



Free Crypto API: Build Smarter Crypto Apps at Zero Cost
%201.svg)
%201.svg)

What Is a Free Crypto API?
A free crypto API gives developers access to cryptocurrency data without upfront costs. Think of it as a bridge between raw blockchain/market data and your application. APIs let you pull:
- Real-time token prices and charts
- Historical data for backtesting and research
- Market cap, liquidity, and trading volumes
- On-chain metrics such as wallet flows
- AI-driven trading signals and predictive insights
Free tiers are invaluable for prototyping apps, dashboards, and bots. They let you validate ideas quickly before paying for higher throughput or advanced endpoints.
Why Developers Use Free Crypto APIs
Free crypto APIs aren’t just about saving money—they’re about learning fast and scaling smart:
- Zero-Cost Entry – Start building MVPs without financial risk.
- Rapid Prototyping – Test ideas like dashboards, bots, or AI agents quickly.
- Market Exploration – Access broad coverage of tokens before committing.
- Growth Path – Once demand grows, upgrade to premium tiers seamlessly.
📌 Tip: Use multiple free crypto APIs in parallel during early development. This helps you benchmark speed, reliability, and accuracy.
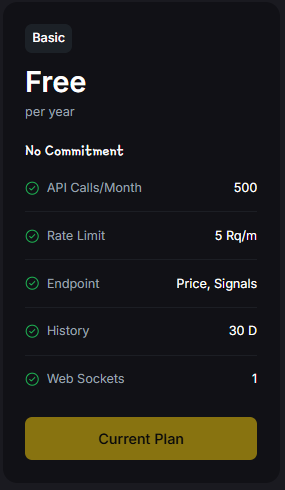
Key Features of the Token Metrics Free API
The Token Metrics free tier goes beyond basic price feeds by offering:
- Real-Time Prices – Live data on Bitcoin, Ethereum, and thousands of tokens.
- AI Trading Signals – Bull/Bear indicators that help power smarter strategies.
- Secure Access – Encrypted endpoints with key-based authentication.
- 30 Days of History – Enough to prototype backtests and analytics features.
Unlike many free crypto APIs, Token Metrics API provides both price data and intelligence, making it ideal for developers who want more than surface-level metrics.
Comparing Free Crypto APIs: Strengths & Trade-offs
- CoinGecko & CoinMarketCap
- Pros: Huge token coverage, great for charts and tickers.
- Cons: Limited historical and no predictive analytics.
- Pros: Huge token coverage, great for charts and tickers.
- CryptoCompare
- Pros: Rich historical tick-level data, good for backtesting.
- Cons: Free tier limits depth and call volume.
- Pros: Rich historical tick-level data, good for backtesting.
- Glassnode
- Pros: Strong on-chain insights.
- Cons: Many advanced datasets require paid access.
- Pros: Strong on-chain insights.
- Alchemy & Infura
- Pros: Node-level blockchain access for dApp builders.
- Cons: Not designed for trading or analytics—raw blockchain data only.
- Pros: Node-level blockchain access for dApp builders.
- Token Metrics
- Pros: Real-time prices, AI signals, and on-chain analytics in one free tier.
- Cons: Rate limits apply (upgrade available for higher throughput).
- Pros: Real-time prices, AI signals, and on-chain analytics in one free tier.

Popular Use Cases: From Bots to Dashboards
- AI Crypto Trading Bots – Start testing automation using live prices and bull/bear signals.
- Crypto Dashboards – Aggregate token ratings, prices, and trends for end users.
- Research Tools – Run small-scale backtests with 30-day historical data.
- Learning Projects – Ideal for students or developers exploring crypto APIs.
📌 Real-world example: Many developers use the Token Metrics free tier to prototype bots that later scale into production with paid plans.
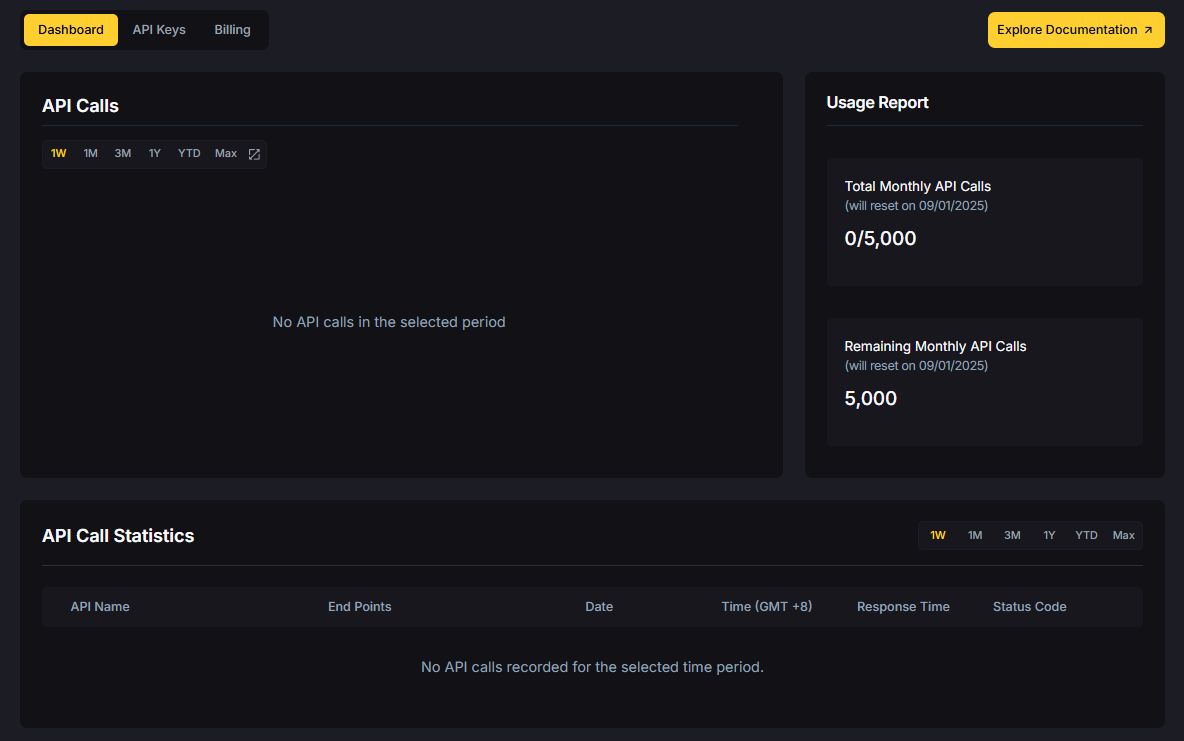
Best Practices for Using Free Crypto APIs
- Start with Prototypes – Test multiple free APIs to compare reliability and latency.
- Track Rate Limits – Free tiers often throttle requests (e.g., 5 req/min at Token Metrics).
- Combine Data Sources – Use Token Metrics for signals + CoinGecko for broad coverage.
- Secure Keys – Treat even free API keys as sensitive credentials.
- Prepare to Upgrade – Build flexible code so you can switch tiers or providers easily.
Beyond Token Metrics: Other Free Resources Worth Knowing
- DefiLlama API – Free coverage of DeFi protocols, yields, and TVL.
- Dune Analytics – Query blockchain data with SQL for free.
- TradingView Widgets – Embed charts directly into dashboards.
- Santiment API – Free endpoints for social/sentiment analytics.
These can complement Token Metrics. For example, you could combine Token Metrics signals + DefiLlama DeFi data + TradingView charts into one unified dashboard.
How to Get Started With the Token Metrics Free API
- Sign Up for a free Token Metrics account.
- Generate Your API Key instantly from your dashboard.
- Check the Docs for endpoints, examples, and code snippets.
- Prototype Your App with real-time prices and signals.
- Upgrade When Ready to unlock larger datasets and more endpoints.
👉 Grab Your Free Token Metrics API Key

FAQs About Free Crypto APIs
What can I access with Token Metrics Free API?
Live token prices, bull/bear trading signals, and 30 days of historical data.
Are free APIs reliable for production?
Not recommended—free tiers are best for prototypes. Paid tiers ensure reliability and scale.
What are the rate limits?
500 calls/month, 5 requests/minute, and 1 WebSocket connection.
Can I use the free API for trading bots?
Yes—ideal for prototyping. For production-level bots, upgrade for more throughput.

Scaling Beyond Free: Paid Plans & X.402
When your project outgrows free limits, Token Metrics offers flexible upgrades:
- Pay-Per-Call (X.402) – As low as $0.017 per call, unlimited usage, no commitment.
- Advanced Plan ($999.99/year) – 20,000 calls/month, indices & indicators, 3 WebSockets.
- Premium Plan ($1,999.99/year) – 100,000 calls/month, AI agent + reports, 3 years of history.
With up to 35% off using TMAI tokens, scaling is cost-efficient.
📌 Why X.402 matters: Instead of committing upfront, you can grow gradually by paying per call—perfect for startups and side projects.

Build Smarter, Scale Easier
Free APIs help you start quickly and learn fast. Token Metrics gives you more than prices—it adds AI-powered signals and intelligence. Combine it with other free APIs, and you’ll have a toolkit that’s powerful enough for experimentation and flexible enough to scale into production.
👉 Create Your Free Token Metrics Account and Start Building
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.