



Toncoin Price Prediction 2027: $5-$43 Target Analysis | TON
%201.svg)
%201.svg)


Toncoin Price Prediction Framework: Market Cap Scenarios & 2027 Price Forecasts
Layer 1 tokens capture value through transaction fees, staking, and validator economics. TON uses proof-of-stake and a multi-blockchain architecture integrated with Telegram services. This Token Metrics price prediction model analyzes TON price forecasts across different total crypto market sizes, reflecting adoption and transaction demand by 2027.
Disclosure
Educational purposes only, not financial advice. This price prediction analysis is for informational purposes. Crypto is volatile, do your own research and manage risk.
How to read this price prediction:
Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity. These price prediction scenarios provide a range of potential outcomes based on market conditions.
TM Agent baseline:
Token Metrics TM Grade is 74%, Buy, and the trading signal is bullish, indicating positive short-term momentum and strong overall project quality. Concise 12-month numeric price prediction view: scenarios cluster roughly between $5 and $14, with a base case price target near $9.
Key Takeaways for TON Price Prediction
- Scenario driven: price prediction outcomes hinge on total crypto market cap; higher liquidity and adoption lift the price targets
- Fundamentals: Fundamental Grade 80.88% (Community 83%, Tokenomics N/A, Exchange 100%, VC 84%, DeFi Scanner 85%)
- Technology: Technology Grade 77.11% (Activity 55%, Repository 72%, Collaboration 73%, Security N/A, DeFi Scanner 85%)
- TM Agent gist: bullish signal, price prediction ranges cluster around $5 to $14 with a base case near $9
- Education only, not financial advice
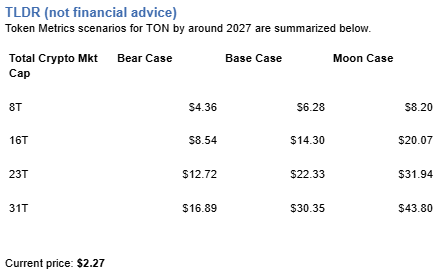
Toncoin Price Prediction: Scenario Analysis
8T Market Cap Price Prediction:
At an 8 trillion dollar total crypto market cap, TON price prediction projects to $4.36 in bear conditions, $6.28 in the base case, and $8.20 in bullish scenarios.
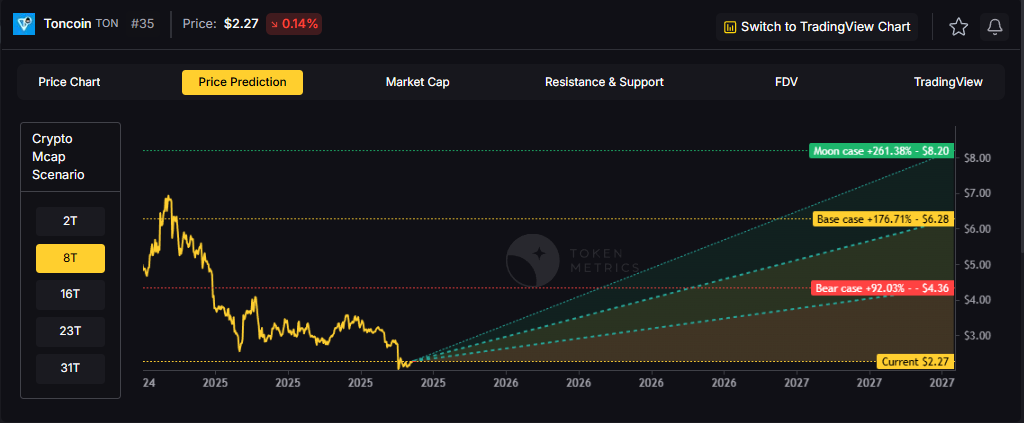
16T Market Cap Price Prediction:
At 16 trillion, the price prediction range expands to $8.54 (bear), $14.30 (base), and $20.07 (moon).
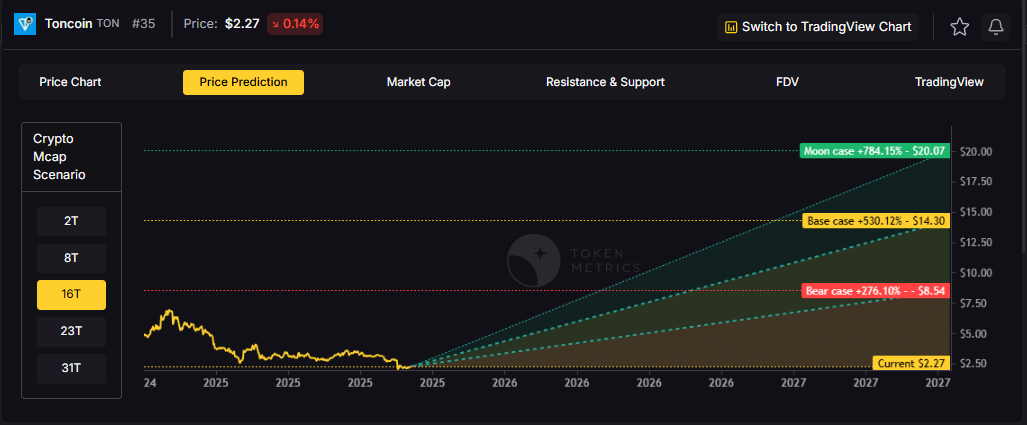
23T Market Cap Price Prediction:
The 23 trillion tier price forecast shows $12.72, $22.33, and $31.94 respectively.

31T Market Cap Price Prediction:
In the maximum liquidity scenario at 31 trillion, TON price prediction reaches $16.89 (bear), $30.35 (base), or $43.80 (moon).

What Is Toncoin?
The Open Network is a blockchain designed to support fast, low-cost transactions and a scalable ecosystem of decentralized applications. It integrates with digital services and messaging platforms to reach a broad user base, emphasizing high throughput and accessibility.
TON uses a proof-of-stake consensus mechanism with a multi-blockchain architecture. The TON token powers network activity, facilitating transactions, staking, and governance, and is integrated into Telegram-based services for user-friendly in-app payments and wallets.
Token Metrics AI Analysis for Price Prediction
Token Metrics AI provides additional context on Toncoin's technical positioning and market dynamics that inform our price prediction models.
Vision: The vision for Toncoin and The Open Network is to create a fast, secure, and scalable blockchain that enables seamless digital transactions and decentralized services, accessible to millions through integration with everyday communication tools like Telegram.
Problem: Many blockchain networks face limitations in speed, cost, and user accessibility, hindering mainstream adoption. Toncoin aims to address the friction of slow transaction times and high fees seen on older networks, while also lowering the barrier to entry for non-technical users who want to engage with decentralized applications and digital assets.
Solution: TON uses a proof-of-stake consensus mechanism with a multi-blockchain architecture to achieve high scalability and fast finality. The network supports smart contracts, decentralized storage, and domain naming, enabling a wide range of applications. Toncoin facilitates transactions, staking, and network governance, and is integrated into Telegram-based services, allowing for in-app payments and wallet functionality through user-friendly interfaces.
Market Analysis: Toncoin operates in the competitive layer-1 blockchain space, often compared to high-performance networks like Solana and Avalanche, though it differentiates itself through deep integration with Telegram's ecosystem. Its potential for mass adoption stems from access to hundreds of millions of Telegram users, which could drive network effects and utility usage. Unlike meme tokens, Toncoin's value is tied to infrastructure and real-world application rather than speculation or community hype. However, its growth depends on sustained development, regulatory clarity, and actual user engagement within Telegram. Competition from established blockchains and shifting market narratives around scalability and decentralization remain key risks. As a top-tier blockchain by ecosystem potential, Toncoin's market position is influenced more by integration milestones and user adoption than direct price dynamics.
Fundamental and Technology Snapshot from Token Metrics
- Fundamental Grade: 80.88% (Community 83%, Tokenomics N/A, Exchange 100%, VC 84%, DeFi Scanner 85%)
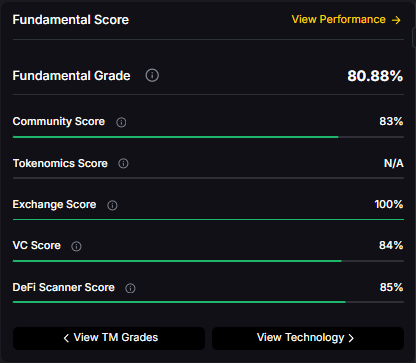
- Technology Grade: 77.11% (Activity 55%, Repository 72%, Collaboration 73%, Security N/A, DeFi Scanner 85%)

Catalysts That Skew Bullish for Price Prediction
- Institutional and retail access expands with ETFs, listings, and integrations
- Macro tailwinds from lower real rates and improving liquidity
- Product or roadmap milestones such as upgrades, scaling, or partnerships
- These factors could push TON toward higher price prediction targets
Risks That Skew Bearish for Price Prediction
- Macro risk-off from tightening or liquidity shocks
- Regulatory actions or infrastructure outages
- Concentration in validator economics and competitive displacement
- These factors could push TON toward lower price prediction scenarios
FAQs: Toncoin Price Prediction
How does TON accrue value?Value accrual mechanisms include transaction fees, validator staking rewards, and governance alignment described for TON in the documentation. As Toncoin usage grows through transactions and user activity, TON can capture network fees and staking yields while coordinating governance. Effectiveness depends on sustained adoption and network throughput, which directly impacts long-term price prediction models.
What price could TON reach in the moon case price prediction?Moon case price predictions range from $8.20 at 8T to $43.80 at 31T total crypto market cap. These price prediction scenarios require maximum market cap expansion and strong network adoption with robust liquidity conditions. Not financial advice.
What is the 2027 Toncoin price prediction?Based on Token Metrics analysis, the 2027 price prediction for Toncoin clusters between $5 and $14 in the base case, with potential for higher targets ($20-$43) in bullish scenarios if the total crypto market expands significantly.

Next Steps
• Track live grades and signals: Token Details
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How Token Metrics Can Help
Token Metrics combines fundamental, technical, and on-chain AI-powered analysis for actionable ratings, signals, and research. Use our data platform for scenario-based investing, backtested grades, and bespoke insights for digital asset markets.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.