



How Does Bitcoin Differ from Ethereum: A Comprehensive Guide
%201.svg)
%201.svg)


Bitcoin and Ethereum stand as the two most influential digital assets in the crypto market, commanding the largest market capitalization and driving innovation across the cryptocurrency space. While both leverage blockchain technology and represent leading digital assets, they serve fundamentally different purposes and operate through distinct technical architectures.
Understanding how bitcoin differs from ethereum requires examining their core philosophies, technical implementations, and real-world applications. Bitcoin functions primarily as a decentralized digital currency and store of value, while Ethereum operates as a flexible platform for smart contracts and decentralized applications. These fundamental differences ripple through every aspect of their design, from consensus mechanisms to investment considerations.
This comprehensive analysis explores the key differences between these blockchain pioneers, helping investors and enthusiasts understand their unique value propositions in the evolving global markets.
Core Purpose and Philosophy
Bitcoin was conceived as digital gold and a decentralized digital currency, launched in 2009 by the pseudonymous Satoshi Nakamoto. The bitcoin network was designed to address the fundamental problem of double-spending in digital transactions without requiring a central authority. Bitcoin aims to serve as an alternative to traditional monetary systems, emphasizing censorship resistance, predictability, and long-term value preservation.
Ethereum emerged in 2015 through the vision of Vitalik Buterin and the ethereum foundation, serving as a programmable blockchain platform for smart contracts and decentralized applications. Rather than competing directly with bitcoin as digital money, Ethereum positions itself as a “world computer” that can execute complex financial transactions and automate agreements through smart contract technology.
The philosophical divide runs deep: Bitcoin prioritizes security, decentralization, and conservative monetary policy with minimal changes to its core protocol. Bitcoin focuses on being the most secure and reliable digital asset, maintaining backward compatibility and requiring overwhelming consensus for any protocol modifications.
Ethereum emphasizes innovation, flexibility, and rapid development of decentralized technologies. Ethereum developers actively pursue technical improvements to enhance scalability, reduce energy consumption, and expand functionality. This approach enables Ethereum to evolve quickly but introduces more complexity and potential points of failure.
Bitcoin’s simplicity and laser focus on monetary use cases contrasts sharply with Ethereum’s ambitious goal to decentralize internet services and create a new foundation for digital finance and Web3 applications.
Technical Architecture Differences
The technical architecture reveals fundamental differences in how these networks operate and validate transactions. Bitcoin uses a Proof-of-Work consensus mechanism requiring energy-intensive mining operations, where bitcoin miners compete to solve cryptographic puzzles and secure the bitcoin blockchain. This process generates new blocks approximately every 10 minutes, ensuring predictable transaction settlement and robust security.
Ethereum originally used Proof-of-Work but completed its transition to Proof-of-Stake through “The Merge” in September 2022. The ethereum network now relies on validators who stake ETH to propose and validate new blocks every 12 seconds. This shift dramatically reduced ethereum’s energy consumption while enabling more rapid transaction processing and network upgrades.
Bitcoin supports limited scripting capabilities focused on secure value transfer and basic programmable transactions. Recent upgrades like Taproot have expanded Bitcoin’s scripting abilities while maintaining its conservative approach to functionality. The bitcoin blockchain prioritizes reliability and predictability over programmability.
Ethereum features Turing-complete smart contracts through the Ethereum Virtual Machine (EVM), enabling developers to build complex decentralized applications without intermediaries. The ethereum blockchain serves as the core infrastructure for thousands of decentralized finance protocols, NFT marketplaces, and Web3 applications.
Transaction throughput differs significantly: Bitcoin processes approximately 5-7 transactions per second on its base layer, while Ethereum handles 12-15 transactions per second. Both networks face scalability constraints on their base layers, leading to different approaches for increasing capacity.
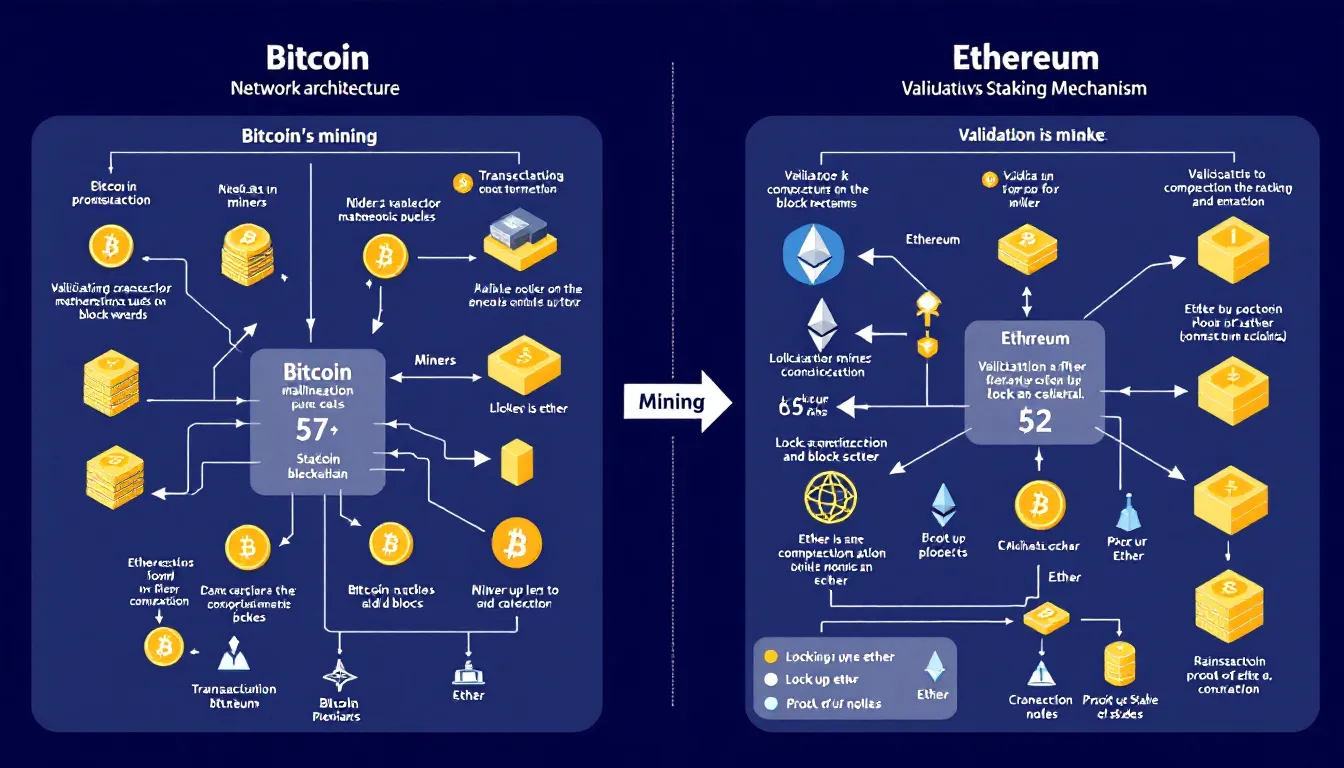
Supply Models and Monetary Policy
Bitcoin’s monetary policy represents one of its most distinctive features: a fixed supply capped at 21 million coins with halving events every four years that reduce new issuance. This finite supply creates predictable scarcity and positions bitcoin as a hedge against inflation and currency debasement. Bitcoin’s supply schedule remains unchanged since its launch, providing long-term certainty for holders.
Ethereum implements a dynamic supply model with no fixed cap, currently maintaining around 120 million ETH in circulation. Unlike bitcoin’s supply, Ethereum’s tokenomics have evolved significantly since launch. The implementation of EIP-1559 introduced fee burning, where a portion of transaction fees gets permanently removed from circulation, creating deflationary pressure during periods of high network activity.
Bitcoin’s halving events create predictable supply reduction approximately every four years, cutting mining rewards in half and historically driving significant price appreciation. These events are programmed into the protocol and cannot be changed without overwhelming network consensus.
Ethereum’s supply adjusts based on network usage and validator participation. During periods of high transaction volume and DeFi activity, ethereum’s fee burning can exceed new ETH issuance, making the native cryptocurrency deflationary. This mechanism ties ethereum’s monetary policy directly to network utility and adoption.
The contrasting approaches reflect each network’s priorities: Bitcoin emphasizes monetary predictability and long-term store of value characteristics, while Ethereum aligns its economics with platform usage and technological development.
Smart Contracts and Applications
Bitcoin supports basic scripting for simple programmable transactions, multi-signature wallets, and time-locked contracts. Recent technical improvements through Taproot have enhanced Bitcoin’s scripting capabilities while maintaining its focus on security and simplicity. These features enable applications like atomic swaps and more sophisticated payment channels, but Bitcoin deliberately limits complexity to preserve network security.
Ethereum pioneered smart contracts, enabling complex decentralized applications that operate without intermediaries or central control. Smart contract functionality allows developers to create autonomous financial protocols, governance systems, and digital asset management platforms. The ethereum blockchain hosts the vast majority of decentralized finance activity, NFT trading, and tokenized assets.
Ethereum’s programmability has spawned an entire ecosystem of decentralized applications across numerous sectors. DeFi protocols on Ethereum facilitate lending, borrowing, trading, and yield farming with billions of dollars in total value locked. NFT marketplaces, gaming platforms, and decentralized autonomous organizations (DAOs) represent additional use cases unique to programmable blockchains.
Bitcoin applications focus primarily on payments, store of value, and Layer-2 solutions like bitcoin’s lightning network. The Lightning Network enables instant, low-cost Bitcoin payments through payment channels, expanding Bitcoin’s utility for everyday transactions while preserving the main chain’s security and decentralization.
Ethereum’s flexibility enables diverse use cases from supply chain management to insurance protocols, but this complexity introduces additional security considerations and potential smart contract vulnerabilities that don’t exist in Bitcoin’s simpler model.

Scalability Solutions
Bitcoin and Ethereum pursue different scaling philosophies to address throughput limitations. Bitcoin scales primarily through off-chain solutions that preserve the base layer’s simplicity, security, and decentralization. This approach maintains full node accessibility with minimal hardware requirements, ensuring anyone can validate the bitcoin network independently.
Bitcoin’s lightning network represents the primary scaling solution, creating payment channels that enable instant, low-cost transactions without broadcasting every payment to the main blockchain. While promising for micropayments and frequent transactions, the Lightning Network requires additional technical complexity and liquidity management.
Ethereum uses a multi-layered scaling approach combining Layer-2 rollups with planned on-chain improvements like sharding. Layer-2 solutions such as Arbitrum, Optimism, and Polygon process transactions off the main ethereum blockchain while inheriting its security guarantees. These scaling solutions already handle thousands of transactions per second with significantly lower fees.
Ethereum’s modular scaling architecture aims to boost capacity through multiple parallel solutions rather than increasing base layer throughput. This approach allows specialized Layer-2 networks to optimize for specific use cases while maintaining composability with the broader ethereum ecosystem.
The planned implementation of sharding will further increase ethereum’s capacity by dividing the network into multiple parallel chains. Combined with Layer-2 rollups, this architecture could enable millions of transactions per second across the ethereum network while maintaining decentralization and security.
Market Performance and Volatility
Bitcoin typically exhibits lower volatility compared to Ethereum and often serves as a portfolio diversifier during broader market uncertainty. As the original cryptocurrency and largest digital asset by market cap, Bitcoin tends to lead market cycles and attract institutional investment as a digital store of value and inflation hedge.
Ethereum historically shows approximately 30% higher volatility than Bitcoin due to its exposure to decentralized finance activity, NFT trading volumes, and smart contract platform competition. Ethereum’s price reflects not just investment demand but also utility demand from users paying transaction fees and interacting with decentralized applications.
Bitcoin’s price correlates strongly with adoption as digital gold, institutional investment flows, and macroeconomic factors affecting traditional safe-haven assets. Major institutional announcements, regulatory developments, and central bank monetary policy significantly impact Bitcoin’s valuation.
Ethereum’s value reflects usage in DeFi protocols, NFT marketplaces, and smart contract deployment. Network congestion, Layer-2 adoption, and competition from alternative smart contract platforms influence ethereum’s price beyond pure investment demand.
Both bitcoin and ethereum respond to broader macroeconomic factors, but Ethereum shows stronger correlation to technology sector performance due to its role as a platform for innovation. Investment companies and hedge funds often hold both assets to balance stability with exposure to blockchain technology growth.
Developer Ecosystems and Governance
Bitcoin development follows a conservative, consensus-driven approach through Bitcoin Improvement Proposals (BIPs) that require extensive testing and broad community agreement. Bitcoin developers prioritize backward compatibility and security over rapid feature deployment, resulting in slower but more deliberate protocol evolution.
Ethereum development moves rapidly through Ethereum Improvement Proposals (EIPs) and coordinated leadership from the ethereum foundation and core development teams. This governance model enables faster innovation but concentrates more decision-making authority in the hands of key developers and researchers.
Bitcoin’s decentralized development process prevents unilateral changes to the protocol, requiring overwhelming consensus from users, miners, and developers. This approach protects against contentious forks and preserves Bitcoin’s monetary policy, but can slow adoption of beneficial upgrades.
Ethereum regularly implements protocol upgrades to improve functionality, reduce fees, and address scalability challenges. The coordinated development process enables ambitious technical roadmaps but raises questions about centralization of development decisions.
The underlying technology differences extend to developer tooling and ecosystem support. Ethereum offers extensive development frameworks, testing environments, and educational resources for building decentralized applications. Bitcoin development focuses more narrowly on protocol improvements and second-layer solutions.
Both networks benefit from active open-source communities, but Ethereum attracts more application developers while Bitcoin emphasizes protocol and infrastructure development.
Energy Consumption and Environmental Impact
Energy consumption represents one of the most significant differences between Bitcoin and Ethereum post-Merge. Bitcoin’s Proof-of-Work mining consumes substantial energy but secures the world’s most valuable cryptocurrency network with unmatched computational power and geographic distribution.
Current estimates place Bitcoin’s annual energy consumption between 70-130 TWh, comparable to small countries. However, bitcoin miners increasingly utilize renewable energy sources and drive clean energy adoption by monetizing stranded renewable capacity and excess energy production.
Ethereum’s transition to Proof-of-Stake reduced energy consumption by approximately 99.9% after The Merge, making it one of the most energy-efficient blockchain networks. Ethereum’s PoS consensus requires ETH staking rather than energy-intensive mining operations, dramatically reducing its environmental footprint.
The energy debate influences institutional adoption decisions, with some investment companies preferring ethereum’s lower environmental impact while others value Bitcoin’s proven security model despite higher energy usage. Environmental, social, and governance (ESG) considerations increasingly factor into cryptocurrency investment decisions.
Bitcoin proponents argue that energy consumption secures the network and incentivizes renewable energy development, while Ethereum supporters emphasize the efficiency gains from Proof-of-Stake consensus. Both perspectives reflect valid priorities in balancing security, decentralization, and environmental responsibility.
Investment Considerations
Bitcoin serves as an inflation hedge and uncorrelated asset for portfolio diversification, appealing to investors seeking exposure to digital gold characteristics without traditional precious metals storage challenges. Bitcoin’s established track record, regulatory clarity, and institutional adoption make it attractive for conservative cryptocurrency allocation.
Ethereum offers exposure to Web3 growth and decentralized finance innovation, providing leverage to the expanding blockchain application ecosystem. Investors choosing Ethereum bet on the continued growth of smart contract platforms and decentralized applications beyond simple value transfer.
Both assets face similar regulatory challenges, but Bitcoin benefits from clearer legal status in many jurisdictions due to its commodity-like characteristics. Ethereum’s classification remains more complex due to its programmable features and the potential for securities regulations to apply to certain tokens and applications.
Bitcoin provides returns primarily through price appreciation, though lending platforms offer yields similar to staking rewards. Ethereum enables native staking rewards of approximately 3-5% annually plus potential price appreciation, providing income generation alongside capital gains potential.
Portfolio construction often includes both bitcoin and ethereum to balance stability with growth potential. Many institutional investors and investment strategy frameworks recommend exposure to both assets given their different risk profiles and correlation patterns with traditional asset classes.
The choice between bitcoin vs ethereum often depends on investment objectives, risk tolerance, and beliefs about the future of digital money versus programmable blockchain platforms.
Future Outlook and Development Roadmaps
Bitcoin’s development roadmap focuses on gradual improvements like Taproot adoption, sidechains development, and bitcoin’s lightning network expansion. Future development emphasizes incremental enhancements to privacy, scripting capabilities, and second-layer scaling while maintaining the core protocol’s simplicity and security.
Ethereum pursues ambitious upgrades including sharding implementation, proto-danksharding for rollup scaling, and continued Layer-2 ecosystem development. Ethereum’s future events include account abstraction for improved user experience and continued optimization of the Proof-of-Stake consensus mechanism.
Bitcoin’s conservative approach prioritizes stability and gradual feature addition, with major changes requiring years of testing and community consensus. This methodology protects against unintended consequences but may limit Bitcoin’s ability to compete with more flexible blockchain platforms.
Ethereum faces competition from newer Layer-1 blockchains offering faster transactions and lower fees, but maintains significant advantages in developer mindshare, ecosystem maturity, and network effects. Ethereum’s roadmap addresses scalability concerns while preserving decentralization and security.
Both networks continue evolving to meet different needs in the expanding cryptocurrency ecosystem. Bitcoin solidifies its position as digital gold and the leading store of value cryptocurrency, while Ethereum develops as the primary platform for decentralized applications and financial innovation.
The fundamental differences between these networks suggest complementary rather than competitive futures, with each serving distinct roles in the broader digital asset landscape. Future performance will depend on continued technical development, regulatory clarity, and mainstream adoption across different use cases.
Key Takeaways
Understanding how bitcoin differs from ethereum reveals two complementary approaches to blockchain technology and digital assets. Bitcoin excels as a decentralized digital currency and store of value with predictable monetary policy and uncompromising security focus. Ethereum leads in programmable blockchain capabilities, enabling complex decentralized finance applications and serving as the foundation for Web3 innovation.
The key differences span every aspect from consensus mechanisms and energy consumption to governance philosophies and investment characteristics. Bitcoin’s Proof-of-Work mining and fixed supply contrast sharply with Ethereum’s Proof-of-Stake validation and dynamic tokenomics. Both bitcoin and ethereum offer distinct value propositions for different investor goals and risk profiles.
Rather than viewing these as competing cryptocurrencies, many investors and institutions recognize both bitcoin and ethereum as foundational digital assets serving different purposes in a diversified portfolio. Bitcoin provides stability and inflation hedging characteristics, while Ethereum offers exposure to technological innovation and the growing decentralized application ecosystem.
As the cryptocurrency space continues maturing, both networks face ongoing challenges around scalability, regulation, and competition. However, their established network effects, developer communities, and institutional adoption suggest continued relevance in the evolving digital asset landscape.
For investors considering exposure to cryptocurrency markets, understanding these fundamental differences enables more informed decision-making about portfolio allocation and investment strategy. Whether choosing Bitcoin’s digital gold characteristics or Ethereum’s programmable platform capabilities, both assets represent significant innovations in monetary technology and decentralized systems.
This content is for educational purposes only and should not be considered investment advice. Cryptocurrency investments carry significant risks, and past performance does not guarantee future results. Always consult with qualified financial advisors and conduct thorough research before making investment decisions.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.