



How to Store Cryptocurrency Safely in 2025 | Hot vs Cold Wallets
%201.svg)
%201.svg)
%201%20(1).png)
Cryptocurrency offers unmatched freedom, but with that freedom comes responsibility—especially when it comes to how to store cryptocurrency securely. Unlike traditional banking, crypto is self-custodied. If you lose access to your wallet, your funds are gone forever.
This guide explains everything you need to know about storing crypto in 2025, including:
- Why crypto storage matters
- Types of crypto wallets
- Hot wallets vs. cold wallets
- Tips for securing your assets
- How platforms like Token Metrics can help protect your investment
🪙 Why Is Storing Cryptocurrency Important?
When you buy crypto—whether it’s Bitcoin, Ethereum, or a promising moonshot altcoin—you receive private keys that give you access to your funds. Anyone with that key can spend your coins.
That’s why safe storage is critical. Without it, your assets are vulnerable to:
- Hacks and phishing scams
- Lost devices or forgotten passwords
- Exchange collapses or rug pulls
You are your own bank, and your security strategy is your vault.
🔐 What Is a Crypto Wallet?
A crypto wallet is a digital tool that stores your private and public keys. It lets you send, receive, and manage your crypto.
There are two main types:
- Hot wallets – connected to the internet
- Cold wallets – offline and physically secured
Let’s explore both.
🌐 Hot Wallets: Convenience Meets Risk
Hot wallets are always online, making them easy to use for trading, DeFi, or daily transactions.
Types of Hot Wallets:
- Web wallets (e.g., MetaMask, Trust Wallet)
- Mobile apps (e.g., Coinbase Wallet, Phantom)
- Desktop wallets (e.g., Exodus, Electrum)
Pros:
- Quick access to funds
- Easy integration with DApps and exchanges
- Great for beginners and active traders
Cons:
- Higher risk of hacks, malware, and phishing
- Device or browser compromise can expose keys
Best Practices for Hot Wallets:
- Use 2FA (Two-Factor Authentication)
- Never store large amounts
- Double-check URLs to avoid fake websites
- Avoid public Wi-Fi while transacting
🧊 Cold Wallets: Ultimate Security
Cold wallets are offline storage solutions, ideal for long-term investors or large holdings.
Types of Cold Wallets:
- Hardware wallets (e.g., Ledger Nano X, Trezor)
- Paper wallets (QR code + private key printed on paper)
- Air-gapped devices (old smartphones with no internet access)
Pros:
- Immune to online hacks
- Best for HODLing and large sums
- You own full control
Cons:
- Less convenient for daily use
- Loss or damage without backups = permanent loss
Best Practices for Cold Wallets:
- Buy hardware wallets directly from the manufacturer
- Backup your seed phrase on metal plates or offline storage
- Keep backups in secure, separate locations
🔄 Custodial vs. Non-Custodial Wallets
🏦 Custodial Wallets
Managed by exchanges (e.g., Binance, Coinbase). You don’t own the private keys.
Pros:
- Easy to use
- Ideal for beginners
Cons:
- Not your keys, not your crypto
- Vulnerable to hacks or platform failures
🔓 Non-Custodial Wallets
You own the keys. Wallets like MetaMask, Trust Wallet, or hardware devices.
Pros:
- Full control and ownership
- Safer long-term storage
Cons:
- Losing your seed phrase = permanent loss
- Requires more responsibility
Tip: Token Metrics recommends non-custodial wallets for storing long-term holdings and moonshot tokens.
🔐 How Token Metrics Enhances Crypto Security
Token Metrics is an AI-powered crypto research and trading platform trusted by thousands of investors. While it doesn’t store your crypto directly, it helps you manage risk and store assets wisely by:
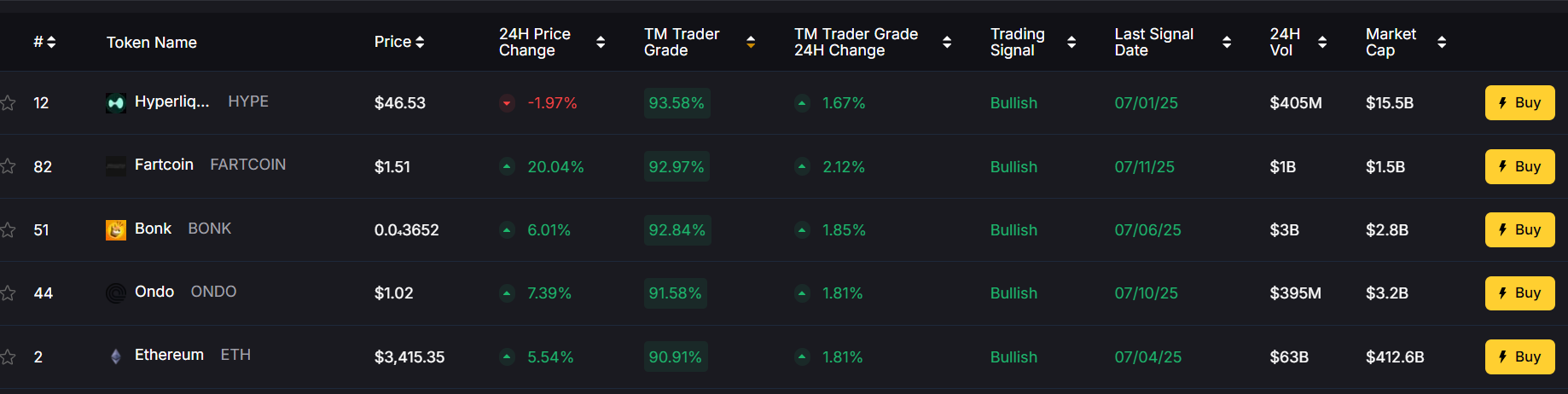
1. Identifying Safe Assets
Token Metrics gives you AI-generated grades for tokens—helping you avoid scams and invest in credible projects worth storing long-term.
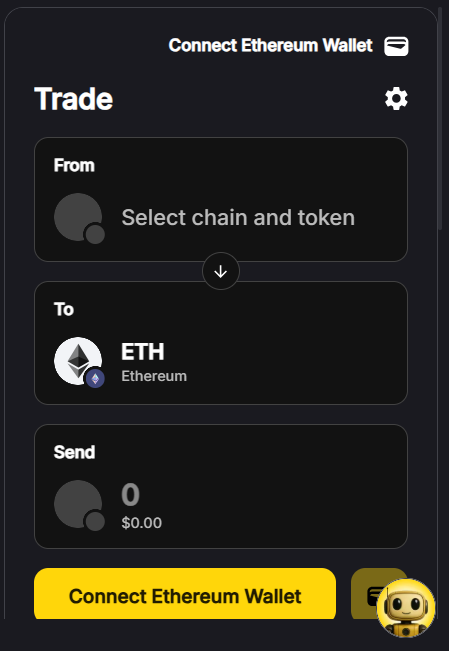
2. Trading Tools with Wallet Integration
You can explore tokens, assess moonshots, and initiate trades directly from your connected Web3 wallet without leaving the platform.
3. Portfolio Tracking with Security
Token Metrics allows you to track wallets and portfolio performance without requiring access to your private keys.
4. Educational Guidance
Through webinars, blog content, and investor resources, Token Metrics educates users on how to safely store their crypto in hot and cold wallets.
🧠 Tips to Keep Your Crypto Safe in 2025
✅ Use Hardware Wallets for Large Amounts
Your long-term Bitcoin, Ethereum, and moonshot tokens should live on a hardware wallet, not on an exchange.
✅ Store Your Seed Phrase Offline
Do NOT keep your recovery phrase in Google Docs or your phone. Use metal seed phrase storage or write it down and lock it in a safe.
✅ Use Multiple Wallets
Diversify storage:
- Hot wallet for daily use
- Cold wallet for savings
- Separate wallet for DeFi
✅ Avoid Suspicious Links and Apps
Phishing is the #1 crypto threat. Double-check URLs, don’t sign unknown transactions, and avoid shady browser extensions.
✅ Monitor Wallet Activity
Use platforms like Token Metrics Alerts or Etherscan to track your wallet and get notified of suspicious activity.
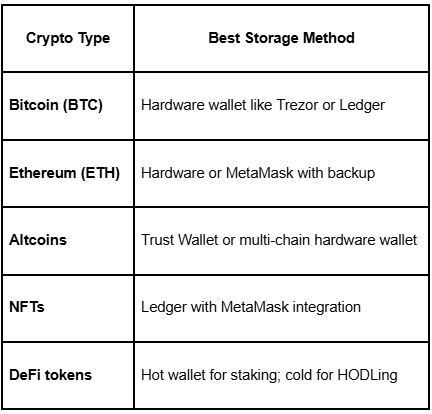
🪙 How to Store Different Types of Crypto
🧭 Final Thoughts
Storing cryptocurrency securely is just as important as choosing the right tokens to invest in. Whether you’re a day trader, long-term investor, or moonshot hunter, knowing when and where to store your crypto is key to protecting your wealth.
In 2025, the best strategy combines:
- Cold wallets for large, long-term holdings
- Hot wallets for convenience and trading
- Non-custodial options to retain full control
- AI tools like Token Metrics to identify trustworthy assets and avoid scams
When you store your crypto properly, you don’t just protect your assets—you gain peace of mind.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.