



How to Turn $10,000 into Life-Changing Crypto Profits: Expert Trading Strategies for 2025
%201.svg)
%201.svg)

The cryptocurrency market has evolved dramatically, transforming from a speculative playground into a sophisticated ecosystem requiring strategic thinking and data-driven approaches. For investors looking to maximize returns with a $10,000 budget, understanding the right methodology can mean the difference between modest gains and life-changing wealth.
The Foundation: Market Timing is Everything
Successful crypto trading begins with understanding market cycles and timing. The most critical tool in any trader's arsenal is the Token Metrics market indicator – a comprehensive gauge that tells you when to be aggressive versus when to exercise caution.
When the Token Metrics market indicator shows "strong buy" with gaining momentum, it's time to operate at full throttle. Conversely, during "sell" or "strong sell" periods, conservative positioning protects capital for future opportunities. This simple principle has helped countless investors avoid the devastating losses that plague emotional traders.
"Everything starts with the market indicator. This kind of tells you how aggressive to be with your trades," explains Token Matrix's Ian Belina, emphasizing that successful trading requires adapting intensity to market conditions rather than maintaining constant aggression.
The Secret Weapon: Bitcoin vs Altcoin Season Indicator
Perhaps the most overlooked yet powerful tool for profit maximization is the Bitcoin vs Altcoin Season indicator. This metric reveals when over 60% of market returns shift to altcoins – a historically reliable signal for taking profits.
Historical data shows this indicator preceded major market tops with remarkable accuracy. In December 2024, when altcoins captured nearly 60% of returns, the market peaked within days. Similarly, the January peak occurred precisely when this metric flashed warning signs.
Smart traders use this as a systematic profit-taking trigger. When altcoin returns exceed 60% while the overall market shows strong bullish signals, it's time to take 25-50% off the table, regardless of individual token performance.
The Trending Tokens Strategy: Following Smart Money
Rather than scouring thousands of cryptocurrencies, successful traders focus on a curated list of trending tokens with high trader grades (80%+). This approach filters market noise and identifies where institutional money and sophisticated algorithms are placing bets.
The trending tokens methodology works because it combines:
- Real-time market sentiment analysis
- Technical momentum indicators
- Fundamental catalyst identification
- Liquidity requirements (minimum $1M daily volume)
Current examples demonstrating this strategy's power include:
Chainlink (LINK): The Enterprise Play
Chainlink has broken through multi-year resistance at $22-$23, positioning for a potential run toward $37. The enterprise Layer 1 narrative drives this momentum as Wall Street firms launching blockchain infrastructure require robust oracle services. With improved tokenomics and a revenue-tied buyback program, Chainlink represents a "blue chip" crypto with institutional staying power.
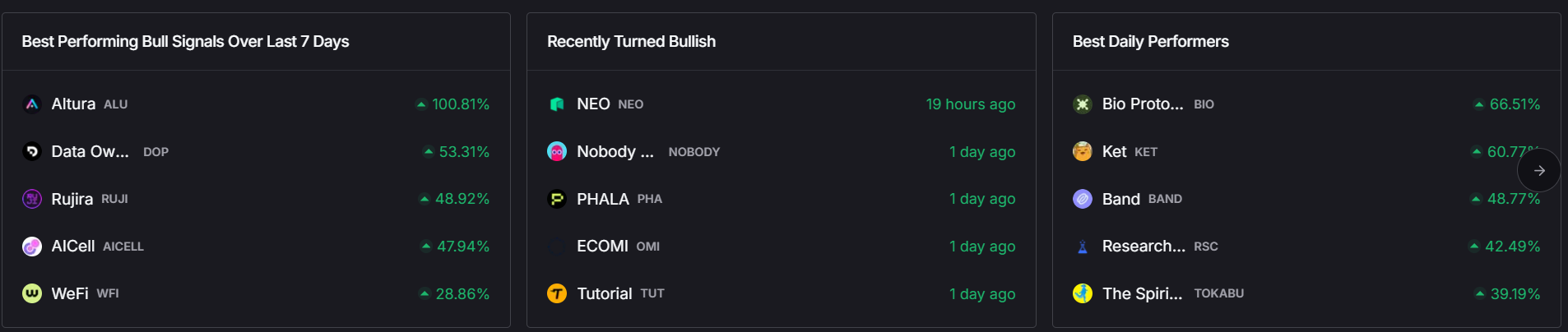
Bio Protocol: The Treasury Play
Despite already delivering 100% returns in 30 days, Bio Protocol continues showing strength due to backing from Binance Labs and recent $1 million investment from notable crypto figure and Bitmex founder Arthur Hayes. The DeSci (Decentralized Science) narrative provides fundamental support for continued growth.
Pendle: The Yield Trading Revolution
Trading at what analysts consider deeply undervalued levels, Pendle operates with $10 billion in Total Value Locked against just a $1.4 billion market cap. As institutions seek yield optimization tools, Pendle's unique position in yield tokenization and trading presents significant upside potential.
Advanced Strategies: Leveraging Market Narratives
Successful crypto investors understand that markets are driven by narratives – compelling stories that capture investor imagination and drive capital flows. Current dominant narratives include:
The Base Ecosystem Explosion
Coinbase's gradual rollout of DEX trading functionality (currently available to just 1% of users) creates a massive catalyst for Base ecosystem tokens. Aerodrome, serving as the primary DEX aggregator, and Zora, providing social Web3 functionality, both benefit from this expanding user base.
The AI Agent Renaissance
Following the success of tokens like AIXBT (which delivered 17x returns during peak AI agent season), smart traders monitor for the next wave of AI-focused projects. However, timing remains crucial – entering established trends often leads to disappointment.
The Regulatory Clarity Premium
With SEC leadership changes bringing crypto-friendly policies, tokens positioned to benefit from clearer regulations command premium valuations. Stablecoin protocols and institutional DeFi platforms lead this category.
Risk Management: The 25-50-25 Rule
Professional crypto traders never go "all-in" on any single opportunity. The optimal approach involves:
- 25% allocation: High-conviction, established tokens (Bitcoin, Ethereum, Chainlink)
- 50% allocation: Medium-risk narrative plays with strong fundamentals
- 25% allocation: High-risk "moonshot" opportunities under $50M market cap
This diversification ensures portfolio survival during inevitable corrections while maintaining upside exposure to breakout performances.
The $10k Blueprint: Step-by-Step Implementation Via Token Metrics
Phase 1: Market Assessment (Days 1-7)
- Monitor Token Metrics Market Indicator for entry timing
- Identify current trending narratives
- Build watchlist of 5-10 high-grade tokens
Phase 2: Initial Deployment (Days 8-30)
- Deploy 60% capital during strong buy signals
- Focus on tokens with 80%+ trader grades
- Set up automated alerts for grade changes
Phase 3: Active Management (Ongoing)
- Rebalance weekly based on momentum changes
- Take profits when Bitcoin vs Altcoin indicator exceeds 60%
- Reinvest profits during market corrections
The Extended Cycle Opportunity
Recent analysis suggests the current crypto cycle may extend into 2026, following historical patterns where each cycle lasts approximately 25% longer than its predecessor. This extended timeline provides multiple opportunities for strategic repositioning and compound growth.
With total crypto market cap at $4 trillion (compared to the previous cycle peak of $3 trillion), significant upside remains. Investors positioning correctly for this extended cycle could see their $10,000 investments grow substantially.
Common Pitfalls to Avoid
Emotional Trading: Following social media hype instead of data-driven signals leads to buying tops and selling bottoms.
Overconcentration: Putting too much capital in a single token, regardless of conviction level.
Ignoring Market Cycles: Failing to adjust strategy based on overall market conditions.
Chasing Past Performance: Buying tokens after they've already completed major moves.
Technology Integration: Automating Success
The future of crypto trading lies in automation. Token Matrix and similar platforms are developing automated indices that can:
- Rebalance portfolios based on AI-driven signals
- Exit positions during bearish market shifts
- Reinvest during optimal buying opportunities
These tools democratize access to institutional-grade trading strategies, potentially transforming modest investments into significant wealth over time.
Conclusion: Discipline Over Speculation
Turning $10,000 into life-changing wealth in crypto requires discipline, patience, and systematic execution. By focusing on market timing, following trending narratives, and maintaining strict risk management, investors position themselves for outsized returns while protecting against catastrophic losses.
The key lies not in finding the next 100x token, but in consistently identifying and properly timing 2-5x opportunities across multiple market cycles. With the right approach, compound growth and strategic reinvestment can transform modest beginnings into substantial wealth.
Remember: in crypto, survival is the first priority, profit is the second, and extraordinary gains come to those who master both.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.