



How to Use x402 with Token Metrics: Composer Walkthrough + Copy-Paste Axios/HTTPX Clients
%201.svg)
%201.svg)


What You Will Learn — Two-Paragraph Opener
This tutorial shows you how to use x402 with Token Metrics in two ways. First, we will walk through x402 Composer, where you can run Token Metrics agents, ask questions, and see pay-per-request tool calls stream into a live Feed with zero code. Second, we will give you copy-paste Axios and HTTPX clients that handle the full x402 flow (402 challenge, wallet payment, automatic retry) so you can integrate Token Metrics into your own apps.
Whether you are exploring x402 for the first time or building production agent workflows, this guide has you covered. By the end, you will understand how x402 payments work under the hood and have working code you can ship today. Let's start with the no-code option in Composer.
Start using Token Metrics X402 integration here. https://www.x402scan.com/server/244415a1-d172-4867-ac30-6af563fd4d25
Part 1: Try x402 + Token Metrics in Composer (No Code Required)
x402 Composer is a playground for AI agents that pay per tool call. You can test Token Metrics endpoints, see live payment settlements, and understand the x402 flow before writing any code.
What Is Composer?
Composer is x402scan's hosted environment for building and using AI agents that pay for external resources via x402. It provides a chat interface, an agent directory, and a real-time Feed showing every tool call and payment across the ecosystem. Token Metrics endpoints are available as tools that agents can call on demand.
Explore Composer: https://x402scan.com/composer
Step-by-Step Walkthrough
Follow these steps to run a Token Metrics query and watch the payment happen in real time.
- Open the Composer agents directory: Go to https://x402scan.com/composer/agents and browse available agents. Look for agents tagged with "Token Metrics" or "crypto analytics." Or check our our integration here. https://www.x402scan.com/server/244415a1-d172-4867-ac30-6af563fd4d25
- Select an agent: Click into an agent that uses Token Metrics endpoints (for example, a trading signals agent or market intelligence agent). You will see the agent's description, configured tools, and recent activity.
- Click "Use Agent": This opens a chat interface where you can run prompts against the agent's configured tools.
- Run a query: Type a question that requires calling a Token Metrics endpoint, for example "Give me the latest TM Grade for Ethereum" or "What are the top 5 moonshot tokens right now?" and hit send.
- Watch the Feed: As the agent processes your request, it will call the relevant Token Metrics endpoint. Open the Composer Feed (https://x402scan.com/composer/feed) in a new tab to see the tool call appear in real time with payment details (USDC or TMAI amount, timestamp, status).
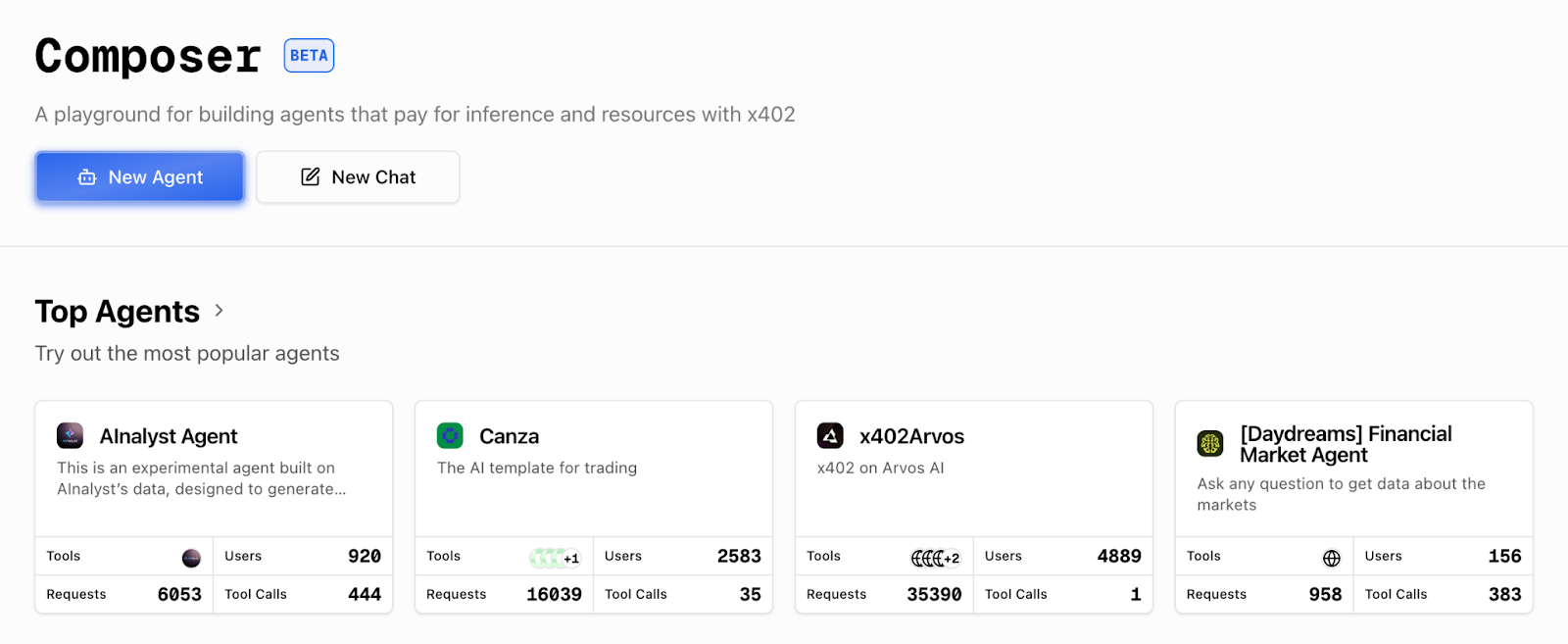
Composer agents directory: Composer Agents page: Each agent shows tool stack, messages, and recent activity.
Individual agent page: Agent detail page: View tools, description, and click "Use Agent" to start.
[INSERT SCREENSHOT: Chat interface]
Chat interface: Chat UI: Ask a question like "What are the top trading signals for BTC today?"
[INSERT SCREENSHOT: Composer Feed]
Composer Feed: Live Feed: Each tool call shows the endpoint, payment token, amount, and settlement status.
That is the x402 flow in action. The agent's wallet paid for the API call automatically, the server verified payment, and the data came back. No API keys, no monthly bills, just pay-per-use access.
Key Observations from Composer
- Tool calls show the exact endpoint called (like /v2/tm-grade or /v2/moonshot-tokens)
- Payments display in USDC or TMAI with the per-call cost
- The Feed updates in real time, you can see other agents making calls across the ecosystem
- You can trace each call back to the agent and message that triggered it
- This is how agentic commerce works: agents autonomously pay for resources as needed
Part 2: Build Your Own x402 Client (Axios + HTTPX)
Now that you have seen x402 in action, let's build your own client that can call Token Metrics endpoints with automatic payment handling.
How x402 Works (Quick Refresher)
When you make a request with the x-coinbase-402 header, the Token Metrics API returns a 402 Payment Required response with payment instructions (recipient address, amount, chain). Your x402 client reads this challenge, signs a payment transaction with your wallet, submits it to the blockchain, and then retries the original request with proof of payment. The server verifies the settlement and returns the data. The x402-axios and x402 Python libraries handle this flow automatically.
Prerequisites
- A wallet with a private key (use a testnet wallet for development on Base Sepolia, or a mainnet wallet for production on Base)
- USDC or TMAI in your wallet (testnet USDC for testing, mainnet tokens for production)
- Node.js 18+ and npm (for Axios example) or Python 3.9+ (for HTTPX example)
- Basic familiarity with async/await patterns
Recommended Token Metrics Endpoints for x402
These endpoints are commonly used by agents and developers building on x402. All are pay-per-call with transparent pricing.
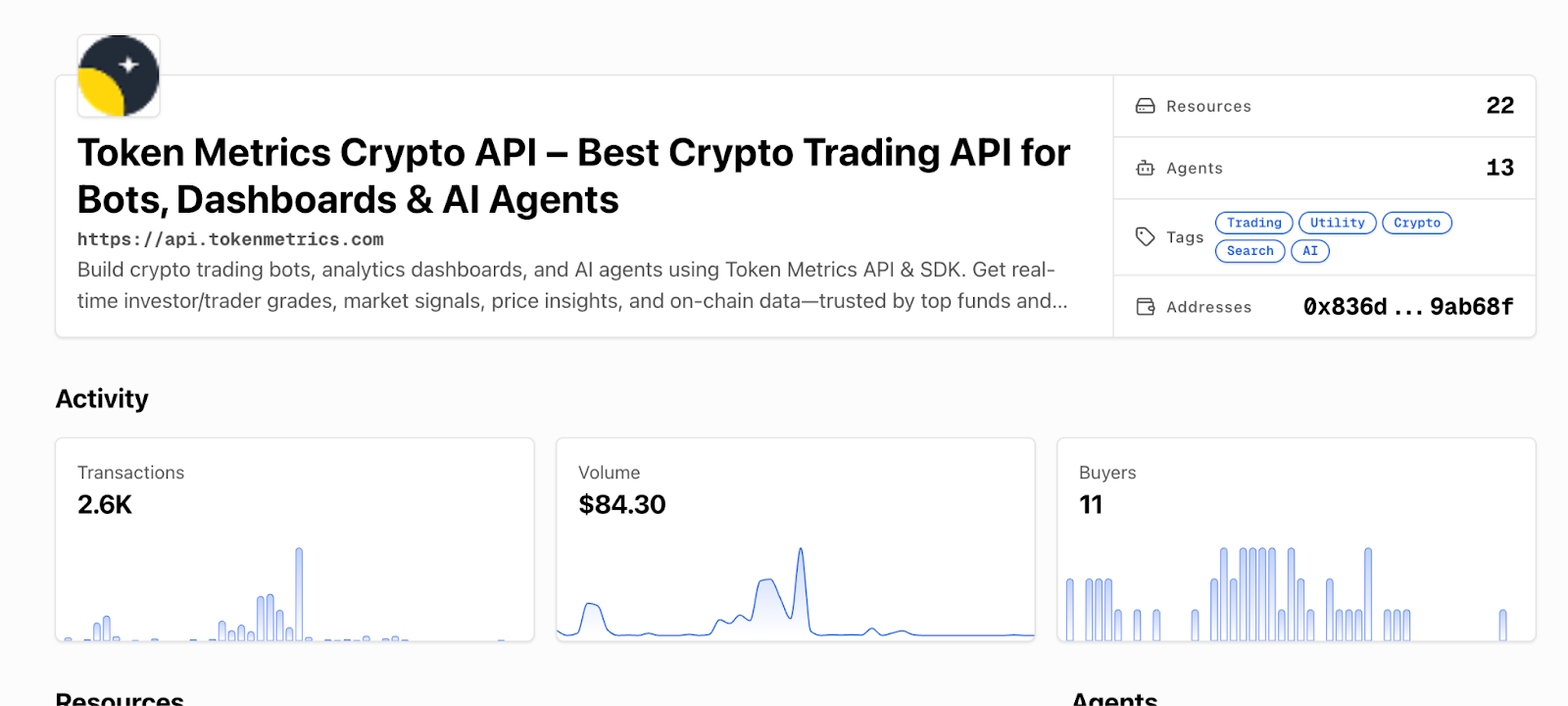
Full endpoint list and docs: https://developers.tokenmetrics.com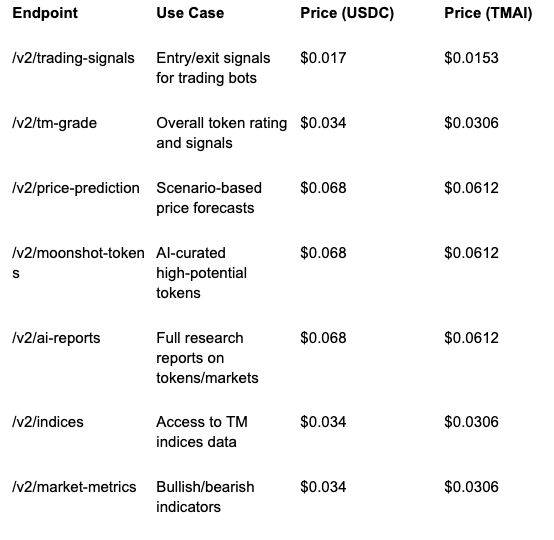
Common Errors and How to Fix Them
Here are the most common issues developers encounter with x402 and their solutions.
Error: Payment Failed (402 Still Returned After Retry)
This usually means your wallet does not have enough USDC or TMAI to cover the call, or the payment transaction failed on-chain.
- Check your wallet balance on Base (use a block explorer or your wallet app)
- Make sure you are on the correct network (Base mainnet for production, Base Sepolia for testnet)
- Verify your private key has permission to spend the token (no allowance issues for most x402 flows, but check if using a smart contract wallet)
- Try a smaller request or switch to a cheaper endpoint to test
Error: Network Timeout
x402 requests take longer than standard API calls because they include a payment transaction. If you see timeouts, increase your client timeout.
- Set timeout to at least 30 seconds (30000ms in Axios, 30.0 in HTTPX)
- Check your RPC endpoint is responsive (viem/eth-account uses public RPCs by default, which can be slow)
- Consider using a dedicated RPC provider (Alchemy, Infura, QuickNode) for faster settlement
Error: 429 Rate Limit Exceeded
Even with pay-per-call, Token Metrics enforces rate limits to prevent abuse. If you hit a 429, back off and retry.
- Implement exponential backoff (wait 1s, 2s, 4s, etc. between retries)
- Spread requests over time instead of bursting
- For high-volume use cases, contact Token Metrics to discuss rate limit increases
Error: Invalid Header or Missing x-coinbase-402
If you forget the x-coinbase-402: true header, the server will treat your request as a standard API call and may return a 401 Unauthorized if no API key is present.
- Always include x-coinbase-402: true in headers for x402 requests
- Do not send x-api-key when using x402 (the header is mutually exclusive)
- Double-check header spelling (it is x-coinbase-402, not x-402 or x-coinbase-payment)
Production Tips
- Use environment variables for private keys, never hardcode them
- Set reasonable max_payment limits to avoid overspending (especially with TMAI)
- Log payment transactions for accounting and debugging
- Monitor your wallet balance and set up alerts for low funds
- Test thoroughly on Base Sepolia testnet before going to mainnet
- Use TMAI for production to get the 10% discount on every call
- Cache responses when possible to reduce redundant paid calls
- Implement retry logic with exponential backoff for transient errors
Why This Matters for Agents
Traditional APIs force agents to carry API keys, which creates security risks and requires human intervention for key rotation and billing. With x402, agents can pay for themselves using wallet funds, making them truly autonomous. This unlocks agentic commerce where AI systems compose services on the fly, paying only for what they need without upfront subscriptions or complex auth flows.
For Token Metrics specifically, x402 means agents can pull real-time crypto intelligence (signals, grades, predictions, research) as part of their decision loops. They can chain our endpoints with other x402-enabled tools like Heurist Mesh (on-chain data), Tavily (web search), and Firecrawl (content extraction) to build sophisticated, multi-source analysis workflows. It is HTTP-native payments meeting real-world agent use cases.
FAQs
Can I use the same wallet for multiple agents?
Yes. Each agent (or client instance) can use the same wallet, but be aware of nonce management if making concurrent requests. The x402 libraries handle this automatically.
Do I need to approve token spending before using x402?
No. The x402 payment flow uses direct transfers, not approvals. Your wallet just needs sufficient balance.
Can I see my payment history?
Yes. Check x402scan (https://x402scan.com/composer/feed) for a live feed of all x402 transactions, or view your wallet's transaction history on a Base block explorer.
What if I want to use a different payment token?
Currently x402 with Token Metrics supports USDC and TMAI on Base. To request support for additional tokens, contact Token Metrics.
How do I switch from testnet to mainnet?
Change your viem chain from baseSepolia to base (in Node.js) or update your RPC URL (in Python). Make sure your wallet has mainnet USDC or TMAI.
Can I use x402 in browser-based apps?
Yes, but you will need a browser wallet extension (like MetaMask or Coinbase Wallet) and a frontend-compatible x402 library. The current x402-axios and x402-python libraries are designed for server-side or Node.js environments.
Next Steps
- Deploy your x402 client: Take the code examples above and integrate them into your app or agent
- Explore Composer: https://x402scan.com/composer
- Read the x402 docs: https://docs.cdp.coinbase.com/x402/docs/quickstart-buyers
- Check Token Metrics API docs: https://developers.tokenmetrics.com
- Join the community: Follow @tokenmetrics and @x402scan on X (Twitter) for updates and examples
Disclosure
Educational and informational purposes only. x402 involves crypto payments on public blockchains. Understand the risks, secure your private keys, and test thoroughly before production use. Token Metrics does not provide financial advice.
Quick Links
- Composer: https://x402scan.com/composer
- Composer Agents: https://x402scan.com/composer/agents
- Composer Feed: https://x402scan.com/composer/feed
- x402 Quickstart: https://docs.cdp.coinbase.com/x402/docs/quickstart-buyers
- Token Metrics API: https://developers.tokenmetrics.com
- x402 Axios (npm): https://www.npmjs.com/package/x402-axios
- x402 Python (GitHub): https://github.com/coinbase/x402-python
About Token Metrics
Token Metrics provides powerful crypto analytics, signals, and AI-driven tools to help you make smarter trading and investment decisions. Start exploring Token Metrics ratings and APIs today for data-driven success.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.