



Kontos Airdrop 2024 - Eligibility, Process and Rewards
%201.svg)
%201.svg)


Cryptocurrency enthusiasts, get ready for an exciting opportunity! Kontos, a revolutionary zero-knowledge-based L2 account protocol, is conducting an upcoming airdrop supported by Binance. This airdrop presents a chance for participants to gain upto $5,000 in value potentially.
In this comprehensive guide, we will walk you through the eligibility criteria, the step-by-step process to participate in the airdrop, and how to maximize your rewards. So, let's dive in and explore the world of Kontos Airdrop 2024!
What is Kontos?
Kontos is a cutting-edge L2 account protocol that operates with a zero-knowledge approach. This innovative technology empowers users with gas-less transactions, asset-less operations, and enhanced security.
The project has successfully raised $10M from prominent funds such as Binance Labs, Shima Capital, and The Spartan Group. Kontos specializes in four types of abstraction: account abstraction, asset abstraction, chain abstraction, and behavior abstraction.
These abstractions enable asset-less and key-less trades, giving users greater flexibility in managing their digital assets.
Eligibility Criteria for the Kontos Airdrop
To qualify for the Kontos Airdrop, participants need to follow certain criteria. While the specific details of the airdrop are not disclosed in the reference articles, it is important to stay informed about the latest updates and announcements from Kontos.
Monitor their official website and social media channels to ensure you meet the eligibility requirements. Stay tuned for any additional information that may be released, as it could impact your chances of participating in the airdrop.
Kontos Airdrop Details
The Kontos Airdrop is a highly anticipated event for cryptocurrency enthusiasts. Here are some key details you need to know:
- Cost: FREE
- Time Required: Approximately 15 minutes
- Potential Gain: $5,000
Please note that these details are based on available information at the time of writing. As the airdrop approaches, staying updated with the latest announcements from Kontos for any changes or additional requirements is recommended.
Step-by-Step Guide to Participating in the Airdrop
Participating in the Kontos Airdrop is a straightforward process that requires a few simple steps. Here's a comprehensive guide to help you get started:
Step 1: Setting up your Wallet
To begin, visit the official Kontos website and create a new wallet. Set your username, password, and PIN to ensure the security of your account.
A reliable wallet is essential for storing and managing your Kontos tokens effectively.
Step 2: Bridging Funds
Next, you must bridge funds from your existing wallet to your Kontos wallet. Visit the Kontos bridge platform and connect your Metamask wallet.
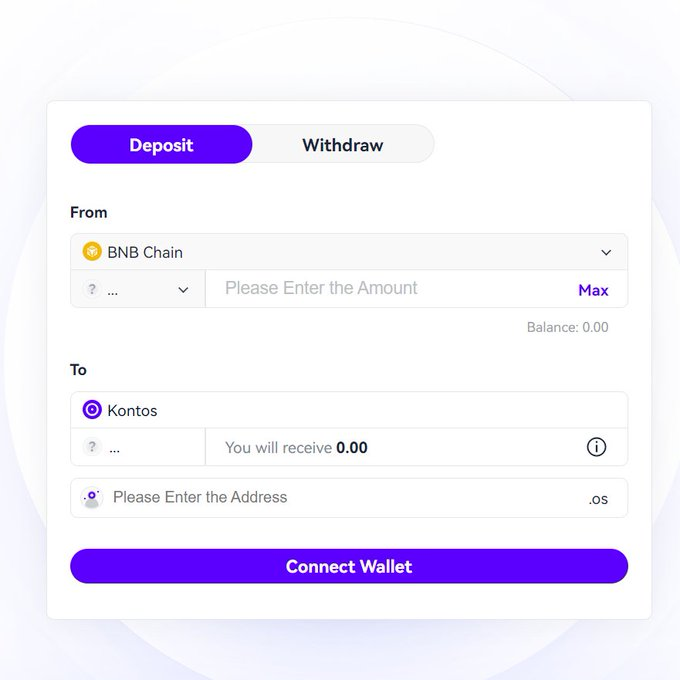
Switch to the Binance Smart Chain (BSC) network and bridge some BNB or USDT to your Kontos wallet. This step may incur a small transaction fee of $0.1.
Step 3: Interact with the Kontos Discord Bot
Join the official Kontos Discord server and navigate to the "Bot-command" tab. Enter the command "/Register" to register your account for the airdrop.
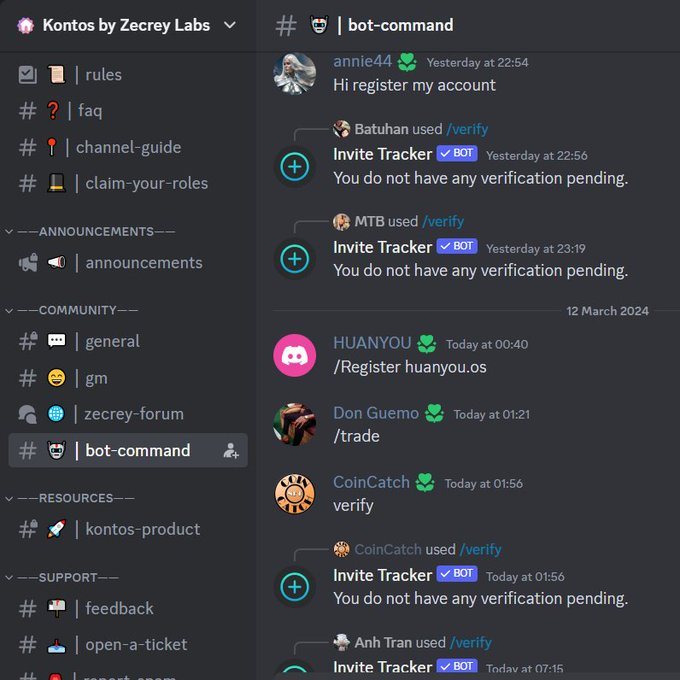
Interacting with the Kontos Discord Bot is a crucial step in the airdrop process, so ensure you complete the registration process as instructed.
Step 4: Trading and Bridging
To maximize your rewards, it is recommended to explore the trading and bridging functionalities offered by Kontos. Use the command "/trade" to initiate a trade and "/bridge" to bridge tokens between different networks.
Follow the instructions provided and make sure to complete at least one bridge transaction with a minimum value of $1.

Throughout the entire process, stay connected with the Kontos community and follow their official social media channels for any updates, tips, or additional steps that may be announced.
Step 5: Galxe task
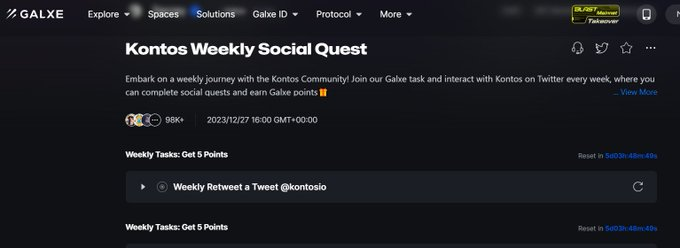
Go to → https://galxe.com/Zecrey/campaign/GCfXRttJbf
◈ Complete weekly tasks to earn points.
Maximizing Your Rewards: Tips and Strategies
To make the most of the Kontos Airdrop and potentially increase your rewards, consider the following tips and strategies:
- Stay Updated: Regularly check the official Kontos website, social media channels, and community forums for the latest updates, announcements, and tips related to the airdrop.
- Engage with the Community: Join the Kontos Discord server and actively participate in discussions. Engaging with the community can provide valuable insights, tips, and potential opportunities to enhance your airdrop experience.
- Network Effect: Spread the word about the Kontos Airdrop within your network of friends, family, and fellow cryptocurrency enthusiasts. Sharing information and inviting others to participate can potentially earn you referral bonuses or other rewards.
- Follow the Instructions Carefully: Pay close attention to the step-by-step instructions provided by Kontos. Following the guidelines accurately will ensure a smooth and successful participation in the airdrop.
- Security First: Always prioritize the security of your wallet and personal information. Be cautious of phishing attempts and only interact with official Kontos platforms and channels.
Potential Value and Benefits of Kontos Tokens
Participating in the Kontos Airdrop can potentially provide you with valuable Kontos tokens. These tokens hold the potential for future growth and utility within the Kontos ecosystem. As a holder of Kontos tokens, you may benefit from various platform features and opportunities, such as:
- Gas-less transactions
- Asset-less operations
- Enhanced security measures
- Diverse asset purchases across multiple networks
The true potential and long-term value of Kontos tokens can only be realized through active engagement with the platform and staying informed about the project's developments.
Also Read - Top Upcoming Crypto Airdrops 2024
Kontos Airdrop - Impact on Participants and the Platform
Participating in the Kontos Airdrop not only offers the potential for financial gain but also allows individuals to become part of an innovative ecosystem.
By joining the Kontos community, participants can contribute to the platform's growth, provide feedback, and shape its future.
Also, the airdrop creates an opportunity to explore the unique features and benefits offered by Kontos and gain a deeper understanding of the project's vision.
Conclusion
The Kontos Airdrop 2024 presents an exciting opportunity for cryptocurrency enthusiasts to earn substantial rewards potentially. Participants can maximize their chances of success by following the step-by-step guide, staying updated with the latest information, and implementing effective strategies.
Remember to prioritize security, engage with the community, and explore the potential benefits of Kontos tokens. As the airdrop approaches, make sure to check the official Kontos channels regularly for any updates and additional details. Get ready to join the Kontos revolution and unlock the potential for a brighter crypto future!
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other advice, and you should not treat any of the website's content as such.
Token Metrics does not recommend buying, selling, or holding any cryptocurrency. Conduct your due diligence and consult your financial advisor before making investment decisions.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.