



Introducing the Customizable Ratings Page for Best Crypto Opportunities
%201.svg)
%201.svg)


Are you looking for a way to personalize your crypto investing experience like never before? Do you want to have access to a wealth of data and insights that can help you make smarter and faster investment decisions? If so, you’re going to love our latest innovation: the Customizable Ratings Page.
The Customizable Ratings Page is a powerful tool that allows you to tailor your Token Metrics dashboard according to your preferences and goals. You can choose from an expanded selection of columns and metrics, apply advanced filters, and save your preferred layout for future use. This way, you can have a streamlined and efficient interface that shows you exactly what you need to know about various cryptocurrencies.
In this blog post, we’ll show you how the Customizable Ratings Page works and why it’s a game-changer for crypto investors.
How the Customizable Ratings Page Works
The Customizable Ratings Page is designed to give you more control and flexibility over your crypto investing journey. Here’s how it works:
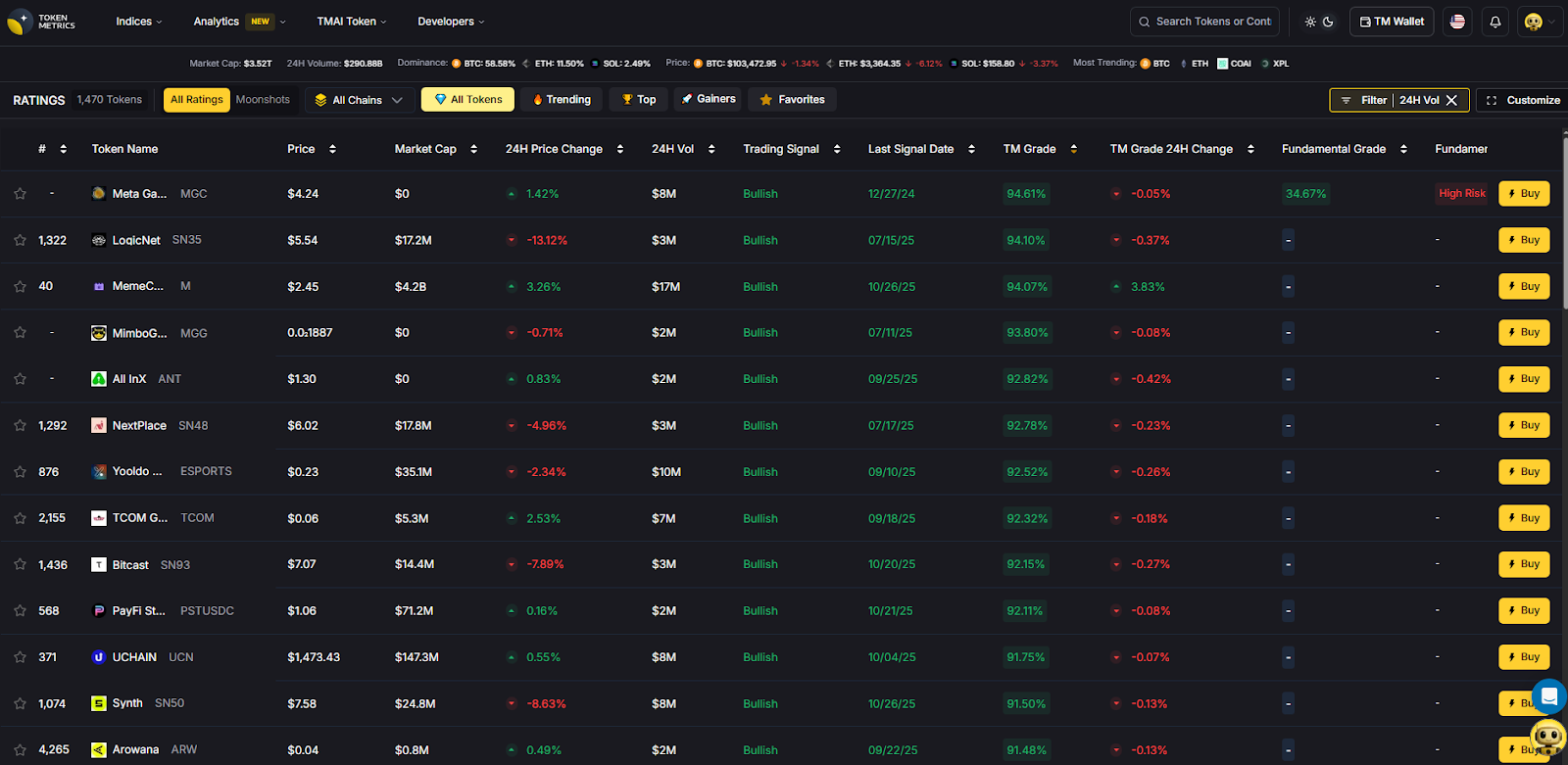
- First, log in to your Token Metrics account and go to the ratings page. You’ll see our default columns that show you our ratings, predictions, fundamentals, technology, technical analysis, correlation rank, volatility rank, market cap rank, price change rank, volume change rank, liquidity rank.
- Next, click on the “Customize” button at the top right corner of the page. You’ll see a list of additional columns that you can add or remove from your dashboard. These include: market cap dominance rank (how dominant is a coin in terms of market cap), price prediction accuracy (how accurate are our price predictions), ROI since inception (how much return has a coin generated since its launch), ROI 30 days (how much return has a coin generated in the past 30 days), ROI 90 days (how much return has a coin generated in the past 90 days), ROI 365 days (how much return has a coin generated in the past year), risk-adjusted returns (how much return has a coin generated relative to its risk), Sharpe ratio (a measure of risk-adjusted returns), Sortino ratio (a measure of downside risk-adjusted returns), max drawdown (the maximum loss from peak to trough), annualized volatility (the standard deviation of annual returns), skewness (a measure of asymmetry of returns distribution), kurtosis (a measure of tail risk of returns distribution).
- Then, drag and drop the columns to rearrange them according to your preference. You can also resize them by dragging their edges.
- Finally, click on “Save” to save your customized layout. You can also click on “Reset” to go back to the default layout.
You can also use advanced filters to narrow down your search for specific coins or criteria. For example:
- If you want to see only coins with high ratings (>80%), high fundamentals (>80%), high technology (>80%), low correlation (<0.5) with Bitcoin or Ethereum
- If you want to see only coins with positive price predictions (>0%), positive price change (>0%), positive volume change (>0%), high liquidity (>80%)
- If you want to see only coins with high ROI since inception (>1000%), high Sharpe ratio (>2), low max drawdown (<50%), low annualized volatility (<50%)
You can apply these filters by clicking on the filter icon next to each column header and entering your desired values or ranges.
The Game-Changer for Crypto Investors?
The Customizable Ratings Page is more than just a cosmetic upgrade. It’s a game-changer for crypto investors because it offers several benefits:
- It helps you focus on what matters most: With so many data points and indicators available in crypto investing, it can be overwhelming and confusing to keep track of everything.
The Customizable Ratings Page lets you focus on what matters most to you and your strategy, whether it’s fundamentals, technology, technical analysis, price predictions, risk-adjusted returns, or anything else. You can eliminate unnecessary noise and clutter and have a clear view of the information that drives your decisions. - It helps you discover new opportunities: With over 6000 cryptocurrencies in existence, it can be hard to find new opportunities that match your criteria and goals.
The Customizable Ratings Page lets you discover new opportunities by applying advanced filters that sort through our vast database of coins. You can find hidden gems that meet your standards and expectations, whether you’re looking for high growth potential, low risk, or niche markets. - It helps you save time and effort: Crypto investing can be time-consuming and exhausting if you have to manually research and analyze every coin that catches your eye.
The Customizable Ratings Page helps you save time and effort by providing you with a quick and easy way to compare and contrast different coins based on various metrics. You can see at a glance how each coin stacks up against others in terms of ratings, predictions, fundamentals, technology, technical analysis, risk-adjusted returns, and more.
Here's a great video to give you a better understanding of the Customizable Ratings Page:
With an expanded selection of columns and metrics, advanced filters, and saved preferences, we’re putting users in the driver’s seat when it comes to analyzing and selecting the best investment opportunities.
At Token Metrics, we’re committed to providing the best tools and resources for our customers to succeed in the ever-evolving world of cryptocurrencies. The Customizable Ratings Page is just another step in our mission to help you make well-informed investment decisions, tailored to your unique goals and strategies.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)













.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.