



Top Data Availability Layers (2025)
%201.svg)
%201.svg)


Who this guide is for. Teams launching rollups or appchains that need reliable, verifiable data availability layers to minimize costs while preserving security.
Top three picks.
- Celestia — lowest-friction modular DA with broad tooling and clear blob fee model.
- EigenDA — high-throughput, Ethereum-aligned DA with reserved/on-demand bandwidth tiers.
- Avail — production DA with developer-friendly docs and transparent fee formula.
Caveat. Fees vary by data size, congestion, and commitment type (on-chain blobs vs. off-chain DA/DAC). Always confirm region eligibility and SLAs in provider docs.
Introduction: Why Data Availability Layers Matter in November 2025
Data availability layers let rollups publish transaction data so anyone can reconstruct state and verify proofs. In 2025, modular stacks (OP Stack, Polygon CDK, ZK Stack) routinely separate execution from DA to optimize costs and performance. Your DA choice affects security (trust assumptions), fees (blob gas vs. DA network fees), and UX (latency, bandwidth caps).
Search intent here is commercial-investigational: teams comparing providers by cost, security model, and integration options. We’ll keep things concrete, link only official sources, and show exactly who each option fits.
How We Picked (Methodology & Scoring)
- Liquidity/Scale — 30%: adoption, throughput, sustained bandwidth.
- Security — 25%: trust assumptions (L1 blobs vs. DAC), transparency, docs.
- Coverage — 15%: SDKs, stacks supported (OP Stack, Polygon CDK, ZK Stack), bridges.
- Costs — 15%: posted pricing/fee mechanics.
- UX — 10%: setup, tooling, observability.
- Support — 5%: docs, guides, contact points.
Data from official docs/pricing/status pages; third-party datasets used only for cross-checks. Last updated November 2025.
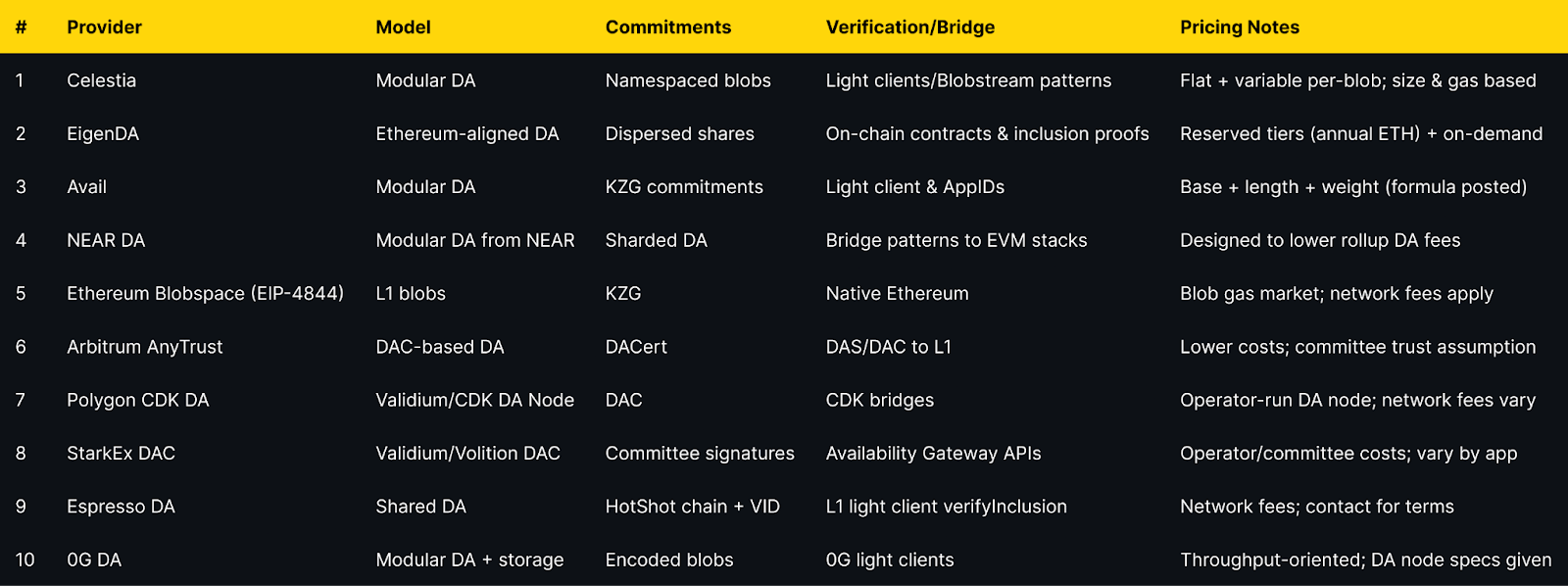
Top 10 Data Availability Layers in November 2025
1. Celestia — Best for modular DA at predictable blob economics
Why Use It. Celestia specializes in DA with namespaced blobs and data availability sampling. Fees are a flat transaction fee plus a variable component based on blob size, so costs scale with data posted rather than execution. Clear “PayForBlobs” guidance and explorers make planning straightforward. (blog.bcas.io)
Best For. OP Stack/sovereign rollups; teams optimizing DA cost; multi-chain deployments.
Notable Features. Namespaced blobs; fee market tied to blob size; tooling for PFB; docs on submitting and estimating fees. (Celestia Docs)
Fees Notes. Flat + variable per-blob; gas-price prioritized. (Celestia Docs)
Regions. Global (check validator/geography exposure in explorers).
Consider If. You want modular DA with transparent per-blob costs.
Alternatives. EigenDA, Avail.
2. EigenDA — Best for high throughput with reserved bandwidth tiers
Why Use It. EigenDA is built on EigenLayer and offers mainnet DA with published reserved bandwidth tiers (annual ETH) and on-demand options. Strong alignment with Ethereum restaking and high advertised throughput. (docs.eigencloud.xyz)
Best For. High-throughput L2s; OP Stack/Orbit/CDK chains seeking cloud-grade throughput.
Notable Features. Reserved tiers (e.g., 512–2048 KiB/s and up), on-demand pricing updates, EigenLayer operator set. (eigenda.xyz)
Fees Notes. Reserved pricing in ETH per year; on-demand available. (eigenda.xyz)
Regions. Global.
Consider If. You want capacity commitments and Ethereum-aligned security.
Alternatives. Celestia, Avail.
3. Avail — Best for dev-friendly docs and transparent fee formula
Why Use It. Avail provides DA with clear developer pathways (AppIDs, deploy rollups) and posts a fee formula: base + length + weight + optional tip. Guides include OP Stack and ZK Stack integrations. (docs.availproject.org)
Best For. Teams needing step-by-step deployment templates and cost modeling.
Notable Features. AppID model; OP Stack/Validium guides; fee components documented. (docs.availproject.org)
Fees Notes. Base + length + weight + optional tip; congestion multiplier. (docs.availproject.org)
Regions. Global.
Consider If. You want docs-first integration and a transparent pricing formula.
Alternatives. Celestia, EigenDA.
4. NEAR Data Availability (NEAR DA) — Best for cost-reduction via NEAR’s sharded DA
Why Use It. NEAR modularizes its DA layer for external rollups, aiming to lower DA fees while leveraging its sharded architecture. Official materials target Ethereum rollups explicitly. (docs.near.org)
Best For. Rollups prioritizing low DA cost and sharded throughput.
Notable Features. Sharded DA; chain-abstraction docs; community implementations (e.g., Nuffle). (docs.near.org)
Fees Notes. Designed to reduce rollup DA cost; confirm network fees in docs. (NEAR)
Regions. Global.
Consider If. You want a low-cost DA path and EVM interoperability.
Alternatives. Avail, Celestia.
5. Ethereum Blobspace (EIP-4844) — Best for maximum L1 neutrality with ephemeral blobs
Why Use It. Post data to Ethereum blobs for protocol-level guarantees during the blob retention window (~18 days). Ideal for projects that want L1 alignment and can operate within ephemeral storage constraints and blob gas markets. (Ethereum Improvement Proposals)
Best For. Security-first teams preferring L1 attestation and ecosystem neutrality.
Notable Features. KZG commitments; ephemeral blob storage; native verification. (ethereum.org)
Fees Notes. Blob gas; variable by demand; L1 network fees apply. (ethereum.org)
Regions. Global.
Consider If. You accept blob retention limits and variable blob pricing.
Alternatives. Celestia, EigenDA.
6. Arbitrum AnyTrust (DAC) — Best for cost-optimized OP-style chains using a DAC
Why Use It. AnyTrust lowers costs by storing data with a Data Availability Committee and posting certificates on L1. Detailed runbooks exist for configuring DACs for Orbit chains. (docs.arbitrum.io)
Best For. Orbit chains and apps with mild trust assumptions for lower fees.
Notable Features. DACert flow; DAS; step-by-step DAC deployment docs. (docs.arbitrum.io)
Fees Notes. Lower posting costs; committee/infra costs vary. (docs.arbitrum.io)
Regions. Global (committee member distribution varies).
Consider If. You want cheaper DA and can trust a DAC quorum.
Alternatives. Polygon CDK DA, StarkEx DAC.
7. Polygon CDK Data Availability — Best for CDK chains wanting Validium-style DA
Why Use It. CDK chains can use a DA node and DAC approach for Validium-style costs, with official repos describing the CDK DA component. Best fit if you’re already on CDK and want DA flexibility. (polygon.technology)
Best For. Polygon CDK deployers; validium-first apps.
Notable Features. CDK DA node repo; DAC configuration; CDK ecosystem tooling. (GitHub)
Fees Notes. Operator/committee costs; network fees vary by setup. (polygon.technology)
Regions. Global.
Consider If. You need CDK-native DA with Validium trade-offs.
Alternatives. Arbitrum AnyTrust, EigenDA.
8. StarkEx Data Availability Committee — Best for Validium/Volition deployments needing DAC maturity
Why Use It. StarkEx supports Validium and Volition modes via a DAC with APIs (Availability Gateway) and reference implementations for committee nodes. Production-hardened across top apps. (docs.starkware.co)
Best For. High-volume ZK apps on StarkEx preferring low DA costs.
Notable Features. DAC reference code; Volition support; batch data APIs. (GitHub)
Fees Notes. Committee/infra costs; app-specific. (docs.starkware.co)
Regions. Global (committee selection per app).
Consider If. You accept DAC trust assumptions for cost savings.
Alternatives. Arbitrum AnyTrust, Polygon CDK DA.
9. Espresso DA — Best for shared DA paired with neutral sequencing
Why Use It. Espresso offers a shared DA with HotShot consensus and a light-client verifyInclusion function for on-chain verification, designed to interoperate with other DA choices if desired. (docs.espressosys.com)
Best For. Rollups adopting shared sequencing and wanting cheap DA.
Notable Features. HotShot consensus; three-layer DA architecture; flexible with other DAs. (L2BEAT)
Fees Notes. Network fees; contact providers/infrastructure partners for terms. (blockdaemon.com)
Regions. Global.
Consider If. You want shared sequencing + DA as a package.
Alternatives. EigenDA, Celestia.
10. 0G DA — Best for high-throughput apps (AI/gaming) needing DA + storage
Why Use It. 0G pairs a DA layer with a general-purpose storage system and provides DA node specs and runbooks. Positioned for high-volume data workloads and fast retrieval. (docs.0g.ai)
Best For. Data-heavy chains (AI, gaming) needing scalable DA and storage.
Notable Features. Encoded blob data; DA node specs; whitepaper architecture (DA atop storage). (GitHub)
Fees Notes. Throughput-oriented network; confirm current pricing with 0G. (0g.ai)
Regions. Global.
Consider If. You’re optimizing for data-heavy throughput and retrieval.
Alternatives. Celestia, Avail.
Decision Guide: Best By Use Case
- Most transparent per-blob economics: Celestia. (Celestia Docs)
- Reserved capacity & high throughput: EigenDA. (eigenda.xyz)
- Docs-first integration & clear fee formula: Avail. (docs.availproject.org)
- Lowest-cost ethos (sharded DA): NEAR DA. (NEAR)
- Max L1 neutrality (ephemeral): Ethereum Blobspace (EIP-4844). (ethereum.org)
- OP-style chain with DAC: Arbitrum AnyTrust. (docs.arbitrum.io)
- Polygon CDK Validium: Polygon CDK DA. (GitHub)
- StarkEx Validium/Volition: StarkEx DAC. (docs.starkware.co)
- Shared sequencing + DA: Espresso DA. (docs.espressosys.com)
- AI/gaming data-heavy workloads: 0G DA. (docs.0g.ai)
How to Choose the Right Data Availability Layer (Checklist)
- ☐ Region eligibility and any operator restrictions documented
- ☐ Security model fits app (L1 blobs vs. modular DA vs. DAC)
- ☐ Fee mechanics are explicit (blob gas, per-blob size, or formula)
- ☐ Tooling and SDKs for your stack (OP Stack, CDK, ZK Stack)
- ☐ Throughput/bandwidth and quotas published or contractually reserved
- ☐ Observability: explorers, status pages, inclusion proofs/light clients
- ☐ Clear guides for deployment and migration paths
- ☐ Support channels and escalation (SLA/contacts)
- Red flags: no official fee notes, opaque committees, or missing verification docs.
Use Token Metrics With Any Data Availability Layer
- AI Ratings to screen assets by quality and momentum.
- Narrative Detection to spot early theme shifts.
- Portfolio Optimization to balance risk across chains.
- Alerts & Signals to time entries/exits.
Workflow: Research → Select DA → Launch rollup/appchain → Monitor with alerts.
Start free trial to screen assets and time entries with AI.
Security & Compliance Tips
- Run independent verification (light clients/inclusion proofs) where available.
- For DACs, diversify committee members and publish membership changes.
- Monitor quotas/latency; set fallbacks (e.g., switch DA mode where stack supports Alt-DA). (docs.optimism.io)
- Validate official endpoints; beware of phishing and copycat docs.
- Track fee spikes (blob gas, congestion multipliers) and set budget alarms. (ethereum.org)
- Document upgrade paths and retention windows (e.g., blob expiry). (ethereum.org)
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Treating DA choice as “set-and-forget” without monitoring fees and bandwidth.
- Ignoring blob retention on Ethereum and assuming permanence. (ethereum.org)
- Using a DAC without clear membership and recovery processes. (docs.arbitrum.io)
- Skipping test deployments to measure real blob sizes and costs.
- Overlooking verification UX (light clients/proofs) for end users.
- Assuming all stacks support seamless DA switching without work. (docs.optimism.io)
How We Picked (Methodology & Scoring)
Scoring Weights (sum = 100): Liquidity/Scale 30, Security 25, Coverage 15, Costs 15, UX 10, Support 5.
We examined official docs for pricing/fees, security/verification, and deployment guides. We favored providers with explicit fee notes (formulas or tiers), clear verification models, and active ecosystem integrations. Last updated November 2025.
FAQs
What are data availability layers?
They’re systems that publish rollup data so anyone can reconstruct state and verify proofs. They range from L1 blobs (Ethereum EIP-4844) to modular DA networks (Celestia, Avail) and DACs. (ethereum.org)
Are blobs on Ethereum permanent?
No. Blob data is retained for a limited window (~18 days). If you need permanent access, you must snapshot or use a DA with different retention. (ethereum.org)
How do DA fees work?
Fees vary: Celestia ties fees to blob size and gas; Avail publishes a base/length/weight formula; Ethereum blobs use a blob-gas market; EigenDA offers reserved bandwidth tiers. (Celestia Docs)
What’s a DAC and when should I use one?
A Data Availability Committee stores data off-chain and posts certificates or signatures to L1. It’s cheaper but introduces committee trust assumptions. Used by Arbitrum AnyTrust, StarkEx/Volition, and CDK Validium. (docs.arbitrum.io)
Can OP Stack chains plug into alternative DA?
Yes. OP Stack supports Alt-DA mode to integrate various DA layers. Validate trade-offs and tooling before switching. (docs.optimism.io)
Conclusion + Related Reads
If you want transparent per-blob costs and strong tooling, pick Celestia. For capacity commitments and Ethereum alignment, choose EigenDA. If you want a formula-based fee model with practical guides, Avail is compelling. DAC-based routes (AnyTrust, StarkEx, CDK) suit cost-sensitive apps comfortable with committee trust assumptions.
Related Reads (Token Metrics)
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.