



What is Litecoin Halving and its Impact?
%201.svg)
%201.svg)


Cryptocurrency enthusiasts and investors always look for events that can potentially impact their favorite digital assets' price and market dynamics. One such event that often generates excitement and speculation is halving.
In this comprehensive guide, we will delve into the world of Litecoin halving, exploring its meaning, the potential impact on price, and strategies for trading this critical milestone. So, fasten your seatbelts and join us on this journey to uncover the secrets of Litecoin halving.
Understanding Litecoin Halving
Litecoin, often referred to as Bitcoin's "little brother," shares many similarities with its more famous counterpart. One of these similarities is the mechanism of halving.
Litecoin halving is a process that occurs approximately every four years, reducing the mining rewards for validating transactions on the Litecoin blockchain.
This reduction in rewards has significant implications for miners, the Litecoin ecosystem, and the price of Litecoin itself.
Unlike traditional fiat currencies, which can be printed at will by central banks, cryptocurrencies like Litecoin have a limited supply. In the case of Litecoin, the maximum supply is set at 84 million coins.
The purpose of halving is to control the rate at which new Litecoins are introduced into circulation, ensuring a gradual and predictable issuance of new coins. By reducing the block rewards, Litecoin aims to maintain scarcity and prevent inflationary pressures.
The Mechanics of Litecoin Halving
To understand Litecoin halving, we must first grasp the concept of block rewards. New Litecoins are created when miners add new transactions to blocks.
The miner who successfully adds a block to the Litecoin blockchain is rewarded with a certain amount of Litecoin. This reward consists of a fixed number of new Litecoins and transaction fees included in the block.
Litecoin halving occurs after every 840,000 blocks are mined. Considering the average block mining rate of 2.5 minutes, this event takes place approximately once every four years.
During halving, the block reward is cut in half, reducing the number of Litecoins awarded to miners for validating transactions. This process will continue until no more Litecoins are left to mine, which is estimated to occur around the year 2142.
The Impact of Litecoin Halving
Litecoin halving has a twofold impact: on miners and on the price of Litecoin itself. Let's explore these effects in more detail:
Impact on Miners: Reducing block rewards directly affects miners' income. With each halving event, miners receive fewer Litecoins for their efforts in validating transactions.
This decrease in rewards can have profound implications for the mining community. On one hand, it may discourage less serious miners who are primarily motivated by potential financial gains.
On the other hand, it can create an environment where only committed and dedicated miners continue to operate, ensuring the security and stability of the Litecoin network.
Also Read - How to Mine Litecoin?
Impact on Price: The halving event also has implications for the price of Litecoin. Reducing mining rewards leads to a decrease in the supply of newly minted Litecoins.
This decrease in supply, coupled with the constant demand for Litecoin, can create a supply-demand imbalance, potentially driving up the price of the LTC.
However, it is essential to note that the price action following halving events is highly unpredictable and influenced by various factors such as market sentiment, investor behavior, and overall market conditions.
Litecoin Halving History
Litecoin has already experienced halving events in its history. Let's take a closer look at some of Litecoin's halving dates:
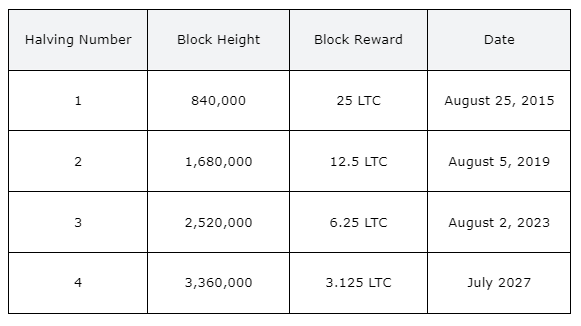
As per the existing schedule, Litecoin halving events occur approximately every four years. The next halving is expected to occur in 2027, further reducing the block reward to 1.5625 LTC. These halving events play a vital role in controlling the issuance of new Litecoins and maintaining scarcity in the long run.
Litecoin Halving and Price Predictions
One of the most common questions surrounding Litecoin's halving is how it will impact the price of the cryptocurrency.
While it is challenging to provide an accurate prediction, historical data, and market trends can give us some insights into potential price movements.
Previous Litecoin Halving Price Trends
Looking back at the previous halvings, Litecoin's price exhibited distinct patterns following each event. Let's examine the price trends after the first and second Litecoin halvings:
First Litecoin Halving (August 25, 2015)
After the first halving, Litecoin's price initially traded sideways for over a year, entering a phase of stagnation.
While a buy-and-hold strategy may not have been the most profitable approach during this period, traders employing ranging market strategies could have capitalized on the price fluctuations.
This stagnation phase was followed by a bull phase, characterized by a significant increase in Litecoin's price over a period of six months to a year.
A pullback/bear phase eventually succeeded the bull phase, marked by a correction lasting approximately a year. Finally, Litecoin entered an accumulation phase, likely driven by pre-halving accumulation, before the cycle repeated itself with the second halving.
Also Read - Next Crypto Bull Run
Second Litecoin Halving (August 5, 2019)
The second halving event saw a different price trajectory for Litecoin. Prior to the halving, Litecoin experienced an upward trend, reaching a peak in July 2019.
However, the price started to decline immediately after the halving, leading to a period of bearish sentiment. The price continued to fall until it stabilized, and the market entered a period of consolidation and accumulation.
Price Predictions for Future Halvings
Predicting the exact impact of the upcoming Litecoin halving on its price is challenging. While historical data provides some insights, it is crucial to consider other fundamental factors that influence Litecoin's price volatility and trends.
Factors such as Bitcoin's price movements, the level of adoption of Litecoin, and overall market sentiment can significantly influence the price of Litecoin in the long run.
While past halving events have historically positively impacted the price of Litecoin, it is important to note that past performance does not guarantee future results.
Market conditions and cryptocurrency prices can be highly volatile, and the future performance of Litecoin is subject to various factors and uncertainties.
Therefore, it is advisable to conduct thorough research, consider the risks associated with cryptocurrency investments, and consult a financial advisor before making any investment decisions.
Conclusion
Litecoin halving is a significant event in the world of cryptocurrencies, with potential implications for miners, the price of Litecoin, and trading strategies.
Understanding the mechanics and history of Litecoin halving can provide valuable insights for investors and traders.
While the exact impact of halving on Litecoin's price is uncertain, it is essential to consider various factors and conduct thorough research before making any investment decisions.
Whether you choose to trade Litecoin halving or explore other avenues to grow your Litecoin holdings, always remember to stay informed, manage risk effectively, and consult with professionals when needed.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other advice, and you should not treat any of the website's content as such.
Token Metrics does not recommend buying, selling, or holding any cryptocurrency. Conduct your due diligence and consult your financial advisor before making investment decisions.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.