profits, it also comes with higher risks and costs. Here’s how HODLing compares:
- Less Stressful: You’re not glued to charts or reacting to every market dip.
- Lower Fees: Fewer transactions mean reduced trading costs.
- Higher Long-Term Success: Most active traders underperform long-term HODLers over extended periods.
Platforms like Token Metrics can complement both approaches by providing trading signals and long-term portfolio analytics, helping you decide when (and if) you should adjust your positions.
Risks of HODLing
While HODLing is effective, it’s not without challenges:
- Extended Bear Markets: Prices may stay low for months or years.
- Project Failures: Some tokens may not survive long term, making research critical.
- Opportunity Cost: Holding may cause you to miss out on short-term trading opportunities.
To mitigate these risks, rely on data-driven tools like Token Metrics to ensure you’re holding the right mix of assets.
The Role of Token Metrics in HODLing
Token Metrics is a powerful platform for long-term crypto investors, providing:
- AI-Driven Coin Ratings: Helping you identify which assets are worth holding.
- Trend Analysis: Detecting when market conditions shift.
- Portfolio Optimization: Offering insights to keep your HODL strategy on track.
By leveraging AI analytics, Token Metrics makes HODLing smarter, ensuring you’re invested in assets with strong fundamentals and growth potential.
Practical Tips for HODLers
- Start with Blue Chips: Build a foundation with Bitcoin and Ethereum.
- Add Growth Assets: Include promising altcoins like TMAI and Layer 2 scaling tokens.
- Ignore Market Noise: Stay focused on the big picture.
- Set Clear Goals: Define your time horizon and risk tolerance.
- Stay Informed: Use platforms like Token Metrics to monitor your portfolio and adjust as needed.
Conclusion
HODLing isn’t just a meme—it’s a time-tested strategy for building wealth in crypto. By holding onto fundamentally strong assets, you can capture long-term growth while avoiding the emotional traps of active trading.
In 2025, pairing HODLing with AI-powered insights from Token Metrics gives you an edge—helping you select the right assets, manage risk, and stay committed to your investment plan. Whether you’re a beginner or a seasoned investor, HODLing remains one of the simplest and most effective ways to build wealth in the dynamic world of cryptocurrency.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.