



Filecoin Price Prediction - Is It Good to Invest or Avoid?
%201.svg)
%201.svg)

Amidst the ever-shifting landscape of cryptocurrencies, Filecoin (FIL) emerges as a formidable player, drawing the attention and admiration of investors and traders. FIL's distinct features and capabilities have propelled it into the limelight.
Now, as speculation surrounding Filecoin's future performance intensifies, many are eager to ascertain whether its value will persist in its upward trajectory.
This article delves deep into the myriad factors that may sway Filecoin's price and furnishes a comprehensive analysis of its future price predictions in the years to come.
Filecoin Overview
Filecoin emerges as a decentralized data storage marvel, drawing immense recognition in the ever-shifting terrain of cryptocurrencies. As we embark on our journey through the crypto-verse, unraveling the core of Filecoin takes center stage.
This piece ventures into a deep understanding of Filecoin's past performance, dissects its contemporary fundamentals and maps out its horizons for potential long-term investments.
Furthermore, it delves deep into the insights from industry connoisseurs, meticulously weighing the inherent risks and rich rewards entwined with investing in this ingenious creation.
FIL Historical Data
Filecoin's journey has been nothing short of remarkable. Since its inception, Filecoin has consistently adapted and expanded, redefining the landscape of decentralized data storage.
Its historical data showcases impressive growth and resilience, drawing the attention of both institutional and retail investors.
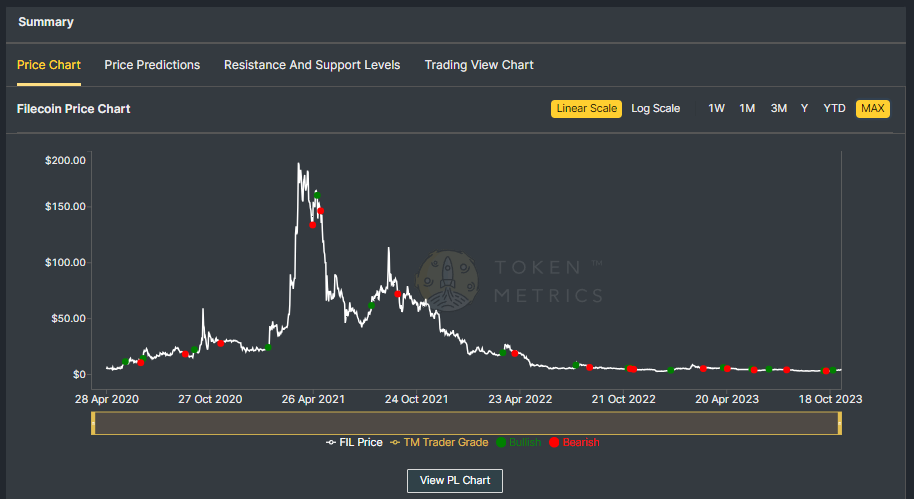
Filecoin Fundamentals
Filecoin's journey has indeed been an awe-inspiring odyssey. Since its inception, it has continuously evolved, reshaping the world of decentralized data storage.
The historical records paint a vivid picture of remarkable growth and unwavering resilience, captivating the interest of both institutional and retail investors.
Exploring Filecoin's Current Fundamentals
At the heart of Filecoin's fundamental strength lies its pioneering approach to data storage. It has firmly positioned itself as a frontrunner in decentralized data storage, providing a platform for users to transact storage space.
This ingenious fusion of blockchain technology with data storage solutions has propelled its significance to new heights.
Key Fundamentals
- Decentralized data storage: Filecoin delivers a secure, decentralized means of storing and retrieving data, offering immense value across various applications.
- Market dynamics: Its marketplace for storage providers and users fosters a competitive environment, molding pricing and service quality.
- Diverse applications: From data archiving to content delivery, Filecoin accommodates a broad array of data storage requirements.
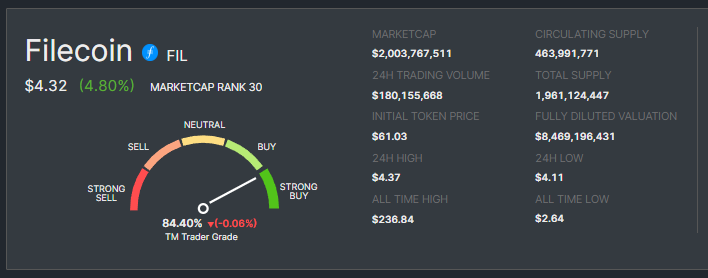
Filecoin's Long-Term Price Projection - Insights from Industry Experts: Distinguished cryptocurrency analysts and authorities envision a bright future for Filecoin.
Their optimism stems from Filecoin's distinctive role within the data storage sector, serving as an alternative to traditional centralized storage methods.
While prudence dictates caution in price projections, these experts suggest that Filecoin holds the potential for substantial long-term appreciation.
Now, let's embark on a comprehensive exploration of diverse forecasts for Filecoin's price in 2023, 2025, and 2030.
Filecoin Price Prediction: Scenario Analysis
To make accurate price predictions, it is crucial to consider different scenarios that can impact Filecoin's price. Let's analyze two scenarios - a bullish and a bearish scenario - to get a better understanding of the potential price movements of Filecoin.
Filecoin Price Prediction - Bullish Scenario
If the crypto market cap hits $3 Trillion, and if Filecoin retains its current 0.14% dominance, its price could ascend to $9.35
In a more bullish scenario of the crypto market surging to $10 Trillion, Filecoin's price could soar to a staggering $31.18, resulting in a potential 7x return for investors.

Filecoin Price Prediction - Bearish Scenario
In a bearish scenario, where market conditions are unfavorable, or there is increased competition, the price of Filecoin may face downward pressure with a decreased dominance of 0.07%.
In this scenario, If the crypto market cap hits $3 Trillion, Filecoin could trade around $4.67 in the short term and struggle to surpass $15.59 by 2030 even if the total crypto market cap surpasses the $10 Trillion mark.
It is essential to note that these scenarios are speculative and should not be considered financial advice. The cryptocurrency market is highly volatile, and prices can fluctuate rapidly.
Filecoin Price Predictions - Industry Expert Opinion
- CryptoPredictions: The Crypto Predictions platform predicts that Filecoin's price in 2023 could reach an average of $2.802.
- CoinCodex: Forecasts that the price of Filecoin may fluctuate between $3.07 (minimum) and $25.56 (maximum) in 2024.
- Bitnation: Suggests a maximum potential price of $8.84, an average of $7.90, and a minimum of $6.95 for Filecoin by the end of 2024.
- OvenAdd: Estimates a potential yearly low for Filecoin at $16.47 and a potential high of $17.56 in 2024.
- CryptoPredictions: Suggests an average price of $5.643 for Filecoin in 2025, and by 2030, the average price of Filecoin may reach $28.
Please remember that these are predictions, and actual outcomes may vary. It's advisable to conduct thorough research before making any investment decisions.
Note - Start Your Free Trial Today and Uncover Your Token's Price Prediction and Forecast on Token Metrics.

Is Filecoin Good to Invest or Avoid?
The answer depends on your investment goals and risk tolerance. Filecoin continues to disrupt the data storage industry by providing a decentralized and secure solution. It has a unique market positioning, which may appeal to investors looking to diversify their portfolios.
Reasons to Invest in Filecoin:
- Growing demand: The need for secure and decentralized data storage is rising, making Filecoin's services increasingly relevant.
- Innovation: Filecoin represents a novel approach to data storage, which could lead to further adoption.
- Competitive advantage: Its decentralized marketplace differentiates Filecoin from traditional data storage solutions.
Risks and Considerations:
- Market competition: Filecoin faces competition from both traditional data storage providers and other blockchain-based solutions.
- Regulatory environment: Regulatory changes and compliance issues could impact Filecoin's operations.
- Volatility: As with all cryptocurrencies, Filecoin's price is subject to market volatility.
Future Potential of Filecoin
The future potential of Filecoin is grounded in its unique approach to decentralized data storage. As the demand for secure data storage continues to grow, Filecoin is well-positioned to be a significant player.
Its roadmap includes plans for enhancing scalability, security, and performance, ensuring its place at the forefront of the decentralized data storage sector.
Also Read - XRP Price Prediction
Expert Insights
Crypto experts and analysts from the industry share their thoughts on Filecoin's long-term potential:
- Alden Baldwin, a writer at Cryptopolitan, suggests that Filecoin's unique approach to decentralized data storage positions it as a strong contender for long-term success. As the demand for secure data storage grows, Filecoin’s services are expected to remain highly relevant.
- CoinCodex, a leading cryptocurrency price prediction platform, shares that Filecoin's innovative solutions are well-aligned with the evolving data storage landscape. Its hybrid marketplace and blockchain-based security measures provide a strong foundation for future growth.
- BeInCrypto, a cryptocurrency news and analysis website, mentions that Filecoin's role in providing secure and decentralized data storage is pivotal in an era of growing data volumes. The ongoing development of its ecosystem and technology ensures its continued significance.
Frequently Asked Questions
Q1. What makes Filecoin different from traditional data storage solutions?
Filecoin distinguishes itself by offering decentralized, blockchain-based data storage, which provides enhanced security and ownership control.
Q2. How can I invest in Filecoin?
You can invest in Filecoin by purchasing FIL tokens on cryptocurrency exchanges. Be sure to store them securely in a compatible wallet.
Q3. What factors should I consider before investing in Filecoin?
Before investing, consider your risk tolerance, the competitive landscape, regulatory developments, and the long-term potential of Filecoin in the data storage sector.
Q4. Can I mine Filecoin?
Yes, Filecoin offers a mining opportunity where users can earn FIL tokens by providing storage and retrieval services.
Q5. Where can I find more information about Filecoin's technology and roadmap?
For a deeper understanding of Filecoin's technology and future plans, consult the official Filecoin documentation and stay updated with their development updates.
Conclusion
Filecoin has demonstrated remarkable growth and innovation in the dynamic field of decentralized data storage.
While the potential for long-term growth is promising, investors must conduct thorough research, evaluate risks, and consider expert opinions when deciding if Filecoin aligns with their investment objectives. The crypto world is ever-evolving, and vigilance is essential when considering any investment.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other advice, and you should not treat any of the website's content as such.
Token Metrics does not recommend that any cryptocurrency should be bought, sold, or held by you. Conduct your due diligence and consult your financial advisor before making investment decisions.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.