



Our x402 Integration Is Live: Pay-Per-Call Access to Token Metrics—No API Key Required
%201.svg)
%201.svg)


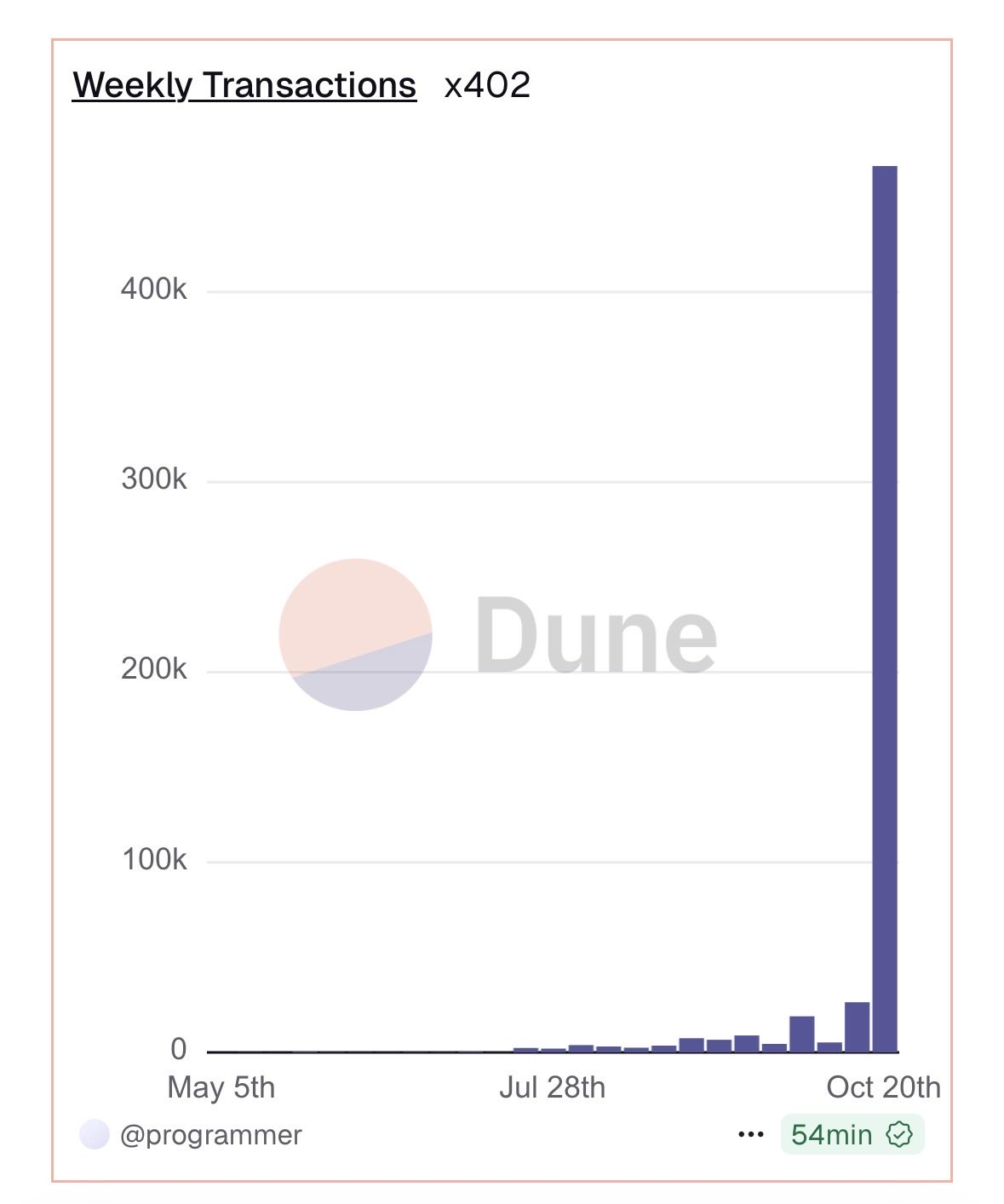
Developers are already shipping with x402 at scale: 450,000+ weekly transactions, 700+ projects. This momentum is why our Token Metrics x402 integration matters for agents and apps that need real crypto intelligence on demand. You can now pay per API call using HTTP 402 and the x-coinbase-402 header, no API key required.
Summary: Pay per API call to Token Metrics with x402 on Base using USDC or TMAI, set x-coinbase-402: true, and get instant access to trading signals, grades, and AI reports.
Check out the x402 ecosystem on Coingecko.

What You Get
Token Metrics now supports x402, the HTTP-native payment protocol from Coinbase. Users can call any public endpoint by paying per request with a wallet, eliminating API key management and upfront subscriptions. This makes Token Metrics data instantly accessible to AI agents, researchers, and developers who want on-demand crypto intelligence.
x402 enables truly flexible access where you pay only for what you use, with transparent per-call pricing in USDC or TMAI. The integration is live now across all Token Metrics public endpoints, from trading signals to AI reports. Here's everything you need to start calling Token Metrics with x402 today.
Quick Start
Get started with x402 + Token Metrics in three steps.
- Create a wallet client: Follow the x402 Quickstart for Buyers to set up a wallet client (Node.js with viem or Python with eth-account). Link: https://docs.cdp.coinbase.com/x402/docs/quickstart-buyers
- Set required headers: Add x-coinbase-402: true to any Token Metrics request. Optionally set x-payment-token: tmai for a 10% discount (defaults to usdc). Do not send x-api-key when using x402.
- Call any endpoint: Make a request to https://api.tokenmetrics.com/v2/[endpoint] with your wallet client. Payment happens automatically via x402 settlement.
That is it. Your wallet pays per call, and you get instant access to Token Metrics data with no subscription overhead.
Required Headers

Endpoint Pricing
Transparent per-call pricing across all Token Metrics public endpoints. Pay in USDC or get 10% off with TMAI.




All prices are per single call. Paying with TMAI automatically applies a 10% discount.
Try It on x402 Composer
If you want to see x402 + Token Metrics in action without writing code, head to x402 Composer. Composer is x402scan's playground for AI agents that pay per tool call. You can open a Token Metrics agent, chat with it, and watch real tool calls and USDC/TMAI settlements stream into the live Feed.
Composer surfaces active agents using Token Metrics endpoints like trading signals, price predictions, and AI reports. It is a great way to explore what is possible before you build your own integration. Link: https://x402scan.com/composer
Why x402 Changes the Game
Traditional API access requires upfront subscriptions, fixed rate limits, and key management overhead. x402 flips that model by letting you pay per call with a crypto wallet, with no API keys or monthly commitments. This is especially powerful for AI agents, which need flexible, on-demand access to external data without human intervention.
For Token Metrics, x402 unlocks agentic commerce where agents can autonomously pull crypto intelligence, pay only for what they use, and compose our endpoints with other x402-enabled tools like Heurist Mesh, Tavily, and Firecrawl. It is HTTP-native payments meeting real-world agent workflows.
What is x402?
x402 is an open-source HTTP-native payment protocol developed by Coinbase. It uses the HTTP 402 status code (Payment Required) to enable pay-per-request access to APIs and services. When you make a request with the x-coinbase-402 header, the server returns a payment challenge, your wallet signs and submits payment, and the server fulfills the request once settlement is verified.
The protocol runs on Base and Solana, with USDC and TMAI as the primary payment tokens. x402 is designed for composability, agents can chain multiple paid calls across different providers in a single workflow, paying each service directly without intermediaries. Learn more at the x402 Quickstart for Buyers: https://docs.cdp.coinbase.com/x402/docs/quickstart-buyers
FAQs
Do I need an API key to use x402 with Token Metrics?
No. When you set x-coinbase-402: true, your wallet signature replaces API key authentication. Do not send x-api-key in your requests.
Can I use x402 with a free trial or test wallet?
Yes, but you will need testnet USDC or TMAI on Base Sepolia (testnet) for development. Production calls require mainnet tokens.
How do I see my payment history?
Check x402scan for transaction logs and tool call history. Your wallet will also show outgoing USDC/TMAI transactions. Visit https://www.x402scan.com.
What happens if my wallet balance is too low?
The x402 client will return a payment failure before making the API call. Top up your wallet and retry.
Can I use x402 in production apps?
Yes. x402 is live on Base mainnet. Set appropriate spend limits and handle payment errors gracefully in your code.
Next Steps
- Read the x402 Quickstart for Buyers: https://docs.cdp.coinbase.com/x402/docs/quickstart-buyers
- Explore Token Metrics agents on Composer: https://x402scan.com/composer
- Browse endpoint docs and pricing: https://app.tokenmetrics.com/en/api-plans
- Join the conversation: Follow @tokenmetrics and @x402scan on X (Twitter)
Disclosure
Educational and informational purposes only. x402 involves crypto payments on public blockchains. Understand the risks, manage your wallet security, and test thoroughly before production use. Token Metrics does not provide financial advice.
Powered by Token Metrics
Your AI-powered crypto research experience is made possible by Token Metrics. Discover data-driven insights and advanced analytics on your favorite coins and tokens.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.