



How Do I Manage Risk in Crypto Trading?
%201.svg)
%201.svg)

Cryptocurrency trading can be highly profitable—but it’s also one of the riskiest markets in the world. Prices can swing wildly in seconds, projects can collapse overnight, and emotional decisions often lead to costly mistakes.
If you want to survive (and thrive) in crypto trading, you must learn how to manage risk effectively. In this guide, we’ll break down why risk management is critical, the top strategies to protect your capital, and how Token Metrics can help you trade smarter, safer, and with more confidence using AI-driven insights.
Why Risk Management Is Non-Negotiable in Crypto
In traditional markets, a 5% price movement is big news. In crypto? Daily moves of 10–20% are normal.
- High volatility: Crypto is more speculative than stocks or forex.
- Unregulated space: Scams and market manipulation are more common.
- Emotional trading: Fear and FOMO lead to poor decisions.
Without a solid risk management plan, even experienced traders can lose everything.
Top Risk Management Strategies for Crypto Trading
1. Only Invest What You Can Afford to Lose
This is rule number one.
- Never invest rent, emergency savings, or money you can’t afford to lose.
- Treat crypto like a high-risk asset class—because it is.
2. Diversify Your Portfolio
Don’t put all your funds into one token.
- Spread across different coins & sectors: Bitcoin, Ethereum, AI tokens, DeFi, etc.
- Balance risk levels: Mix large-cap coins with small-cap moonshots.
How Token Metrics Helps:
Use AI-driven indices to build a diversified, auto-rebalanced portfolio aligned with your risk tolerance.
3. Use Stop-Loss Orders
Set stop-loss levels to automatically sell if prices fall below a certain threshold.
- Prevents small losses from becoming catastrophic.
- Helps maintain discipline during market dips.
Pro Tip: Place stops at strategic support levels, not random round numbers.
4. Size Your Positions Properly
Don’t go “all-in” on one trade.
- Position sizing ensures no single trade wipes out your portfolio.
- A common rule: risk 1–2% of your capital per trade.
5. Avoid Overleveraging
Leverage amplifies gains—but also losses.
- Start with low or no leverage until you’re experienced.
- High leverage trading can lead to instant liquidation in volatile markets.
6. Keep Emotions in Check
Fear, greed, and FOMO (fear of missing out) destroy portfolios.
- Stick to your strategy.
- Don’t chase pumps or panic-sell during dips.
How Token Metrics Helps:
Our AI-powered bullish and bearish signals take emotions out of trading by giving you data-backed entry and exit points.
7. Stay Informed
Markets move on news—regulations, partnerships, or even tweets.
- Follow credible sources for updates.
- Use narrative tracking to spot market-shifting trends early.
How Token Metrics Helps:
Our AI tracks emerging narratives (e.g., AI tokens, DeFi, RWAs), so you can adjust positions before the crowd reacts.
8. Use Risk/Reward Ratios
Before entering a trade, ask:
- Is the potential reward worth the risk?
- Aim for at least a 2:1 or 3:1 reward-to-risk ratio.
9. Practice Secure Asset Storage
Risk management isn’t just about trades—it’s also about keeping your crypto safe.
- Use hardware wallets for long-term holdings.
- Enable 2FA on exchanges.
10. Review & Adjust Your Strategy
Markets evolve—your plan should too.
- Track your wins and losses.
- Optimize your strategy using performance data.
How Token Metrics Helps You Manage Risk
Token Metrics isn’t just a research platform—it’s an AI-powered risk management assistant.
1. AI-Powered Trade Insights
Get real-time bullish and bearish signals to time entries and exits more effectively—reducing impulsive trades.
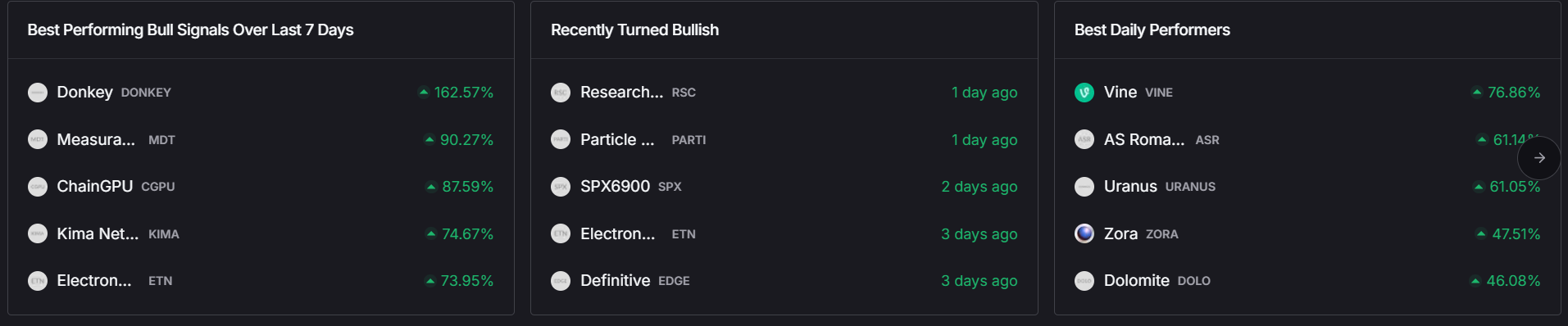
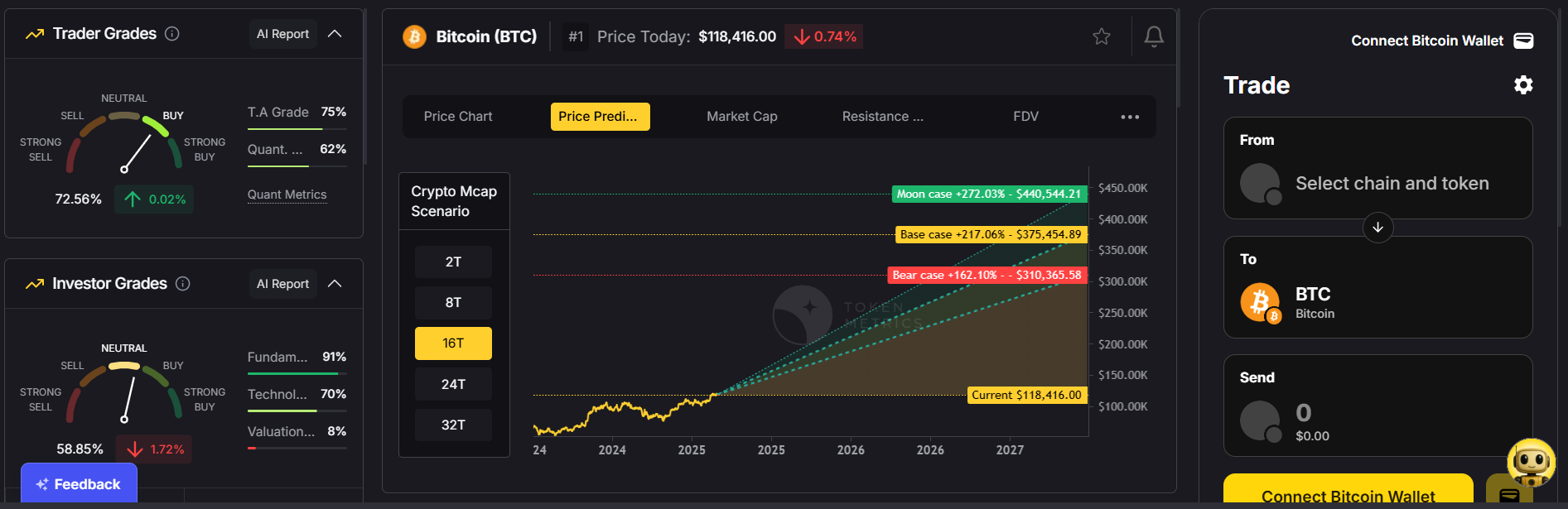
2. Trader & Investor Grades
Quickly assess tokens for short-term trading potential (Trader Grade) or long-term viability (Investor Grade)—helping you avoid high-risk projects.
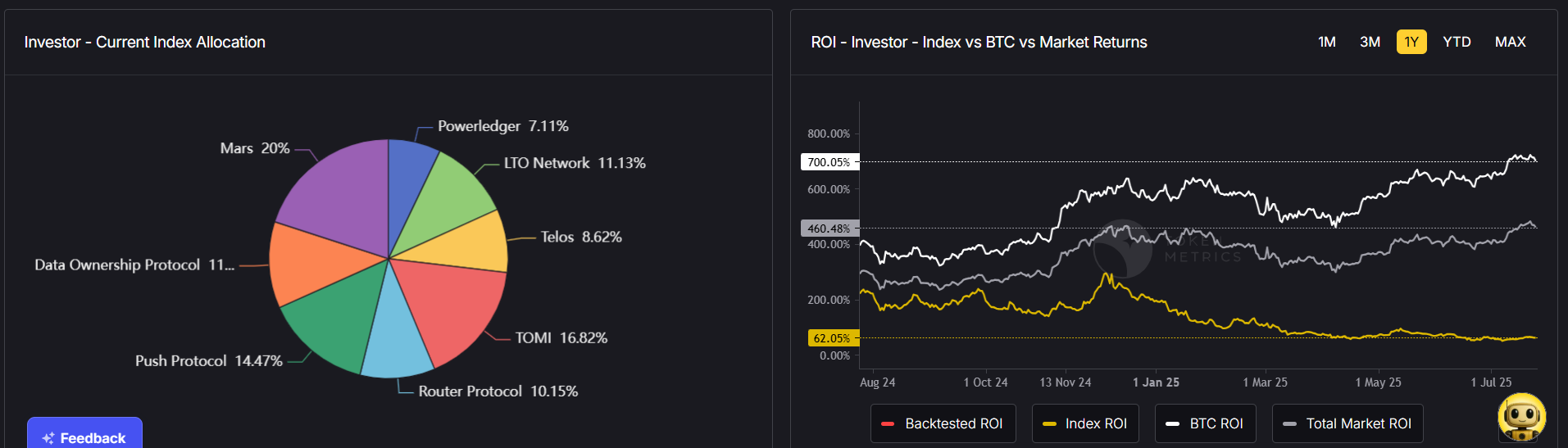
3. AI-Managed Indices
Use auto-rebalanced AI indices to maintain diversification and reduce risk exposure.
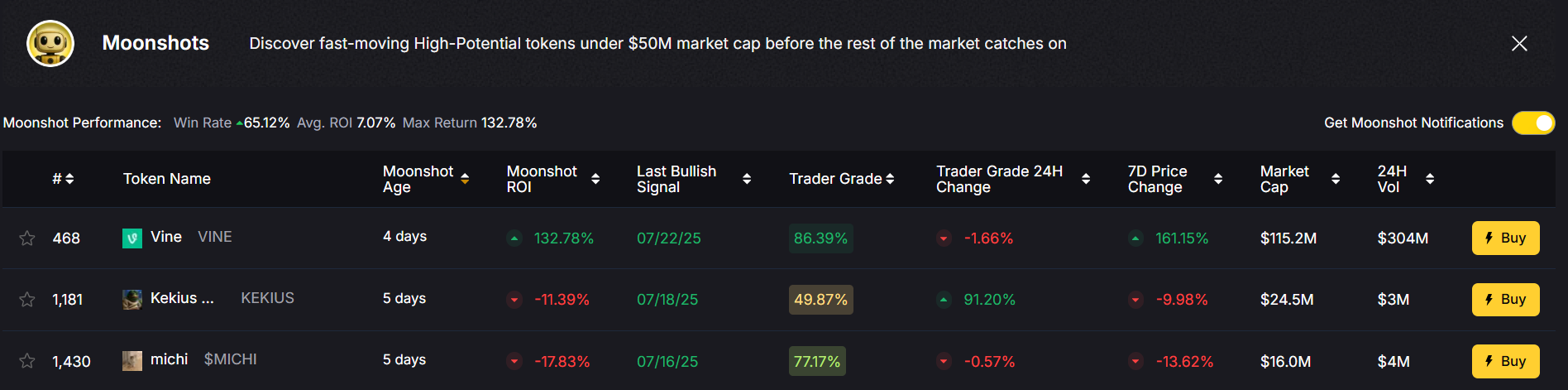
4. Moonshot Finder
Interested in high-risk, high-reward tokens? Our Moonshot Finder filters low-cap projects using AI, helping you avoid scams and rug pulls.
5. Narrative Detection
Our AI tracks emerging narratives so you can anticipate market movements early—reducing exposure to collapsing trends.
Example: Risk Management Using Token Metrics
Imagine you want to invest $5,000 in crypto:
- Without Token Metrics: You randomly choose 3 coins based on hype and YouTube videos. Two collapse, and your portfolio drops 50%.
- With Token Metrics: You build a diversified AI-managed index of large-cap and promising small-cap tokens, use stop-loss levels, and set alerts for bullish/bearish signals. Your portfolio drops only 10% in a downturn—saving thousands.
This is how data-driven trading transforms risk into opportunity.
Practical Risk Management Checklist
- Never invest more than you can afford to lose.
- Diversify across coins and sectors.
- Use stop-loss orders to cap losses.
- Avoid overleveraging at all costs.
- Set realistic reward-to-risk ratios (2:1 or better).
- Use AI-powered tools like Token Metrics for smarter trades.
- Stay informed about news and emerging narratives.
- Secure your assets with hardware wallets and 2FA.
- Track and adjust your trading strategy regularly.
- Trade with logic, not emotions.
Final Thoughts
So, how do you manage risk in crypto trading? It’s about balancing your portfolio, using smart tools, and staying disciplined.
While volatility is unavoidable, you can control how much you’re exposed to it. With Token Metrics, you gain AI-powered insights, trade signals, and portfolio tools that help you reduce risks while maximizing opportunities.
In crypto, it’s not just about making profits—it’s about keeping them.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.