Who this guide is for: Traders, DeFi users, and multichain portfolio managers seeking secure, cost-effective ways to move assets across blockchains.
Top three picks:
- Stargate Finance — deepest liquidity for stablecoin transfers across major EVM chains and non-EVM networks.
- Synapse Protocol — fastest routes for traders needing sub-5-minute settlements on 20+ chains.
- Across Protocol — lowest slippage and optimistic bridging for arbitrageurs and high-frequency movers.
Key caveat: Bridge fees vary by route, liquidity depth, and network congestion; always compare quotes and verify destination addresses before confirming transfers.
Introduction: Why Cross-Chain Bridges Matter in 2025
Cross-chain bridges are infrastructure protocols that enable seamless asset transfers between blockchains, solving fragmented liquidity and allowing traders to access opportunities across ecosystems without holding native tokens on every chain. In 2025, with over 100 active Layer 1 and Layer 2 networks, best cross-chain bridges for traders deliver speed, security, and capital efficiency—critical for arbitrage, yield farming, and portfolio rebalancing. This guide evaluates the top 10 cross-chain bridges based on liquidity depth, security architecture, chain coverage, fee transparency, and user experience, helping you select the right solution for your trading strategy.
How We Picked (Methodology & Scoring)
We evaluated 20+ cross-chain bridges using six weighted criteria:
- Liquidity & Volume (30%) — Daily transfer volume, pool depth, and slippage on major routes
- Security Architecture (25%) — Validator model, audit history, exploit record, bug bounties
- Chain Coverage (15%) — Number of supported networks (EVM, non-EVM, L2s)
- Costs & Fees (15%) — Bridge fees, gas optimization, hidden slippage
- User Experience (10%) — Interface clarity, transaction speed, wallet integrations
- Support & Documentation (5%) — Docs quality, status pages, support channels
Data sources: Official protocol documentation, pricing pages, security audit repositories, and status dashboards. Third-party volume data from CoinGecko and DefiLlama used for cross-checks only.
Last updated: November 2025
Best Cross-Chain Bridges in 2025 (Comparison Table)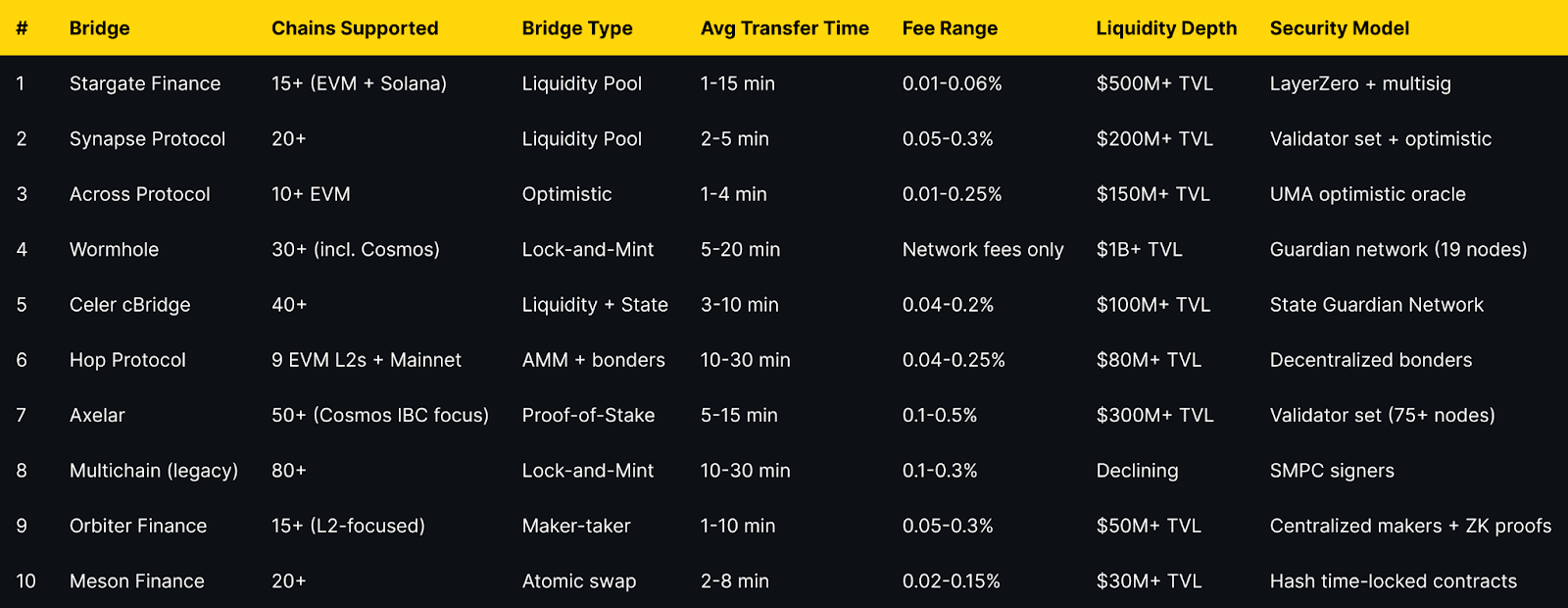
Top 10 Cross-Chain Bridges in 2025
1. Stargate Finance — Best for Stablecoin Transfers
Why Use It: Stargate leverages LayerZero's messaging protocol to offer unified liquidity pools across 15+ chains, ensuring minimal slippage for USDC, USDT, and DAI transfers. Traders benefit from instant guaranteed finality and native asset transfers without wrapped tokens, making it ideal for large stablecoin movements between Ethereum, Arbitrum, Optimism, Polygon, BNB Chain, Avalanche, and Solana.
Best For: DeFi yield farmers, arbitrageurs moving stablecoins, traders rebalancing across chains, institutional desks.
Notable Features:
- Unified liquidity pools eliminate fragmented routes
- Delta algorithm prevents pool depletion and maintains balance
- Native USDC/USDT support on major chains
- Audited by Quantstamp and Zellic with $25M bug bounty
Consider If: You need to bridge non-stablecoin assets frequently (limited ERC-20 coverage) or require sub-1-minute finality (average 1-15 min).
Alternatives: Synapse Protocol, Across Protocol
2. Synapse Protocol — Best for Speed Across 20+ Chains
Why Use It: Synapse combines liquidity pools with an optimistic verification model to deliver 2-5 minute average transfer times across 20+ networks, including Ethereum, Arbitrum, Optimism, Base, Polygon, BNB Chain, Avalanche, Fantom, Harmony, Moonbeam, and Aurora. Its nUSD and nETH synthetic assets enable efficient cross-chain swaps with competitive 0.05-0.3% fees, while the Synapse Bridge interface integrates one-click swaps for seamless UX.
Best For: Active traders prioritizing speed, multichain yield optimizers, NFT collectors moving assets, users bridging to emerging L2s.
Notable Features:
- Sub-5-minute average transfers with optimistic verification
- 20+ chain support including Base and zkSync Era
- Integrated DEX for same-transaction swaps
- Audited by Quantstamp, Certik, and Code4rena
Consider If: You move assets over $100K per transaction (liquidity depth varies by route) or need guaranteed finality before spending (optimistic delays possible).
Alternatives: Stargate Finance, Hop Protocol
3. Across Protocol — Best for Optimistic Bridging & Low Slippage
Why Use It: Across uses UMA's optimistic oracle to facilitate near-instant transfers with relayers fronting capital and settling on the destination chain within 1-4 minutes. Traders enjoy 0.01-0.25% fees—among the lowest for EVM bridges—and minimal slippage on major routes like Ethereum to Arbitrum, Optimism, Polygon, and Base. The protocol's capital efficiency makes it ideal for arbitrageurs and high-frequency movers.
Best For: Arbitrage traders, gas-sensitive users, high-frequency DeFi participants, cost-conscious portfolio managers.
Notable Features:
- Optimistic verification for 1-4 minute transfers
- Ultra-low fees (0.01-0.25%) with transparent pricing
- Relayer network ensures liquidity without pool fragmentation
- Audited by OpenZeppelin and ABDK with ongoing bug bounty
Consider If: You need non-EVM chain support (currently EVM-only) or prefer liquidity-pool-based bridges for guaranteed execution.
Alternatives: Stargate Finance, Synapse Protocol
4. Wormhole — Best for Cross-Ecosystem Bridging
Why Use It: Wormhole is a generalized messaging protocol supporting 30+ blockchains including Ethereum, Solana, Terra, BNB Chain, Avalanche, Polygon, Fantom, Celo, and Cosmos-based chains. Its Guardian network of 19 validators enables lock-and-mint bridging for tokens and NFTs with no protocol fees beyond network gas costs. The recent Wormhole Connect widget simplifies integrations for traders using multichain dApps.
Best For: Cross-ecosystem traders (EVM to Solana/Cosmos), NFT collectors, developers integrating bridging, users of Wormhole-native dApps.
Notable Features:
- 30+ chain support including Solana, Terra, and Cosmos IBC
- Generalized messaging enables cross-chain smart contract calls
- Guardian network with 19 institutional validators
- Audited by Neodyme, Kudelski, and OtterSec post-2022 exploit recovery
Consider If: You prioritize speed over security guarantees (5-20 min transfers) or need the deepest liquidity per route (Stargate/Synapse stronger for stables).
Alternatives: Axelar, Celer cBridge
5. Celer cBridge — Best for 40+ Chain Coverage
Why Use It: Celer cBridge supports 40+ blockchains with a hybrid liquidity pool and state channel architecture, enabling 3-10 minute transfers at 0.04-0.2% fees. Its State Guardian Network provides security for cross-chain state verification, while the cBridge UI offers direct wallet integrations and historical transaction tracking. Recent additions include support for zkSync Era, Linea, and Scroll.
Best For: Multichain portfolio managers, traders accessing niche L2s, users bridging to gaming-focused chains, cost-conscious cross-chain swappers.
Notable Features:
- 40+ chains including zkSync, Linea, Mantle, and Scroll
- State Guardian Network for optimistic cross-chain verification
- Integrated liquidity mining for yield on idle bridge assets
- Audited by Certik, PeckShield, and SlowMist
Consider If: You operate in mainland China (limited access) or need guaranteed sub-5-minute finality (optimistic delays on congested routes).
Alternatives: Synapse Protocol, Axelar
6. Hop Protocol — Best for Ethereum L2 Bridging
Why Use It: Hop specializes in fast transfers between Ethereum mainnet and nine major L2s (Arbitrum, Optimism, Base, Polygon, zkSync Era, Linea, Scroll, Gnosis Chain, and Polygon zkEVM) using AMM-style liquidity pools and decentralized bonders who provide instant liquidity. Traders pay 0.04-0.25% fees and experience 10-30 minute average transfers, with the option to earn yield by providing liquidity or running bonder nodes.
Best For: L2-first traders, Ethereum mainnet to L2 bridgers, liquidity providers, users seeking decentralized bridge architecture.
Notable Features:
- Native L2 focus with support for 9 Ethereum L2s
- AMM-based liquidity pools for transparent pricing
- Decentralized bonder network reduces trust assumptions
- Audited by Consensys Diligence and OpenZeppelin
Consider If: You need to bridge to non-EVM chains (Ethereum ecosystem only) or require sub-10-minute finality consistently (bonder availability varies).
Alternatives: Synapse Protocol, Across Protocol
7. Axelar — Best for Cosmos & Proof-of-Stake Security
Why Use It: Axelar is a Cosmos SDK-based interoperability network with 75+ validators securing cross-chain transfers via proof-of-stake consensus. Supporting 50+ chains with IBC-native bridging to Cosmos, Osmosis, Injective, and other app-chains, Axelar enables secure general message passing for complex cross-chain dApp interactions at 0.1-0.5% fees. Transfers settle in 5-15 minutes with high finality guarantees.
Best For: Cosmos ecosystem traders, institutional users prioritizing security, developers building cross-chain dApps, users requiring verifiable bridge security.
Notable Features:
- 75+ decentralized validators with proof-of-stake security
- Native IBC support for Cosmos ecosystem chains
- General Message Passing (GMP) for cross-chain smart contracts
- Audited by NCC Group, OtterSec, and Certik
Consider If: You prioritize speed over security (5-15 min slower than optimistic bridges) or need the lowest fees per transaction (0.1-0.5% higher than Across/Stargate).
Alternatives: Wormhole, Celer cBridge
8. Multichain — Best for 80+ Chain Access (Use With Caution)
Why Use It: Multichain (formerly Anyswap) offers the broadest chain coverage with 80+ supported networks using SMPC (Secure Multi-Party Computation) signers for lock-and-mint bridging. While historically popular for accessing niche chains like Moonriver, Kava, and Metis, the protocol faced security concerns in mid-2023 related to validator key management. Fees range from 0.1-0.3% with 10-30 minute transfer times.
Best For: Users bridging to obscure chains unavailable elsewhere, legacy dApp integrations, traders willing to accept elevated risk for maximum coverage.
Notable Features:
- 80+ chain support including niche L1s and L2s
- Long operational history since 2020
- Cross-chain router for multi-hop transactions
- SMPC validator network (security incidents reported)
Consider If: Security is your top priority (2023 exploit drained $126M; ongoing validator concerns) or you need active development and transparent disclosures.
Alternatives: Celer cBridge, Axelar
9. Orbiter Finance — Best for L2-to-L2 Transfers
Why Use It: Orbiter uses a maker-taker model where centralized makers provide instant liquidity for L2-to-L2 transfers across 15+ chains including Arbitrum, Optimism, zkSync Era, StarkNet, Linea, Base, and Scroll. Transfers complete in 1-10 minutes at 0.05-0.3% fees, with ZK-proof verification planned for enhanced security. The interface is optimized for mobile and shows real-time maker liquidity status.
Best For: L2-native traders, StarkNet and zkSync users, mobile-first users, traders needing fast L2 exits.
Notable Features:
- Specialized L2-to-L2 focus with 15+ network support
- 1-10 minute average transfers via maker liquidity
- ZK-proof verification roadmap for trustless bridging
- Real-time liquidity tracking and maker status
Consider If: You prefer fully decentralized bridge models (makers are centralized) or need mainnet-to-L2 bridging exclusively (better alternatives exist).
Alternatives: Hop Protocol, Synapse Protocol
10. Meson Finance — Best for Atomic Swap Security
Why Use It: Meson implements hash time-locked contracts (HTLCs) for trustless atomic swaps across 20+ chains, eliminating validator risk and bridge contract vulnerabilities. Traders benefit from 2-8 minute transfers at 0.02-0.15% fees with cryptographic guarantees that transactions either complete or refund automatically. The protocol is audited by SlowMist and maintains zero-exploit history since launch.
Best For: Security-conscious traders, users burned by bridge exploits, atomic swap enthusiasts, traders moving mid-sized amounts ($1K-$50K).
Notable Features:
- HTLC-based atomic swaps for trustless bridging
- Zero-exploit record with cryptographic security guarantees
- 20+ chain support including major EVM and L2s
- 0.02-0.15% fees competitive with optimistic bridges
Consider If: You need to bridge large amounts over $100K (liquidity depth limited) or require sub-2-minute finality (HTLC setup adds overhead).
Alternatives: Across Protocol, Stargate Finance
Decision Guide: Best By Use Case
- Stablecoin arbitrage & DeFi yield: Stargate Finance for deepest USDC/USDT liquidity
- Fastest cross-chain execution: Synapse Protocol or Across Protocol for sub-5-minute transfers
- Ethereum L2 specialists: Hop Protocol for native L2 bridging with decentralized bonders
- Cross-ecosystem traders (EVM + Solana/Cosmos): Wormhole or Axelar for broadest coverage
- Lowest fees & slippage: Across Protocol for optimistic bridging at 0.01-0.25%
- Maximum chain coverage: Celer cBridge (40+) or Multichain (80+ with caution)
- L2-to-L2 focus (zkSync, StarkNet, Arbitrum): Orbiter Finance for maker-taker speed
- Security-first & trustless: Meson Finance for atomic swap guarantees
- Institutional security requirements: Axelar for proof-of-stake validator model
- Mobile-optimized bridging: Orbiter Finance or Synapse Protocol
How to Choose the Right Cross-Chain Bridge (Checklist)
- [ ] Verify chain support — Confirm both source and destination chains are supported with active liquidity
- [ ] Check fee transparency — Review total costs including bridge fees, gas, and potential slippage before confirming
- [ ] Assess security model — Understand validator architecture (optimistic, proof-of-stake, HTLC, multisig) and audit history
- [ ] Review transfer speed requirements — Match bridge speed (1-30 min) to your trading strategy urgency
- [ ] Confirm liquidity depth — For large transfers ($50K+), verify pool TVL and recent volume on your specific route
- [ ] Test with small amounts first — Always bridge test transactions ($10-$100) before moving significant capital
- [ ] Verify destination address format — Double-check address compatibility and network selection to avoid irreversible losses
- [ ] Monitor bridge status pages — Check for maintenance, paused routes, or congestion warnings before transacting
- [ ] Understand finality guarantees — Know if transfers are optimistic (reversible), instant (relayer-based), or cryptographically final
- [ ] Review regional restrictions — Confirm access from your jurisdiction (most bridges global; check compliance)
- [ ] Check exploit history — Research past security incidents and protocol responses (Wormhole 2022, Multichain 2023)
- 🚩 Red flags: Bridges with undisclosed validator sets, paused routes without status updates, or fees significantly higher than quoted
Use Token Metrics With Any Cross-Chain Bridge
Maximize your cross-chain trading strategy by combining bridge infrastructure with Token Metrics intelligence:
- AI Ratings screen 6,000+ tokens across chains to identify quality assets before bridging capital
- Narrative Detection spots emerging themes (e.g., Solana DeFi, Base ecosystem) to inform which chains to bridge into
- Portfolio Optimization balances risk across chains and suggests rebalancing targets that justify bridge costs
- Alerts & Signals time bridge transactions around momentum shifts, reducing exposure to unfavorable price action mid-transfer
Workflow: Research asset quality with AI Ratings → Select optimal bridge for your route → Execute transfer → Monitor destination chain with real-time alerts.
Start your free trial to screen assets and time bridge transactions with AI-powered intelligence.
Security & Compliance Tips
- Verify official URLs — Always access bridges through bookmarked official domains; phishing sites are common
- Use hardware wallets — Sign bridge transactions with Ledger/Trezor for cold-storage protection
- Check token approvals — Revoke unlimited approvals after bridging using tools like Revoke.cash
- Monitor bridge exploits — Follow protocol Twitter accounts and status pages for real-time security alerts
- Understand validator risks — Multisig and SMPC bridges concentrate risk; optimistic and PoS models distribute trust
- Avoid bridging during congestion — High gas fees and slippage increase during network congestion; wait for off-peak times
- Store bridge receipts — Save transaction hashes and screenshots for tax reporting and dispute resolution
- Test cross-chain contract calls — If using advanced features (e.g., Axelar GMP), test with minimal amounts first
- Review liquidity provider risks — Impermanent loss and smart contract risk apply to bridge LPs; understand before depositing
- Know refund procedures — Understand each bridge's failed transaction refund process and timeframes
This article is for research and educational purposes, not financial advice. Conduct your own security due diligence before bridging assets.
Beginner Mistakes to Avoid
- Bridging to the wrong network — Always triple-check destination chain selection; wrong-network transfers are often irreversible
- Ignoring slippage on large transfers — Pools with <$10M TVL may experience 1-5% slippage on $100K+ transactions
- Bridging illiquid tokens — Ensure destination chain has DEX liquidity before bridging obscure tokens
- Not accounting for gas on destination chain — Bridge enough native tokens (ETH, MATIC, etc.) to pay for transactions on arrival
- Trusting wrapped tokens blindly — Verify wrapped token contracts are legitimate before swapping (scam tokens common)
- Bridging during protocol upgrades — Avoid bridging when protocols announce maintenance windows or upgrades
- Falling for "instant bridge" scams — No legitimate bridge offers instant finality across all chains; be skeptical of unrealistic claims
- Ignoring bridge insurance options — Services like Nexus Mutual offer bridge exploit coverage for eligible protocols
FAQs
What is a cross-chain bridge?
A cross-chain bridge is a protocol that enables asset transfers between different blockchains by locking tokens on the source chain and minting or unlocking equivalent tokens on the destination chain. Bridges use various security models including lock-and-mint, liquidity pools, optimistic verification, and atomic swaps to facilitate interoperability.
Are cross-chain bridges safe?
Bridge security varies significantly by architecture and track record. Bridges secured by proof-of-stake validators (Axelar) or atomic swaps (Meson) offer stronger security than multisig or SMPC models. Historical exploits affecting Wormhole ($325M in 2022) and Multichain ($126M in 2023) highlight risks. Always verify audit reports, exploit history, and validator transparency before bridging significant amounts.
How much do cross-chain bridges cost?
Bridge fees typically range from 0.01% to 0.5% of transfer amount, plus source and destination chain gas fees. Stargate and Across charge 0.01-0.06% for stablecoins, while Axelar charges 0.1-0.5% for broader coverage. Total costs including gas often range from $5-$50 for typical transactions, but can exceed $100 during Ethereum mainnet congestion.
Can I bridge any token between any chains?
No—token bridging depends on protocol support and liquidity availability. Major tokens (USDC, USDT, ETH, WBTC) have deep liquidity on most bridges, while obscure tokens may only bridge via wrapped versions or not at all. Always verify token support on both source and destination chains before attempting transfers.
How long do cross-chain bridge transfers take?
Transfer times range from 1 minute (Across optimistic transfers) to 30+ minutes (Hop during congestion or Multichain on slower chains). Average speeds: Across 1-4 min, Synapse 2-5 min, Stargate 1-15 min, Wormhole 5-20 min. Optimistic bridges are fastest but may delay finality during disputes; lock-and-mint bridges prioritize security over speed.
Do I need native tokens on the destination chain before bridging?
Not for the bridge transaction itself, but you'll need native tokens (ETH on Ethereum, MATIC on Polygon, etc.) to pay gas for any subsequent transactions on the destination chain. Some bridges offer small gas token bridging or faucet integrations, but plan to bridge sufficient native tokens alongside your primary assets.
What happens if my bridge transaction fails?
Failed transactions typically result in automatic refunds to the source address within 24-72 hours, though timelines vary by protocol. Optimistic bridges may take longer during dispute periods. Always save transaction hashes and monitor bridge status pages for updates. Contact protocol support via Discord or Telegram for transactions stuck beyond normal timeframes.
Can I use bridges for NFTs or only fungible tokens?
Most bridges focus on fungible tokens (ERC-20, SPL, etc.), but several support NFT bridging. Wormhole enables NFT transfers across 30+ chains, while specialized solutions like Axelar and Celer support NFT metadata preservation. NFT bridges often charge fixed fees ($5-$20) regardless of NFT value and may take longer than fungible token transfers.
Conclusion + Related Reads
Selecting the right cross-chain bridge depends on your priorities: Stargate Finance delivers the deepest stablecoin liquidity for DeFi-focused traders, Synapse Protocol offers the fastest execution across 20+ chains, and Across Protocol provides the lowest fees for cost-conscious arbitrageurs. Security-first users should consider Meson Finance for atomic swap guarantees or Axelar for institutional-grade proof-of-stake validation. Always test with small amounts, verify destination addresses, and monitor bridge status pages before moving significant capital.
Related Reads:




%201.svg)
%201.svg)




.svg)


%201.svg)

.png)









.svg)




.png)