



How to Trade Cryptocurrency in 2025 – Best Crypto Trading Tools
%201.svg)
%201.svg)

Cryptocurrency trading has rapidly evolved into a global financial movement. With the rise of decentralized finance (DeFi), institutional adoption, and advanced AI tools, trading crypto in 2025 is more accessible—and more profitable—than ever before. But with great opportunity comes great risk, especially if you trade without strategy or insights.
In this highly informative beginner’s guide, we’ll break down how to trade cryptocurrency step by step, the different types of trading strategies, and how platforms like Token Metrics help you make smarter, AI-powered decisions.
🔍 What Is Cryptocurrency Trading?
Cryptocurrency trading involves buying and selling digital assets like Bitcoin (BTC), Ethereum (ETH), Solana (SOL), or thousands of other tokens to profit from price fluctuations. Traders analyze price movements, market trends, and use technical or fundamental data to time their entries and exits.
Unlike traditional stock markets, crypto markets are:
- Open 24/7
- Highly volatile
- Borderless and decentralized
- Powered by blockchain technology
📊 Types of Cryptocurrency Trading
Understanding the different styles of trading can help you pick a strategy that fits your goals and risk tolerance.
1. Day Trading
- Involves multiple trades in a single day
- Aims to profit from short-term price swings
- Requires constant monitoring and fast decision-making
2. Swing Trading
- Positions are held for days or weeks
- Based on momentum and trend reversal patterns
- Suitable for part-time traders
3. Scalping
- Ultra-short-term trading
- Makes small profits on tiny price movements
- High frequency, high risk
4. Position Trading
- Long-term holding based on fundamentals
- Traders buy during dips and hold until a large move
- Also called "trend trading"
5. Automated Trading / AI Trading
- Uses bots or AI models to execute trades
- Ideal for those who want data-driven, emotion-free trading
- Best when paired with platforms like Token Metrics
🧭 How to Trade Cryptocurrency: Step-by-Step
✅ Step 1: Choose a Crypto Exchange or Trading Platform
Select a reputable platform to execute trades. Popular choices in 2025 include:
- Token Metrics (for AI-backed trade insights
- Binance
- Coinbase Pro
- Kraken
- OKX
Each platform offers different tools, liquidity, and trading pairs.
✅ Step 2: Fund Your Account
Deposit funds using:
- Bank transfer
- Debit/credit card
- Stablecoins (USDT, USDC)
- Crypto from your wallet
Token Metrics integrates wallet access, swap functionality, and DeFi bridges so you can trade directly from your dashboard.
✅ Step 3: Analyze the Market
Before you trade, analyze:
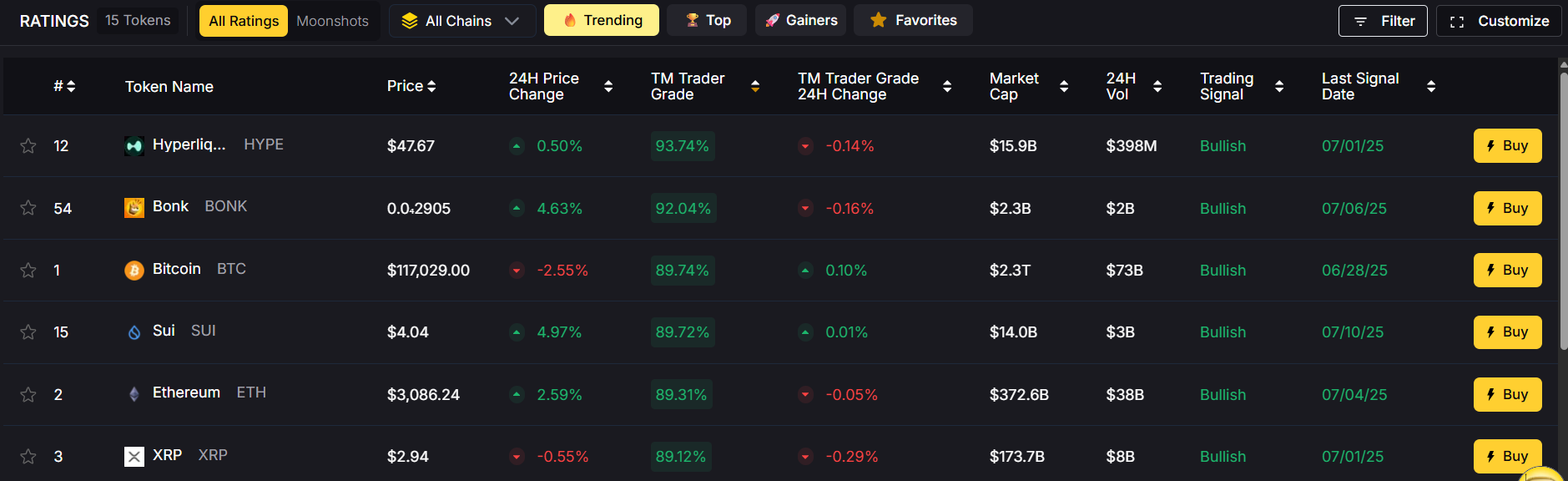
- Price charts (technical analysis)
- Volume and momentum
- News and narratives
- On-chain data and token grades
🔹 Token Metrics AI Grades:
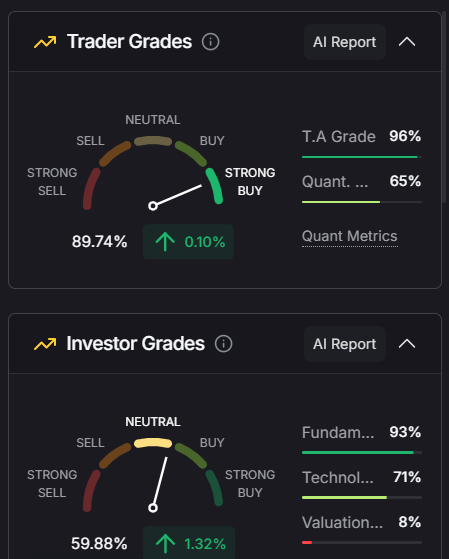
- Trader Grade: Measures short-term trading potential
- Investor Grade: Rates long-term strength
These AI-generated scores help you find the most promising tokens, instantly filtering thousands of coins by risk and opportunity.
✅ Step 4: Place a Trade
Choose your trading pair (e.g., BTC/USDT), then:
- Market order: Buy/sell immediately at current price
- Limit order: Set your own buy/sell price
- Stop-loss: Exit a trade automatically if price drops below a certain level
- Take profit: Lock in gains once a target is hit
Token Metrics provides real-time buy/sell alerts powered by AI signals, helping you avoid emotional trading.
✅ Step 5: Monitor and Manage Your Trades
Check the performance of your portfolio regularly. Use tools like:
- Live charts
- Alerts for price and grade changes
- Token Fundamentals: Developer activity, community growth, holders
Token Metrics simplifies this with its Token Details Page, offering everything from real-time ROI to whale tracking—all in one view.
✅ Step 6: Exit the Trade & Secure Profits
Sell your position when:
- You hit your price target
- A bearish trend begins
- Token Metrics issues a bearish signal
- Your risk tolerance is breached
You can transfer funds to a cold wallet or reinvest into new high-potential tokens (like those listed in the Moonshots tab on Token Metrics).
🤖 How Token Metrics Makes Crypto Trading Smarter
Trading is hard. But with Token Metrics AI tools, you can trade based on data, not emotions.
🔹 AI Price Predictions
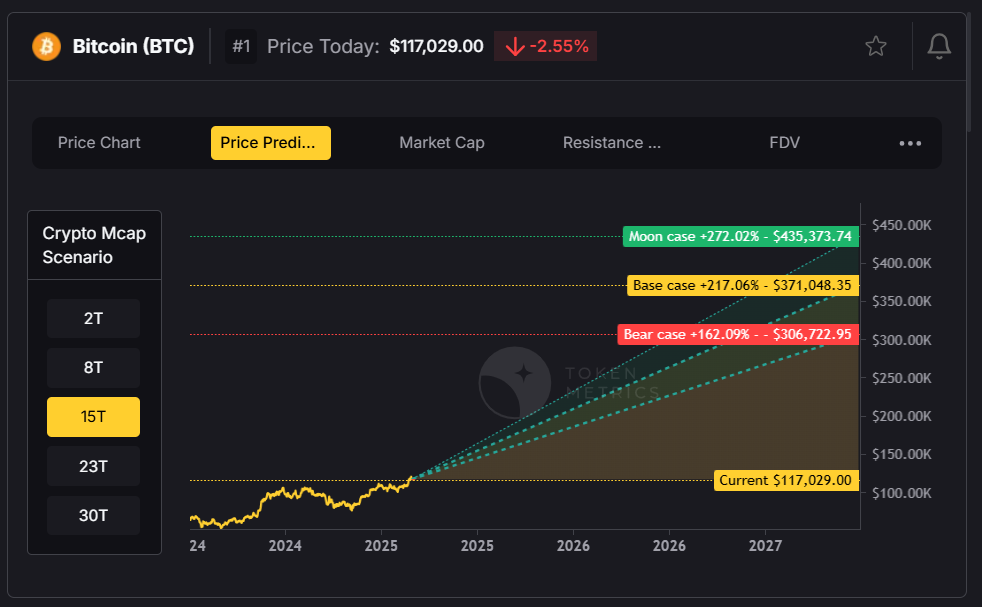
- Forecasted prices for thousands of tokens using machine learning
- Built on 80+ on-chain, technical, sentiment, and fundamental metrics
🔹 Moonshot Finder
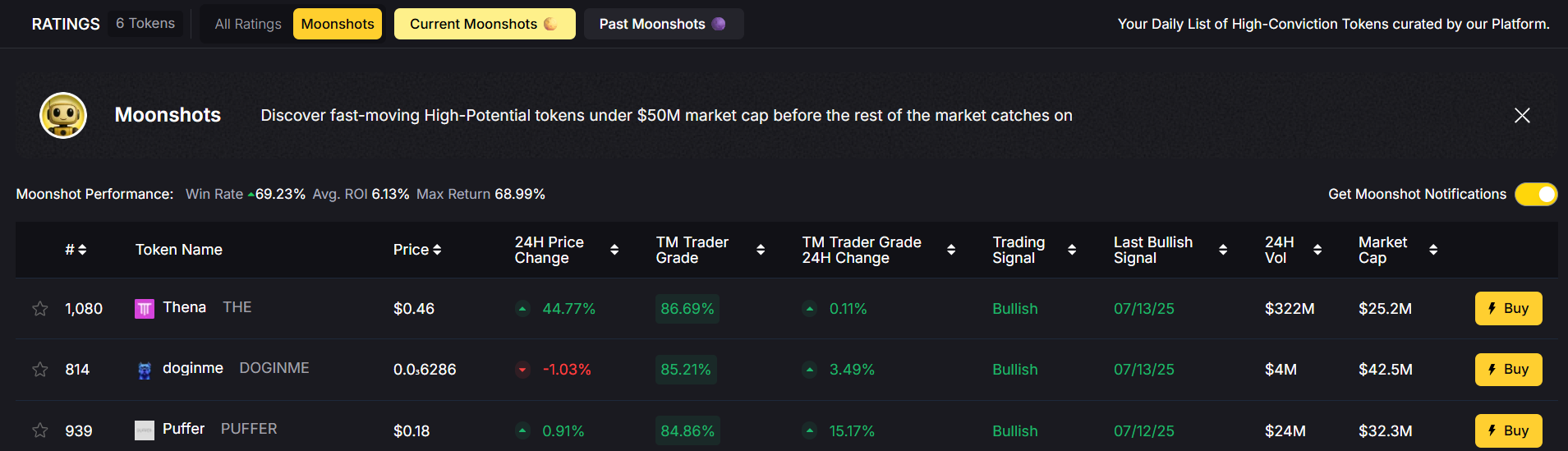
- Discover early-stage altcoins with 10x–100x potential
- See live ROI, entry date, trader grade changes, and volume shifts
🔹 Trade Alerts
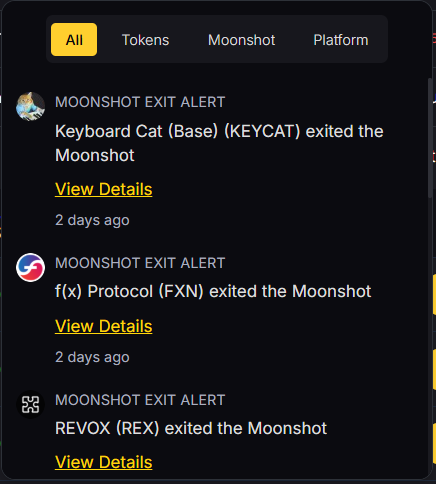
- Get notified when:
- Tokens reach your target price
- Bullish or bearish signals are triggered
- AI grades update in real time
- Tokens reach your target price
Alerts are sent via:
- Telegram
- Discord
- Email
- SMS
🔹 Real-Time Swap Widget
Trade directly on Token Metrics with one click. No need to leave the platform.
💡 Pro Tips for Successful Crypto Trading in 2025
- Use AI Tools: Let platforms like Token Metrics do the heavy lifting.
- Avoid FOMO: Just because a token is trending doesn’t mean it’s worth buying.
- Start Small: Don’t risk your entire capital in one trade.
- Keep Learning: Read market news, watch on-chain activity, and follow macro trends.
- Stay Safe: Use 2FA, trusted exchanges, and cold wallets.
📈 Top Crypto Trading Trends in 2025
- AI-Driven Signal Trading
- Copy Trading and Social Trading
- Narrative-Based Investing (e.g., AI tokens, DePIN, L2s)
- Real-World Asset (RWA) Tokenization
- ETF-driven Institutional Trading
Platforms like Token Metrics sit at the center of these trends, offering users powerful AI infrastructure and deep crypto analytics.
✅ Final Thoughts
Trading cryptocurrency in 2025 is more rewarding—and more competitive—than ever. To succeed, you need:
- A solid understanding of market dynamics
- Reliable strategies and discipline
- Smart tools that give you an edge
That’s where Token Metrics comes in.
Whether you’re day trading, swing trading, or investing long-term, Token Metrics gives you:
- AI-driven token rankings
- Real-time price alerts
- Moonshot altcoin discoveries
- Easy, integrated trading tools
Don’t just trade crypto—trade with intelligence.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.