



Ripple (XRP) Price Prediction 2025: Will XRP Hit $500 This Bull Cycle?
%201.svg)
%201.svg)
%20Price%20Prediction%202025_%20Will%20XRP%20Hit%20%2410%20This%20Bull%20Cycle_.png)
Ripple’s native token, XRP, is experiencing renewed momentum in 2025, surging to $2.58 and breaking the long-standing $2.50 resistance level. This price movement coincides with Bitcoin's rally past $112,000, signaling that XRP is riding the current bull market wave.
But what’s driving this surge in XRP? Is it sustainable? And could we see XRP hit $5, $7—or even $10—before the end of 2025?

In this highly informative and SEO-optimized blog post, we analyze the factors behind XRP’s rise, evaluate its future potential, and explain why Token Metrics’ AI-powered price prediction tools offer unmatched insights for crypto investors.
🚀 XRP’s Bullish Breakout: A New Chapter in 2025
In July 2025, XRP’s breakout above $2.50 marks one of its strongest price performances since the 2017 bull run. Key drivers behind this bullish trend include:
✅ 1. Ripple’s Legal Victory Against the SEC
Ripple finalized its years-long lawsuit with the U.S. Securities and Exchange Commission (SEC) by paying a $50 million settlement—without admitting XRP is a security. This outcome:
- Removes a major legal overhang
- Boosts investor and institutional confidence
- Clears the path for U.S. regulatory clarity
With the lawsuit resolved, XRP is now eligible for listings, ETF consideration, and greater adoption in regulated financial environments.
✅ 2. Launch of RLUSD Stablecoin
Ripple has successfully launched RLUSD, its native stablecoin backed 1:1 by U.S. dollars. RLUSD provides:
- Liquidity for XRP-based DeFi
- Seamless on/off ramps for cross-border payments
- Utility for RippleNet’s institutional clients
This ecosystem expansion strengthens Ripple’s value proposition and increases XRP utility and demand.
✅ 3. Potential Approval of XRP ETFs
With Ethereum and Bitcoin ETFs already active, XRP is next in line. Analysts estimate:
- A 90%+ likelihood of XRP ETF approval before 2026
- Significant inflows from institutional investors upon approval
ETF listings would make XRP easily accessible in retirement accounts, financial advisors’ portfolios, and wealth management platforms—further legitimizing the asset.
✅ 4. Expanding Global Financial Partnerships
Ripple now boasts partnerships with 300+ financial institutions, including:
- Santander
- Standard Chartered
- SBI Holdings
- Integration with Wormhole for cross-chain liquidity
This positions XRP as a global standard for cross-border payments—a market worth $150+ trillion annually.
📈 XRP Price Prediction for 2025
Analysts and AI models predict a strong upside potential for XRP during this bull cycle. Here's a breakdown of possible scenarios:

Breakout Level to Watch: $3.40
Support Level: $2.10
⚠️ Risks and Challenges Ahead
Despite the bullish momentum, XRP still faces several risks:
❌ 1. Regulatory Ambiguity Outside the U.S.
Although the SEC case is resolved, Ripple faces:
- Different classifications of XRP in Europe and Asia
- New compliance standards (e.g., MiCA)
- Potential resistance from central banks promoting CBDCs
❌ 2. Stablecoin Competition
RLUSD must compete with:
- USDT and USDC (dominant players)
- CBDCs and national digital currencies
- Traditional payment rails like SWIFT GPI
Failure to achieve rapid RLUSD adoption could cap XRP's growth potential.
❌ 3. Market Volatility and Profit-Taking
After explosive gains, whales may lock in profits, causing sharp pullbacks. Key support at $2.10 must hold to maintain bullish structure.
🧠 Why Token Metrics Has the Best XRP Price Prediction Tools
In a fast-moving market, investors need real-time, data-driven predictions—not guesswork. Token Metrics offers the most advanced tools for XRP investors.
✅ 1. AI-Powered Price Forecasts
Token Metrics uses machine learning models trained on years of crypto market data to generate high-accuracy price forecasts.
For XRP, these models consider:
- Whale wallet accumulation
- Cross-border transaction volume
- Stablecoin liquidity metrics
- Token velocity and exchange flows
The result? A forward-looking price forecast you can trust.
✅ 2. XRP Buy/Sell Signals
The Token Metrics platform issues real-time bullish or bearish signals based on:
- Technical indicators (MACD, RSI)
- Exchange net flow
- Trend strength
- Historical reversal patterns
These signals help you:
- Enter at optimal times
- Avoid fake breakouts
- Time your profit-taking during rallies
✅ 3. Trader and Investor Grades
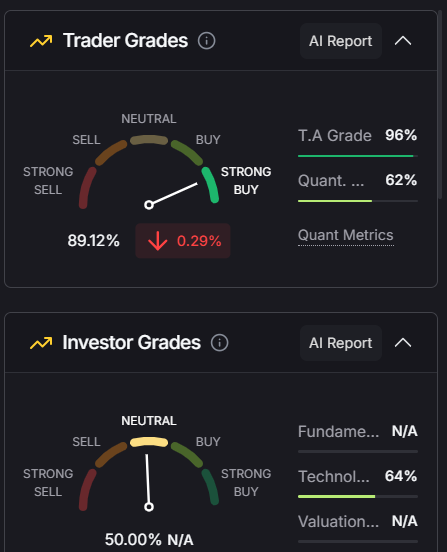
Token Metrics assigns every token—including XRP—a:
- Trader Grade (short-term trend strength)
- Investor Grade (long-term fundamental health)
Both are AI-calculated using 80+ metrics, and they update daily. This helps you:
- Decide whether to swing trade or HODL XRP
- Compare XRP with other cross-border payment tokens
✅ 4. Custom Alerts and Analysis
With Token Metrics, you can set personalized alerts for XRP:
- Price thresholds (e.g., alert me if XRP hits $3.40)
- Percent change triggers (e.g., alert me on +15% move)
- Grade changes (e.g., notify me if Trader Grade goes above 80)
Alerts are delivered via email, Slack, Telegram, or Discord—so you never miss a key movement.
✅ 5. Detailed Token Page for XRP

The XRP profile page on Token Metrics provides:
- Live price chart and ROI
- Real-time exchange volume
- Whale wallet movements
- Historical signal success rates
Everything you need for informed XRP investing in one place.
📊 XRP vs. Other Altcoins in 2025
While many altcoins are chasing narratives (AI, memecoins, DePIN), XRP’s case is fundamentally driven by:
- Regulatory clarity
- Real-world adoption
- Enterprise integrations
Token Metrics’ crypto indices help investors diversify by creating thematic portfolios (e.g., “Institutional Adoption,” “Layer-1 Networks,” “Cross-Border Payments”)—with XRP often at the top of the cross-border category.

📉 What If XRP Corrects?
Corrections are part of every bull market. If XRP fails to hold above $2.50:
- A retracement to $2.10 is likely
- A break below $2.10 could lead to a retest of $1.80
- Traders should watch BTC’s movement closely—if Bitcoin reverses sharply, XRP could follow
Use Token Metrics’ bearish signal alerts to de-risk in real time.
✅ Final Thoughts: XRP Is One to Watch in 2025
With legal clarity, a new stablecoin, ETF approval potential, and over 300 institutional partnerships, Ripple and XRP are in their strongest position in years.
If Bitcoin continues its uptrend and XRP breaks above $3.40, the next major rally could take it to $5–$10 by the end of 2025.
But success depends on regulatory support, stablecoin adoption, and institutional inflows—all factors Token Metrics tracks daily with precision.
🔍 Take Action: Use Token Metrics to Trade XRP Smarter
- Track XRP’s real-time price predictions
- Monitor short- and long-term signal strength
- Set alerts for breakouts or corrections
- Analyze fundamentals and on-chain data
👉 Start now at tokenmetrics.com and gain an edge in XRP trading and investing
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.