



How Do I Keep My Cryptocurrency Safe?
%201.svg)
%201.svg)


The cryptocurrency market has created life-changing wealth for millions, but it has also attracted hackers, scammers, and bad actors. From exchange hacks to phishing scams and rug pulls, billions of dollars in crypto have been lost due to poor security practices.
If you’re serious about trading or investing in crypto, one of your top priorities should be keeping your cryptocurrency safe. In this guide, we’ll walk through the biggest risks to your crypto security, best practices to protect your assets, and how Token Metrics can help you make informed, safe decisions when navigating the crypto market.
Why Is Cryptocurrency Security So Important?
Unlike a traditional bank account, cryptocurrency transactions are irreversible. If your funds are stolen, there’s usually no way to recover them.
- No centralized authority: There’s no bank to call for refunds.
- Pseudonymous transactions: It’s nearly impossible to trace funds once they’re moved.
- High-value targets: Hackers actively target crypto investors due to the potential for large payoffs.
This means you are your own bank—and you’re responsible for protecting your funds.
Common Threats to Your Cryptocurrency
Before learning how to protect your crypto, you need to know what you’re up against:
1. Exchange Hacks
Crypto exchanges are frequent targets for hackers. Even top-tier exchanges like Mt. Gox and FTX have experienced devastating losses.
2. Phishing Attacks
Scammers use fake websites, emails, or social media accounts to trick you into revealing your private keys or login credentials.
3. Malware & Keyloggers
Cybercriminals install malicious software on your devices to steal passwords and seed phrases.
4. Rug Pulls & Scams
Fraudulent projects lure investors with promises of high returns, then disappear with the funds.
5. Human Error
Lost passwords, mishandled private keys, or accidental transfers can lead to permanent loss of funds.
How to Keep Your Cryptocurrency Safe
Here’s a step-by-step approach to safeguarding your crypto:
1. Use a Secure Wallet
Hardware Wallets:
- The safest option for long-term storage.
- Devices like Ledger or Trezor keep your private keys offline, out of reach of hackers.
Software Wallets:
- Convenient for active trading but more vulnerable to attacks.
- Use reputable wallets like MetaMask or Trust Wallet and enable strong security features.
Pro Tip: Use a hardware wallet for long-term holdings and a software wallet for small, active trading balances.
2. Enable Two-Factor Authentication (2FA)
Always enable 2FA on your exchange accounts, wallets, and email addresses.
- Use Google Authenticator or Authy, not SMS-based 2FA, which is susceptible to SIM swaps.
3. Beware of Phishing & Fake Websites
- Double-check URLs before logging into exchanges or wallets.
- Never click links from suspicious emails or DMs.
- Bookmark the official websites of your exchanges and platforms.
4. Keep Your Seed Phrase Offline
Your wallet’s seed phrase is the master key to your funds.
- Write it down on paper and store it securely (safe, vault).
- Avoid storing it in digital form (cloud storage, photos).
- Consider splitting the phrase into parts and storing them in separate locations.
5. Research Projects Before Investing
Many scams and rug pulls target uninformed investors chasing hype.
How Token Metrics Helps:
- Use AI-powered Investor Grades to assess projects for long-term viability.
- Leverage Moonshot Finder to discover vetted early-stage tokens with real growth potential—not scams.
6. Diversify Your Storage
Don’t keep all your crypto in one place.
- Use multiple wallets for different purposes (trading vs. holding).
- Spread funds across hardware, software, and exchange wallets.
7. Stay Updated on Threats
The crypto landscape changes fast.
- Follow credible crypto news platforms.
- Monitor regulatory updates and security alerts.
- Use Token Metrics to stay ahead of market narratives and avoid projects flagged as high-risk.
How Token Metrics Helps You Stay Secure
While Token Metrics isn’t a wallet or exchange, it’s a powerful AI-powered platform designed to help you make safer investment decisions.
1. AI-Powered Risk Analysis
Token Metrics uses AI-driven evaluations to score projects, helping you avoid high-risk tokens and scam projects.
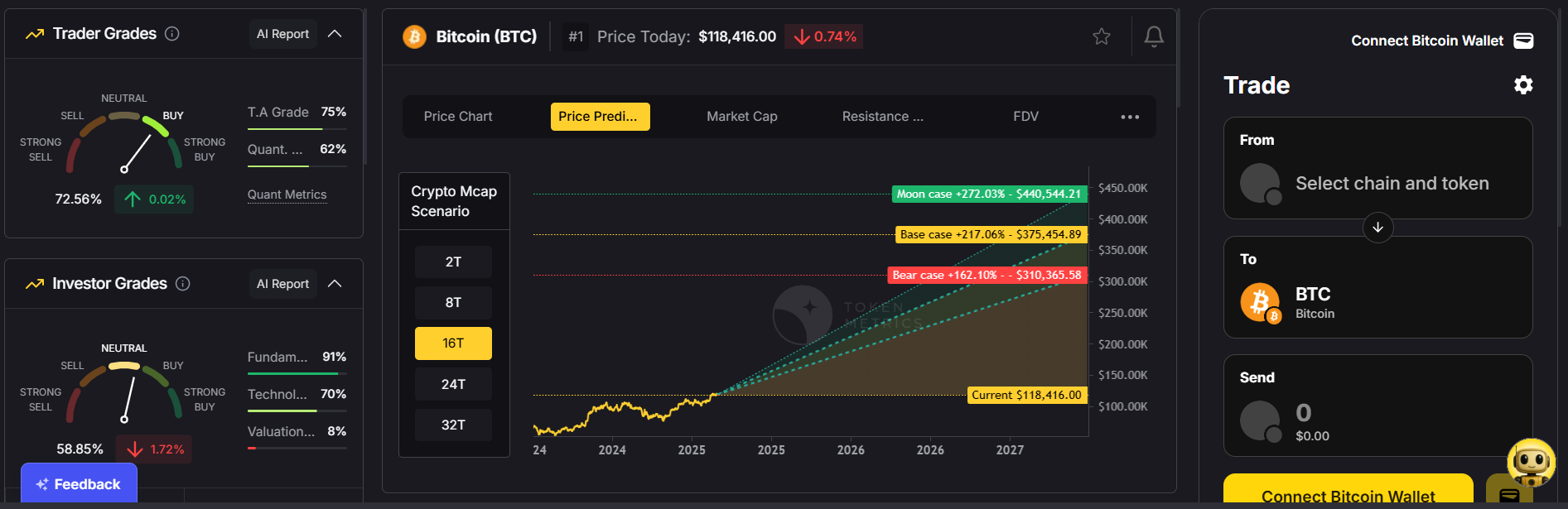
2. Investor & Trader Grades
Our proprietary grading system helps you quickly identify safe, high-quality assets for both short-term trading and long-term holding.
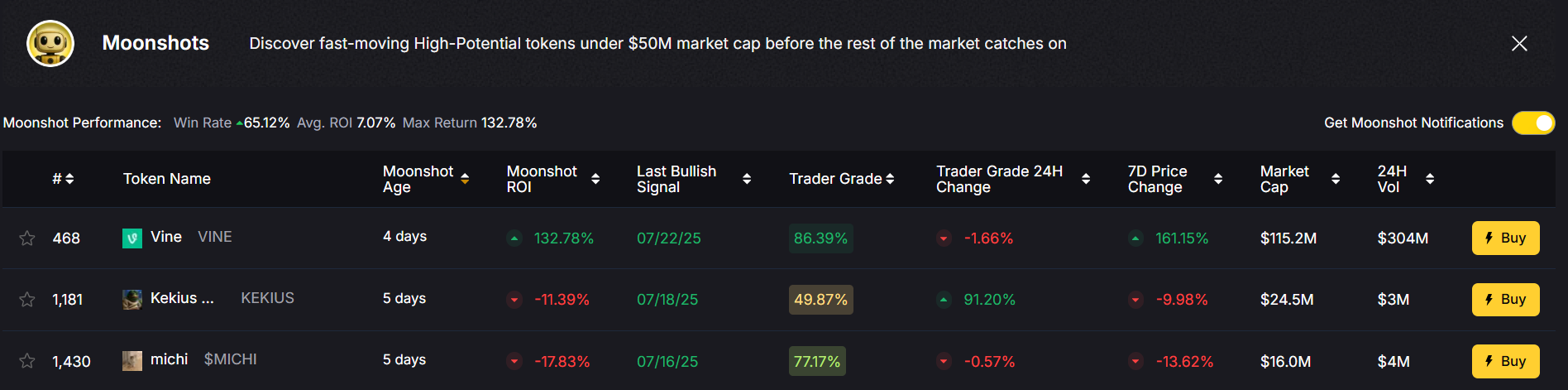
3. Moonshot Finder
Interested in low-cap tokens? The Moonshot Finder helps you spot legitimate early-stage projects before they pump—without falling into scams.
4. Narrative & Market Tracking
Stay ahead of emerging narratives and security concerns with Token Metrics’ real-time AI-driven analysis, helping you dodge risky trends.

Practical Security Checklist for Every Crypto Holder
- Use a hardware wallet for long-term holdings.
- Enable 2FA on all accounts—never rely on SMS-based security.
- Store seed phrases offline and securely.
- Avoid suspicious links and verify all URLs.
- Research every project using platforms like Token Metrics.
- Diversify storage across multiple wallets.
- Stay informed about new threats and market risks.
Final Thoughts
So, how do you keep your cryptocurrency safe? It comes down to strong storage practices, personal vigilance, and making informed investment decisions.
While hardware wallets and 2FA secure your assets, knowing where to invest is just as important. That’s where Token Metrics comes in—using AI-powered analysis to help you avoid scams, choose safe projects, and trade with confidence.
In crypto, you are your own bank—so take your security seriously. And with Token Metrics guiding your decisions, you can navigate this high-risk market safely and profitably.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.