



What Is Cryptocurrency? A Beginner’s Guide + How Token Metrics Helps You Invest Smarter
%201.svg)
%201.svg)


Cryptocurrency is no longer just a buzzword — it’s a financial revolution. Since Bitcoin's creation in 2009, digital currencies have disrupted traditional finance, creating an entirely new class of assets. But what exactly is cryptocurrency, how does it work, and how can investors navigate this complex market with the help of tools like Token Metrics?
This comprehensive and SEO-optimized guide explains what cryptocurrency is, how it works, the different types available, and how platforms like Token Metrics help investors make smarter, AI-powered decisions.
🔍 What Is Cryptocurrency?
Cryptocurrency is a digital or virtual form of money that uses cryptography for security. Unlike traditional fiat currencies like the U.S. Dollar or Euro, cryptocurrencies operate on decentralized networks — typically blockchain technology — that aren't controlled by governments or central banks.
Key Features of Cryptocurrencies:
- Decentralized: Most cryptocurrencies run on decentralized networks called blockchains.
- Secure: Transactions are secured by cryptographic protocols.
- Transparent: Blockchain ledgers are public and can be audited in real time.
- Limited Supply: Many cryptocurrencies, like Bitcoin, have fixed maximum supplies.
- Borderless: Anyone with an internet connection can use and trade crypto globally.
💡 How Does Cryptocurrency Work?
At the heart of cryptocurrency is blockchain technology — a distributed ledger that records all transactions across a network of computers (called nodes). Each block contains a list of transactions, and once verified, it's added to the chain permanently.
Example:
If Alice sends 1 Bitcoin to Bob, this transaction is verified by nodes and added to the Bitcoin blockchain. No bank is involved, and no one can alter the record.
🪙 Types of Cryptocurrencies
Thousands of cryptocurrencies exist today, but they typically fall into these categories:
1. Bitcoin (BTC)
The original and most well-known cryptocurrency. It's often viewed as "digital gold" due to its scarcity and store-of-value properties.
2. Altcoins
Any crypto that's not Bitcoin. Examples include:
- Ethereum (ETH) – Enables smart contracts and decentralized apps.
- Cardano (ADA) – Focuses on peer-reviewed scientific research.
- Solana (SOL) – Known for high-speed transactions and low fees.
3. Stablecoins
Digital assets pegged to fiat currencies. Example: USDT (Tether), and USDC. These offer price stability and are widely used for trading and DeFi.
4. Meme Coins
Tokens like Dogecoin (DOGE) or Shiba Inu (SHIB), driven largely by community hype and social media.
5. Utility Tokens
Tokens used within specific platforms, such as BNB for Binance or TMAI for Token Metrics.
📈 Why Do People Invest in Cryptocurrency?
- High Return Potential
Many early adopters have seen exponential gains, particularly in bull markets. Moonshot altcoins can deliver 10x to 100x returns. - Diversification
Crypto offers exposure outside traditional assets like stocks or bonds. - 24/7 Trading
Unlike traditional markets, crypto trades nonstop across global exchanges. - Ownership & Transparency
Blockchain gives users full control and verifiable records of their holdings.
⚠️ Risks of Crypto Investing
- Volatility: Prices can rise or fall rapidly within hours.
- Security Risks: Hacks and scams are common in poorly secured projects.
- Regulatory Uncertainty: Rules differ across countries and can change quickly.
- Market Hype: Many investors get swayed by trends without research.
🤖 How Token Metrics Helps You Trade Smarter
Given the complexity and volatility of crypto, using a data-driven platform like Token Metrics can make a huge difference.
What is Token Metrics?
Token Metrics is an AI-powered crypto analytics and investment research platform that helps investors:
- Discover high-potential altcoins
- Time market entries and exits
- Compare tokens across key metrics
- Set personalized alerts and trading signals
Key Features:
1. AI Price Predictions
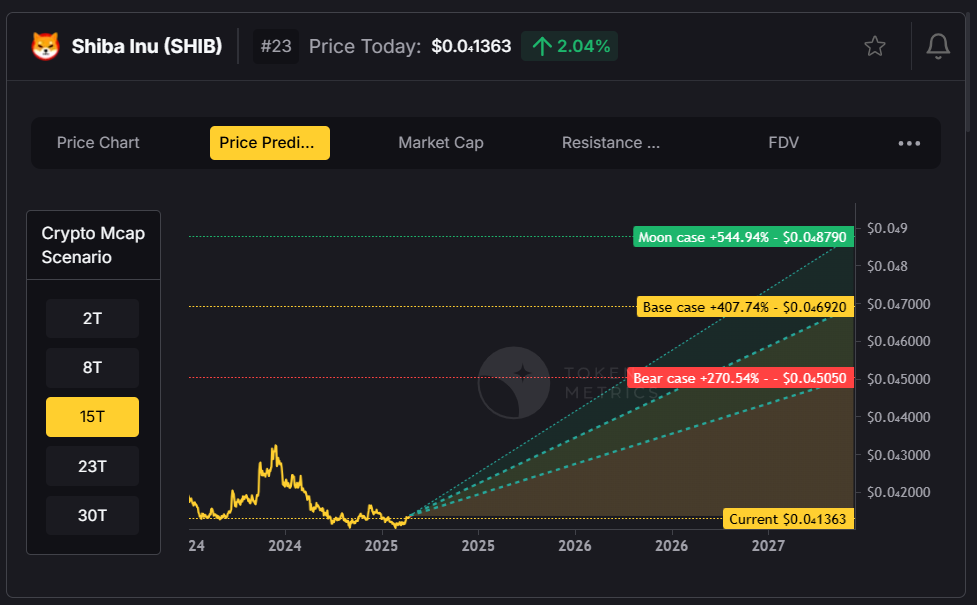
Token Metrics uses machine learning to forecast future price ranges for Bitcoin, Ethereum, and 6,000+ altcoins.
2. Trader & Investor Grades
Each token is assigned a Trader Grade (short-term performance) and an Investor Grade (long-term fundamentals), updated daily using 80+ on-chain, technical, and sentiment data points.
3. Moonshot Rankings
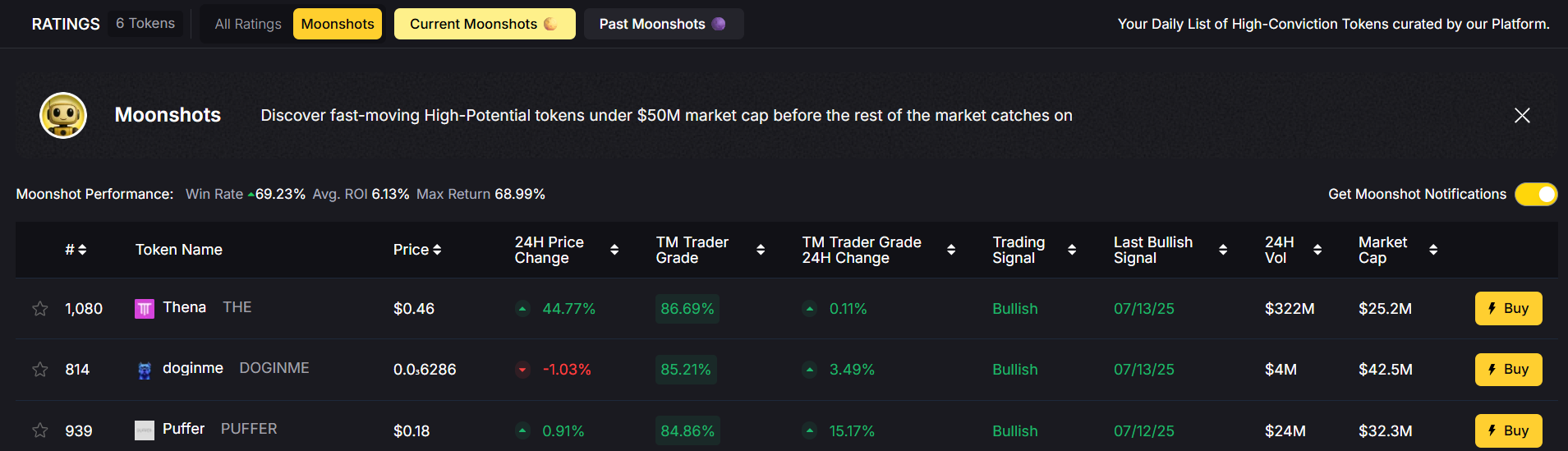
Discover small-cap tokens with massive upside using the Moonshots tab, ranked by ROI, volume, grade changes, and time of entry.
4. Real-Time Alerts
Receive instant alerts via Telegram, email, Discord, or SMS for:
- Price targets
- Bullish or bearish signals
- Grade increases or downgrades
5. Token Details Dashboard
Dive deep into any project — fundamentals, top holders, historical grades, AI forecasts, and charting — all in one place.
6. Integrated Swap Widget
Once you’ve done your research, trade instantly through Token Metrics with integrated swap functionality.
🧠 How Beginners Can Use Token Metrics
Step 1: Sign Up for Free
Visit tokenmetrics.com and choose a plan. Free users get 5,000 API calls per month and access to basic analytics.
Step 2: Visit the Ratings Page This page ranks top-performing coins using AI grades and recent performance metrics.
Step 3: Click on Moonshots Looking for the next 100x gem? The Moonshots tab highlights tokens with exceptional short-term upside potential.
Step 4: Set Custom Alerts
Never miss a breakout. Customize alerts for price changes, grade shifts, or buy/sell signals.
Step 5: Explore Deep Research
Use Token Metrics’ detailed pages to analyze tokenomics, volume, investor behavior, and social sentiment.
🔮 The Future of Cryptocurrency
Cryptocurrency is rapidly evolving. With institutional adoption rising, central banks exploring CBDCs, and retail interest growing, the market is entering a more mature phase.
Key trends:
- Bitcoin ETFs and reserve adoption
- Layer-2 scaling solutions like Arbitrum and Optimism
- AI and DeFi integration
- Tokenized real-world assets (RWAs)
Platforms like Token Metrics will become essential as investors need intelligent, unbiased tools to navigate this increasingly sophisticated market.
✅ Final Thoughts
Cryptocurrency is changing how we think about money, ownership, and investing. But with great opportunity comes complexity. Whether you're a beginner or a seasoned trader, tools like Token Metrics give you the edge you need to:
- Cut through noise
- Discover winning trades
- Manage risk
- Stay ahead of the curve
Token Metrics isn’t just a research platform — it’s your AI-powered co-pilot in the crypto space.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.