



Introducing the New Moonshots API Endpoint: Access High‑Potential Tokens Programmatically
%201.svg)
%201.svg)


The crypto market moves fast, and staying ahead requires more than just watching charts — it takes actionable data, delivered in real‑time. That’s why we’re excited to announce a major upgrade for developers, traders, and analysts: the Moonshots feature is now live as a Token Metrics API endpoint.
This new endpoint brings the same powerful insights from our Premium Moonshots dashboard directly into your apps, dashboards, and trading systems — programmatically. Whether you’re building a crypto trading bot, creating dynamic watchlists, or backtesting new strategies, the Moonshots API gives you everything you need to make smarter, faster decisions.
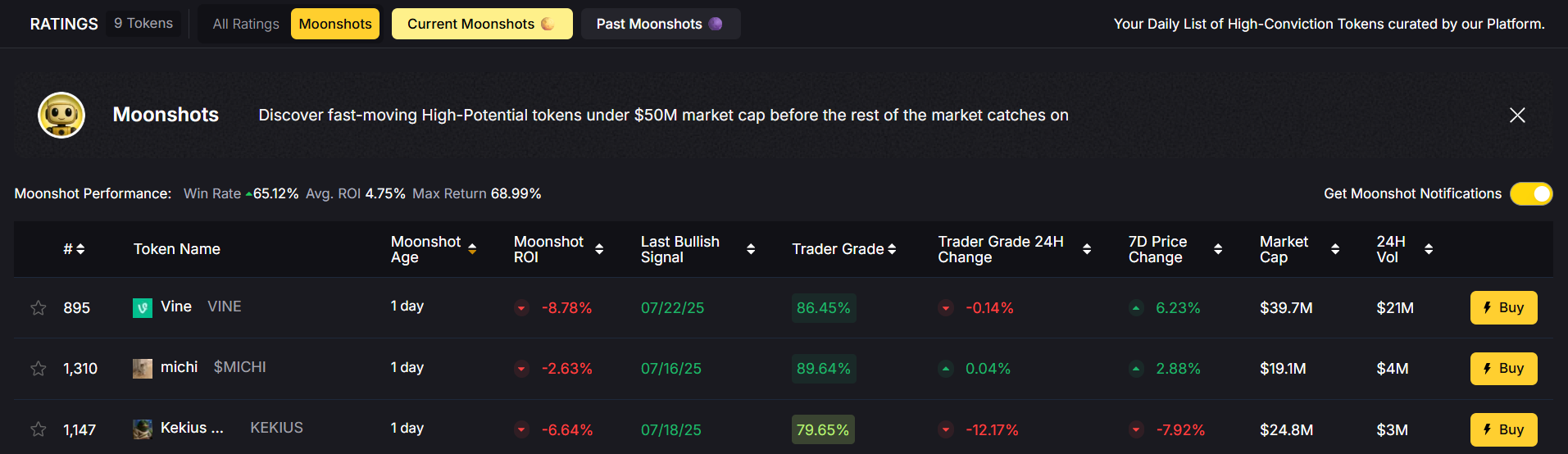
What Are Moonshots?
In crypto, “moonshots” are low‑cap tokens with high upside potential — the kind of high‑risk, high‑reward plays that can deliver outsized returns when identified early. At Token Metrics, our Moonshots aren’t just random picks.
They are:
- Hand‑picked by AI: Our proprietary algorithms scan thousands of tokens daily.
- Backtested for performance: Only tokens that meet strict historical success criteria make the cut.
- Continuously updated: Live insights reflect evolving market conditions in real time.
Since launch, Moonshots have surfaced 43 tokens with a 65 % win rate across trades. The max single‑token return so far? 68 % — and counting.
For developers, this is no longer just data you view in our dashboard. It’s now available via API, ready to integrate into your workflows.
Why Use the Token Metrics Moonshots API?
1. Programmatic Access to High‑Potential Trades
Get direct access to live Moonshot signals without needing to log into the platform. Perfect for apps, analytics dashboards, or automated trading systems.
2. Build Smarter Watchlists
Automatically populate your app or dashboard with AI‑curated, high‑potential tokens.
3. Trigger Bots in Real Time
Integrate the Moonshots feed into your trading bots so they can act instantly when a new token surfaces.
What’s in the API Response?
When you call the /v2/moonshot-tokens endpoint, you’ll get:
- Token name & ticker – For easy identification.
- Return on Investment (ROI) – Performance since the signal went live.
- Trader Grade – Token Metrics’ proprietary grade indicating trade potential.
- Market Cap – So you can quickly gauge token size and liquidity.
- Signal Date – When the Moonshot was flagged.
Want to see how these signals have performed over time? Use /v2/moonshots-tokens with type=past param for detailed past performance data.
Who Is This For?
The Moonshots API is designed for:
- Developers: Integrate AI‑curated trading intelligence into your products.
- Quant Traders: Automate your strategies with real‑time Moonshot signals.
- Portfolio Managers: Discover high‑potential small‑cap tokens before the crowd.
How to Get Started
- Upgrade to the Advanced Plan
Moonshots is part of our premium trading‑signal suite, available with the Advanced Plan. - Get Your API Key
Once upgraded, grab your API key from the Token Metrics API dashboard. - Call the Endpoint
- Live Moonshots: GET /v2/moonshot-tokens
- Past Moonshots: GET /v2/moonshot-tokens with type=past
- Live Moonshots: GET /v2/moonshot-tokens
- Build and Deploy
Use the data to feed your dashboards, bots, or applications.
Your code could be live in minutes.
Example Use Cases
1. Auto‑Populate Watchlists
Give your users instant access to a curated list of high‑potential tokens. No manual updates — just live, programmatic signals from the API.
2. Trading Bot Triggers
Connect Moonshots to your algorithmic trading strategies. When a new Moonshot signal appears, your bot can take action immediately.
Why Moonshots API Is a Game‑Changer
The Moonshots API takes one of our most popular Premium features and makes it actionable for builders and advanced traders. No more copy‑pasting token names from dashboards. No more manually tracking new signals. With programmatic access, you can:
- React faster to new opportunities.
- Automate trading or alert systems.
- Enhance your products with cutting‑edge AI‑curated token lists.
This is the same data powering our Premium dashboards — now unlocked for programmatic use.
Performance at a Glance
Here’s what you can expect from Moonshots based on recent data:
- Tokens surfaced: 43
- Win rate: 65 %
- Max single‑token return: 68 %
- Average holding period: Short‑ to mid‑term trades (active monitoring recommended)
The Bottom Line
The new Moonshots API endpoint lets you turn insights into action. Whether you’re an individual trader looking to build a personal watchlist, a quant team running algorithmic strategies, or a product developer building the next great crypto platform, the Moonshots API provides a direct pipeline to AI‑curated, backtested token picks with a proven track record.
Don’t just watch the next big move — catch it before it becomes hindsight.
How to Access the Moonshots API
- Upgrade to Advanced Plan to unlock trading‑signal endpoints.
- Get your API key from the Token Metrics dashboard.
- Start calling /v2/moonshot-tokens today.
Have questions? Our team is available on Telegram (@tokenmetricsapi) to help you get up and running.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.