



How Much Money Do I Need to Start Crypto Trading?
%201.svg)
%201.svg)


Cryptocurrency trading has revolutionized how people invest, allowing anyone with an internet connection to access global markets 24/7. But one of the most common questions beginners ask is: "How much money do I need to start trading crypto?"
The answer depends on your goals, risk tolerance, and the strategies you intend to use. In this article, we’ll explore how much you really need to get started, break down different trading approaches, and explain how platforms like Token Metrics can help you trade smarter with AI-driven insights—even with a small budget.
Understanding Crypto Trading: The Basics
Before determining how much money you need, it’s essential to understand what crypto trading involves. Cryptocurrency trading is the process of buying and selling digital assets like Bitcoin, Ethereum, and altcoins to profit from price movements. Unlike traditional stock markets, crypto markets:
- Operate 24/7, offering constant trading opportunities.
- Allow fractional ownership, meaning you can buy a small portion of a cryptocurrency instead of a whole coin.
- Have low barriers to entry, enabling traders to start with minimal funds.
However, the volatile nature of crypto means your starting amount must align with your risk management plan.
How Much Money Do You Need to Start Crypto Trading?
There’s no single amount required to start trading crypto—it largely depends on your trading style, goals, and platform. Here’s a breakdown:
1. The Absolute Minimum: $10–$50
Most exchanges like Binance, Coinbase, and Kraken allow users to start trading with as little as $10–$50. This is a great entry point for beginners who want to learn the ropes without risking too much.
- Pros:
- Low financial commitment.
- Great for testing strategies.
- Less emotional stress compared to larger investments.
- Low financial commitment.
- Cons:
- Limited profit potential.
- Transaction fees may eat into gains.
- Limited profit potential.
2. A Practical Starting Point: $250–$500
Many beginner traders find $250–$500 to be a sweet spot. This amount allows for diversification—spreading funds across multiple tokens—and gives you enough margin to experiment with different strategies.
- Example:
- $200 in Bitcoin or Ethereum (low-risk, high-liquidity assets).
- $100–$200 in promising altcoins (higher growth potential).
- $50–$100 reserved for short-term trades.
- $200 in Bitcoin or Ethereum (low-risk, high-liquidity assets).
This amount balances risk and opportunity, helping you learn without overexposing yourself.
3. For Serious Traders: $1,000+
If your goal is to actively trade (day trading, swing trading, or building a diversified portfolio), starting with $1,000+ gives you more flexibility.
- Why?
- Allows for better diversification across multiple crypto assets.
- Provides room to absorb market volatility without liquidating too early.
- Enables you to take advantage of advanced tools and AI-driven insights on platforms like Token Metrics.
- Allows for better diversification across multiple crypto assets.
Factors That Influence How Much You Should Start With
When deciding how much to invest, consider these factors:
1. Risk Tolerance
Crypto is volatile—price swings of 10–20% in a single day are common. Only invest what you can afford to lose.
2. Trading Goals
Are you aiming for quick profits (day trading), medium-term growth (swing trading), or long-term wealth (HODLing)? Your goals will dictate your starting amount.
3. Trading Strategy
Scalping or day trading requires more capital for frequent trades, while long-term investing can start with smaller amounts.
4. Fees
Trading fees, withdrawal fees, and network fees can impact your profits. Some exchanges have minimum trade sizes, so starting with too little might not be practical.
How Token Metrics Helps You Trade Smarter—Even with a Small Budget
Starting with a small amount doesn’t mean you can’t succeed. With AI-driven research and trading tools, platforms like Token Metrics level the playing field for beginners and experienced traders alike.

Here’s how Token Metrics can help:
1. AI-Powered Trading Signals
Token Metrics provides real-time bullish and bearish signals based on 80+ data points. This helps you make smarter entry and exit decisions—crucial when trading with limited funds.
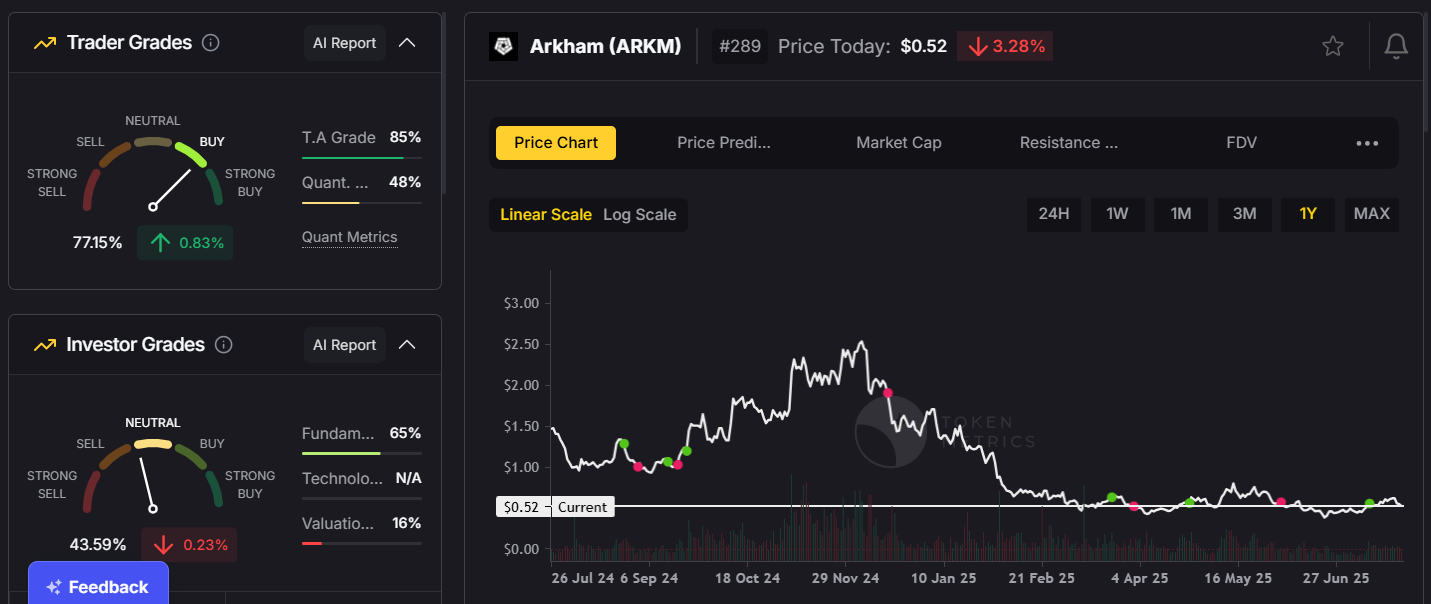
2. Proprietary Trader and Investor Grades
Our Trader and Investor Grades score tokens based on short-term and long-term potential, helping you focus on assets with the best risk-reward profile.
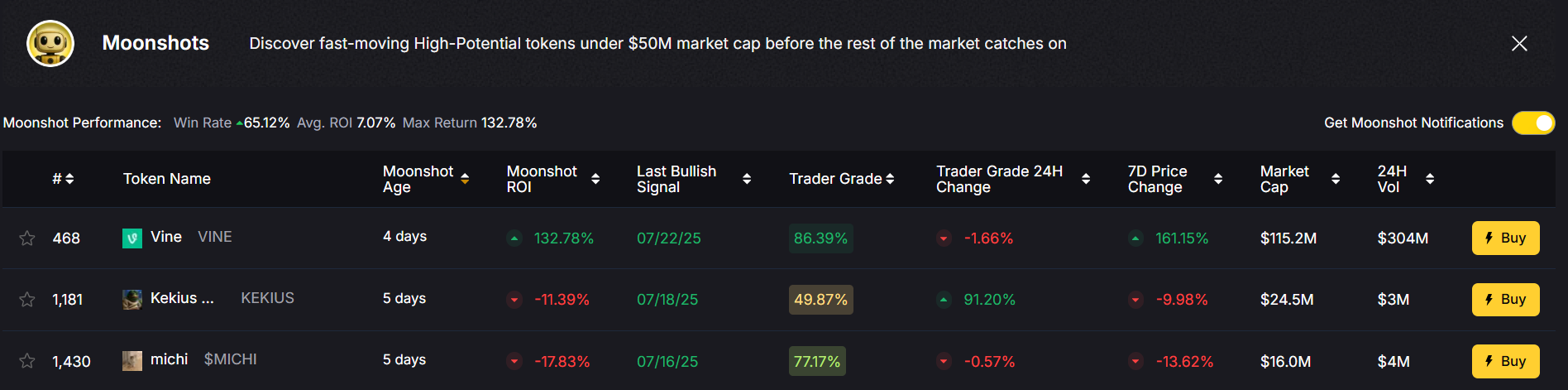
3. Moonshot Finder for Low-Cap Opportunities
Want to turn a small investment into something bigger? Token Metrics’ Moonshot Finder identifies high-potential low-cap altcoins before they pump, giving you an edge.
4. AI Indices & Auto-Managed Portfolios
Don’t know where to start? Token Metrics offers AI-driven crypto indices, automatically managing a diversified portfolio based on current market conditions.
5. Free & Flexible Plans
Whether you’re starting with $0 or $166.7 per month, Token Metrics offers free and paid plans to match your needs.
Can You Really Make Money Starting Small?
Yes, you can—but it requires patience, strategy, and the right tools. Many traders have grown $100–$500 portfolios into thousands by leveraging long-term investments in quality projects and AI-guided trading signals.
- Example:
- A $100 investment in Ethereum in early 2020 would have grown to over $4,000 by 2021.
- A $50 investment in a low-cap moonshot token could multiply 10x or more if chosen wisely.
- A $100 investment in Ethereum in early 2020 would have grown to over $4,000 by 2021.
Best Practices for Starting Small in Crypto Trading
- Start with what you can afford to lose – Never invest rent or essential funds.
- Diversify your portfolio – Spread your investment across multiple tokens.
- Use AI-powered tools – Platforms like Token Metrics reduce guesswork and improve decision-making.
- Avoid emotional trading – Stick to your strategy and avoid panic-selling.
- Stay educated – Follow market trends, join crypto communities, and use analytical tools.
Final Thoughts
So, how much money do you need to start crypto trading?
The truth is—you can start with as little as $10, but for a more meaningful experience and potential growth, $250–$1,000 is a practical starting range.
The key isn’t just the amount—it’s how you trade. Using AI-driven insights from Token Metrics, you can make smarter decisions, find hidden gems, and navigate crypto’s volatility like a pro.
Whether you’re starting small or diving in with a bigger budget, Token Metrics helps you trade confidently and build a strategy tailored to your goals.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.