



How to Build a Profitable Crypto Portfolio in 2025: Strategies, Tools, and AI Insights
%201.svg)
%201.svg)

Introduction: Why a Smart Portfolio Matters in 2025
The cryptocurrency market in 2025 has matured into a multi‑trillion‑dollar ecosystem, offering opportunities across Bitcoin, altcoins, DeFi platforms, AI‑powered tokens, and real‑world asset tokenization projects. However, with opportunity comes complexity — and building a profitable portfolio requires more than just guessing which coins might pump next.
Success now depends on strategic allocation, data‑driven decision‑making, and leveraging advanced tools like Token Metrics to analyze market trends and optimize performance. This guide will walk you through how to construct and maintain a profitable crypto portfolio in 2025.
Step 1: Define Your Investment Goals
Before choosing any assets, decide on your objectives:
- Long‑Term Growth (HODLing): Focus on established assets like Bitcoin (BTC), Ether (ETH), and Token Metrics AI (TMAI).
- Income Generation: Use staking and yield farming to earn passive income on assets like ETH or Cardano (ADA).
- High‑Risk, High‑Reward: Allocate a smaller portion to emerging altcoins or narrative‑driven tokens (AI, DeFi, or Layer 2 scaling solutions).
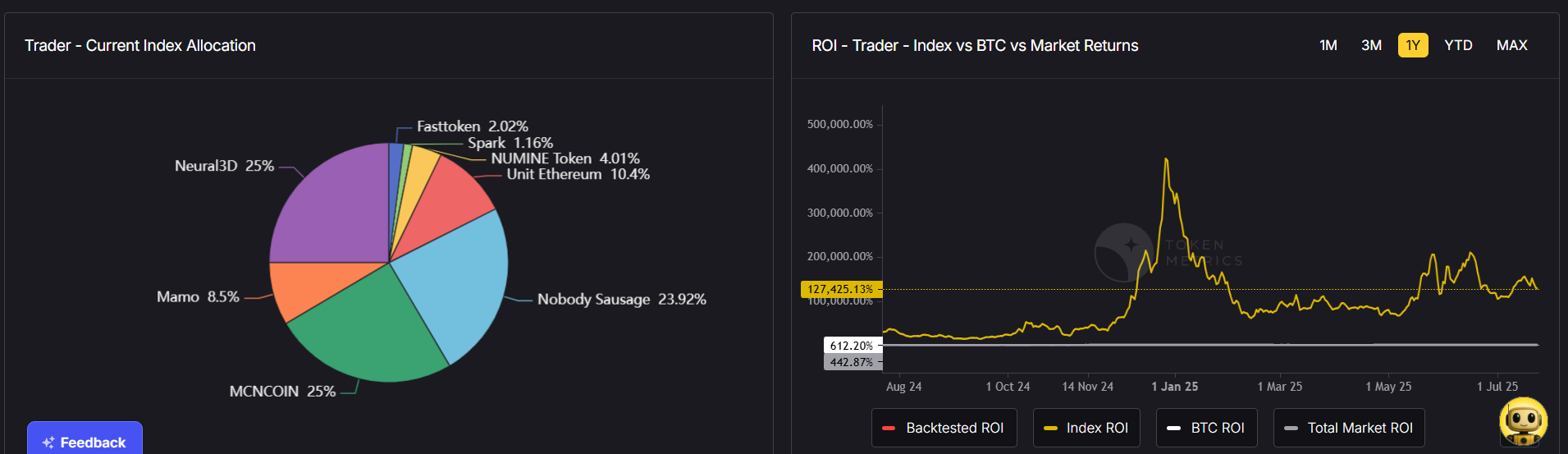
Having clear goals will guide how much risk to take and which assets to prioritize.
Step 2: Diversify Your Portfolio
Diversification remains the cornerstone of a strong crypto portfolio. In 2025, this means spreading across:
1. Large‑Cap Coins (40–50%):
Stable, highly liquid assets like BTC and ETH provide security and long‑term growth.
2. Mid‑Cap Coins (25–30%):
Projects like Polygon (MATIC) or Arbitrum (ARB) with strong fundamentals and adoption potential.
3. Small‑Cap Gems (10–20%):
High‑risk projects like AI tokens (TMAI) or early‑stage DeFi protocols with explosive upside.
4. Stablecoins (5–10%):
USDC or USDT for liquidity management, making it easier to buy dips or take profits quickly.
Step 3: Use Narrative‑Driven Investing
In crypto, narratives drive capital flows. Spotting the right trends early can turn modest investments into significant gains.
Hot narratives for 2025 include:
- AI‑Powered Tokens: Projects like Token Metrics AI (TMAI) and Fetch.ai (FET) at the intersection of blockchain and artificial intelligence.
- Real‑World Asset Tokenization (RWAs): Platforms bringing real estate, commodities, and traditional assets on‑chain.
- DeFi 2.0: Next‑gen decentralized finance projects offering lower fees and better yields.
- Layer 2 Scaling Solutions: Protocols like Polygon and Optimism making Ethereum more scalable and cost‑effective.
Pro Tip: Use Token Metrics’ narrative detection tools to spot these trends early.
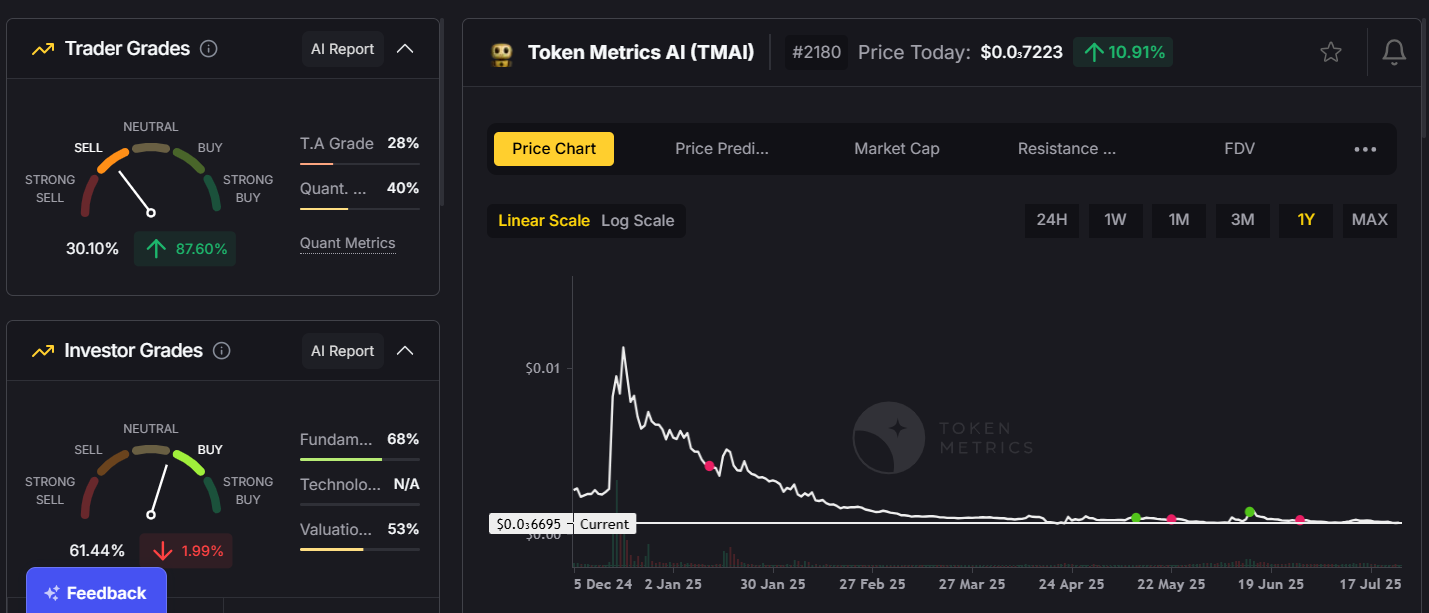
Step 4: Leverage AI‑Powered Tools
Building a profitable portfolio requires cutting‑edge analytics, and AI is a game‑changer in 2025.
Token Metrics provides:
- AI‑Generated Coin Ratings: Evaluating over 80 data points to rank tokens based on fundamentals, technicals, and sentiment.
- Portfolio Optimization: Suggesting the best asset mix based on your goals and risk appetite.
- Trend Analysis & Narrative Detection: Identifying early‑stage market narratives before they go mainstream.
- Real‑Time Alerts: Helping you react quickly to price swings or emerging opportunities.
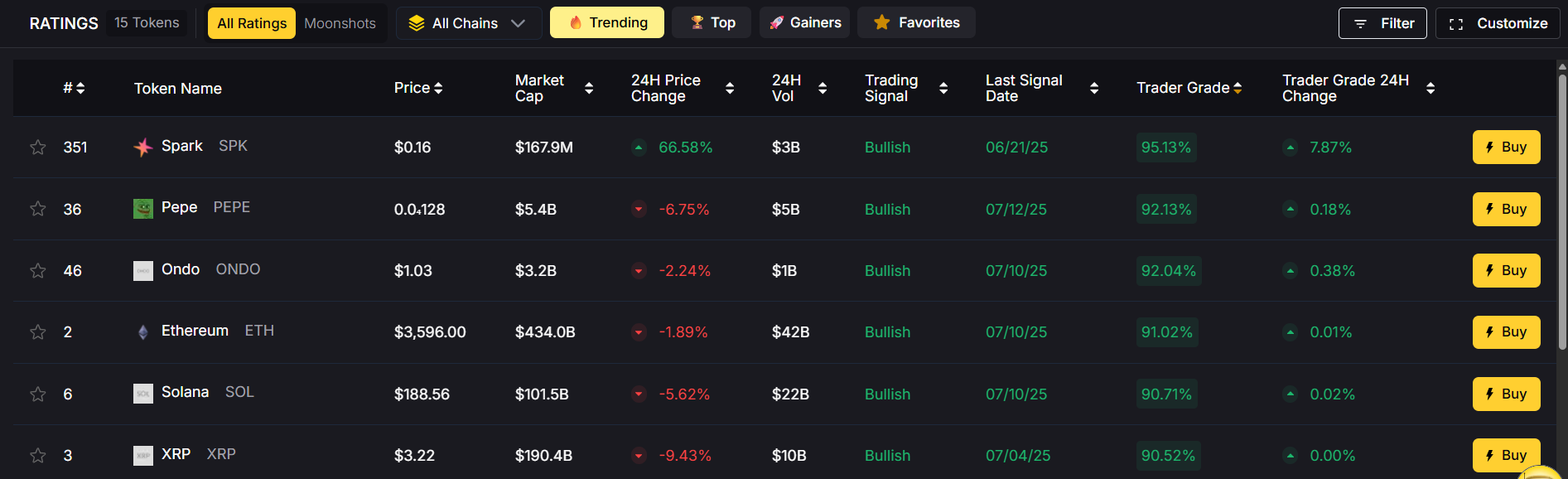
These insights give you a data‑driven edge in a volatile market.
Step 5: Balance Risk and Reward
Managing risk is as important as chasing gains. Key practices include:
- Position Sizing: Don’t overallocate to small‑cap coins — keep them to 10–20% of your portfolio.
- Stop‑Loss Orders: Automate exits to prevent catastrophic losses.
- Regular Rebalancing: Adjust your portfolio quarterly or when an asset becomes overweight.
- Take Profits Strategically: Don’t wait for the top — sell portions at set profit targets.
Step 6: Include Income‑Generating Assets
In addition to growth, aim for consistent income streams:
- Staking: Earn rewards by staking ETH, ADA, or other PoS assets.
- Yield Farming: Participate in DeFi protocols to generate additional returns.
- Liquid Staking: Use platforms like Lido to stake while keeping tokens tradable.
Token Metrics’ staking analytics help you find the best yields while minimizing risk.
Step 7: Monitor and Adjust Your Portfolio
Crypto markets change fast. What worked six months ago might not work today.
Regularly monitor:
- On‑Chain Metrics: Wallet activity, transaction volume, and developer contributions.
- Market Sentiment: Use AI‑driven insights from Token Metrics to track shifts in investor mood.
- Regulatory Updates: Stay informed on new laws impacting crypto investments.
By actively managing your portfolio, you’ll avoid being caught off guard by market shifts.
Practical Example of a 2025 Portfolio
Long‑Term Growth Portfolio:
- 40% Bitcoin (BTC): Stability and long‑term appreciation.
- 30% Ethereum (ETH): Smart contract exposure + staking income.
- 15% Narrative‑Driven Tokens (TMAI, FET, MATIC): Growth from AI and Layer 2 solutions.
- 10% DeFi Protocols (AAVE, UNI): Yield opportunities.
- 5% Stablecoins (USDC): Liquidity for dips or rebalancing.
This allocation balances security, growth, and flexibility.
Common Mistakes to Avoid
- Overexposure to Meme Coins: Limit speculative tokens like DOGE or SHIB to a small portion of your portfolio.
- Ignoring Fundamentals: Don’t buy coins just because they’re trending. Use analytics tools to verify quality.
- Lack of Exit Plans: Define profit targets and exit strategies in advance.
Conclusion
A profitable crypto portfolio in 2025 combines diversification, narrative‑driven plays, and AI‑powered insights.
By leveraging Token Metrics for analytics, ratings, and portfolio optimization, you can minimize risk, maximize returns, and stay ahead of market trends.
In crypto, knowledge and data are power — and in 2025, those who combine both will lead the next wave of wealth creation.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.