



Top Gold & Commodity-Backed Tokens (2025)
%201.svg)
%201.svg)


Who this guide is for. Crypto investors and treasurers comparing gold-backed tokens and other commodity-backed assets that can be audited and, in many cases, redeemed for metal.
Top three picks. PAX Gold (PAXG) for regulated, bar-linked redemption; Tether Gold (XAUt) for broad awareness and simple fees; Kinesis (KAU/KAG) for spend-and-yield use cases.
Key caveat. Redemption minimums, custody locations, and fees vary by issuer; always confirm regional eligibility and schedules on the official pages.
Introduction: Why Commodity-Backed Tokens Matter in 2025
Gold-backed tokens give on-chain ownership exposure to vaulted bullion with transparent allocation and, often, physical redemption, blending the inflation hedge of metals with crypto liquidity. In 2025, they’re used for hedging, collateral, cross-border settlement, and “digital cash” backed by tangible assets. A commodity-backed token is a blockchain token that represents title to a specific quantity of a real-world commodity (for example, 1 troy ounce or 1 gram of gold) held by a custodian, typically with published fees, vault locations, and redemption rules. Our picks prioritize liquidity, security controls, breadth of metals, cost transparency, and global accessibility.
Best Commodity-Backed Tokens in November 2025 (Comparison Table)

We excluded defunct or sunset projects (e.g., PMGT; CACHE Gold ceased backing CGT on Sept 30, 2025). (perthmint.com)
Top 10 Gold & Commodity-Backed Tokens in November 2025
1) PAX Gold (PAXG) — Best for bar-linked redemption & regulatory posture
Why Use It. PAXG links each token to specific LBMA Good Delivery bars stored in London, offering direct bar redemption (institutional minimums apply) or USD redemption at spot. Paxos publishes fee schedules and notes no storage fee charged to customers at this time. (paxos.com)
Best For. Institutions; HNW hedgers; DeFi users needing reputable collateral.
Notable Features. LBMA bars; serial-number linkage; custodied in London; fiat redemption option. (paxos.com)
Fees Notes. Creation/destruction fees; no storage fee currently per issuer help center. (help.paxos.com)
Regions. Global (issuer KYC).
Consider If. You can meet bar redemption minimums and UK vault logistics. (help.paxos.com)
Alternatives. Tether Gold (XAUt); VNX Gold (VNXAU).
2) Tether Gold (XAUt) — Best for simple pricing & broad availability
Why Use It. XAUt represents allocated gold and can be redeemed for physical gold or USD; Tether publishes a straightforward 0.25% creation/redemption fee and a one-time verification fee for onboarding. FAQs outline redemption mechanics and bar specifics. (Tether)
Best For. Traders seeking brand familiarity; cross-chain users (ETH/TRON).
Notable Features. Bar metadata; physical or USD redemption; no custody fee disclosed beyond the transaction fee. (Tether)
Fees Notes. 25 bps create/redeem; separate KYC verification fee. (Tether)
Regions. Global (issuer KYC).
Consider If. You need clear fee math but don’t require bar-specific allocation like PAXG.
Alternatives. PAX Gold (PAXG); Kinesis (KAU).
3) Kinesis KAU (Gold) / KAG (Silver) — Best for spend-and-yield utility
Why Use It. Kinesis combines metal-backed tokens with an exchange, cards, and yields funded from platform fees (published yield-share). Trading and precious metals transactions show ~0.22% execution fees on official schedules. (Kinesis)
Best For. Users wanting to spend gold/silver, earn monthly yields, and keep fees predictable.
Notable Features. Fee-share yield (published); exchange, card rails; gold & silver pairs. (Kinesis)
Fees Notes. ~0.22% buy/sell/trade; other fees per schedule. (Kinesis)
Regions. Global (platform KYC/availability).
Consider If. You prefer an integrated platform over a standalone token.
Alternatives. VNX (VNXAU/VNXAG); Aurus (tXAU/tXAG).
4) Comtech Gold (CGO) — Best for XDC ecosystem & Shariah-compliant framework
Why Use It. CGO tokenizes 1g gold units on the XDC (XRC-20) network, with a published fee structure for mint/redeem (0.50%), transfers (0.50%), and custody notes in FAQs. Documentation details creation/redemption and delivery fees. (comtechgold.com)
Best For. XDC builders; users needing Shariah-compliant structuring.
Notable Features. On-chain proofing; fee schedule; vault delivery options. (comtechgold.com)
Fees Notes. 0.50% mint/redeem; 0.50% transfer; custody terms disclosed. (comtechgold.com)
Regions. Global (issuer terms apply).
Consider If. You’re comfortable with XDC rails and issuer fee model.
Alternatives. PAXG; VNXAU.
5) VNX Gold (VNXAU) — Best for EEA vaulting & multi-chain issuance
Why Use It. VNXAU gives direct ownership of allocated bars stored in Liechtenstein with a public allocation lookup tool. VNX runs on Ethereum, Polygon, Q, and Solana, and has communications on redemption and delivery. (VNX)
Best For. EEA users; diversification across chains.
Notable Features. Allocation lookup by serial; segregated AAA-jurisdiction vault; multi-chain. (VNX)
Fees Notes. See VNX pricing and product pages for current schedules.
Regions. EEA emphasis; global availability varies by KYC.
Consider If. You want EEA custody and serial-level transparency.
Alternatives. PAXG; XAUt.
6) Aurus tGOLD (tXAU) / tSILVER (tXAG) — Best for gram-denominated multi-metal exposure
Why Use It. Aurus issues 1-gram tokens backed by vaulted gold and silver with insured, audited storage. tGOLD and tSILVER support multi-chain DeFi integrations and a mobile app, with ecosystem partners for mint/redeem. (AURUS)
Best For. DeFi users; small-denomination accumulation; multi-metal portfolios (includes platinum via tXPT).
Notable Features. 1g units; insured vaulted metals; app & dashboard; partner network. (AURUS)
Fees Notes. Exchange/network fees; issuer/partner fees may apply.
Regions. Global (partner KYC where required).
Consider If. You want gram-level flexibility and cross-chain access.
Alternatives. Kinesis; VNX.
7) Gold Silver Standard (AUS/AGS) — Best for Australia-based custody & simple redemption
Why Use It. Tokens AUS (gold) and AGS (silver) are backed by allocated bullion held in Australian high-security vaults with $0 storage and transfer at the issuer level and partner-facilitated redemptions. (goldsilverstandard.com)
Best For. AUD-centric investors; straightforward physical pickup/delivery via partners.
Notable Features. 1g linkage; local redemption via Ainslie partners; Australia-first focus. (goldsilverstandard.com)
Fees Notes. Issuer lists $0 storage/transfer; exchange and redemption partner fees may apply. (goldsilverstandard.com)
Regions. Australia focus; global varies.
Consider If. You need straightforward redemption in Australia.
Alternatives. PAXG; VNXAU.
8) VNX Silver (VNXAG) — Best for EEA silver allocation & transparency tools
Why Use It. VNXAG mirrors the VNXAU model for silver, backed by allocated metal with the same allocation lookup tooling and multi-chain issuance. (VNX)
Best For. EEA investors prioritizing silver in segregated storage.
Notable Features. Allocation lookup; EEA custody; multi-chain support. (VNX)
Fees Notes. See VNX site for current schedules.
Regions. EEA emphasis; global varies.
Consider If. You want EEA-vaulted silver with serial-level transparency.
Alternatives. KAG; tXAG.
9) VeraOne (VRO) — Best for euro-area buyers wanting 1-gram ERC-20
Why Use It. VRO is an ERC-20 token pegged to 1 gram of LBMA-standard gold, issued by a long-standing French precious-metal group; materials describe secured storage and regular audits. (VeraOne)
Best For. EU users; gram-based savings; euro on-ramps.
Notable Features. 1g linkage; audited storage; EU presence. (VeraOne)
Fees Notes. Issuer materials outline model; confirm current fees on site.
Regions. EU focus; global access varies.
Consider If. You want EU branding and ERC-20 simplicity.
Alternatives. PAXG; VNXAU.
10) AgAu — Best for Swiss custody & peer-to-peer design
Why Use It. AgAu outlines 1:1 backed gold and silver tokens with Swiss custody and a peer-to-peer payment focus; docs and reports describe convertibility and audited reserves. (agau.io)
Best For. Users seeking Swiss jurisdiction and payments-style UX.
Notable Features. Swiss issuer; P2P spend; audit & documents hub. (agau.io)
Fees Notes. See issuer documentation for fees and redemption steps.
Regions. Global (jurisdictional checks apply).
Consider If. You want Swiss custody with payments emphasis.
Alternatives. VNXAU; AUS.
Decision Guide: Best by Use Case
- Regulated, bar-specific redemption: PAX Gold (PAXG). (paxos.com)
- Simple fee schedule & brand familiarity: Tether Gold (XAUt). (Tether)
- Spend metals + monthly fee-share yield: Kinesis (KAU/KAG). (Kinesis)
- XDC network users: Comtech Gold (CGO). (comtechgold.com)
- EEA custody & allocation lookup: VNX (VNXAU/VNXAG). (VNX)
- Gram-based, multi-metal DeFi: Aurus (tXAU/tXAG). (AURUS)
- Australia-centric custody & pickup: Gold Silver Standard (AUS/AGS). (goldsilverstandard.com)
- EU 1-gram ERC-20: VeraOne (VRO). (VeraOne)
- Swiss custody & P2P payments: AgAu. (agau.io)
How to Choose the Right Commodity-Backed Token (Checklist)
- ☐ Region eligibility and KYC match your profile.
- ☐ Underlying metal type and unit (ounce vs gram).
- ☐ Redemption rules: minimums, delivery locations, timelines.
- ☐ Custody: vault jurisdiction, insurer, LBMA accreditation.
- ☐ Fee transparency: creation, redemption, storage, transfer, network.
- ☐ Audit/attestation cadence and allocation lookup tools.
- ☐ Chains supported and DeFi integration needs.
- ☐ Support channels and documentation depth.
Red flags: vague custody details, unclear redemption, or discontinued programs.
Use Token Metrics With Any Commodity-Backed Token
- AI Ratings to screen metal-linked assets and related ecosystem tokens.
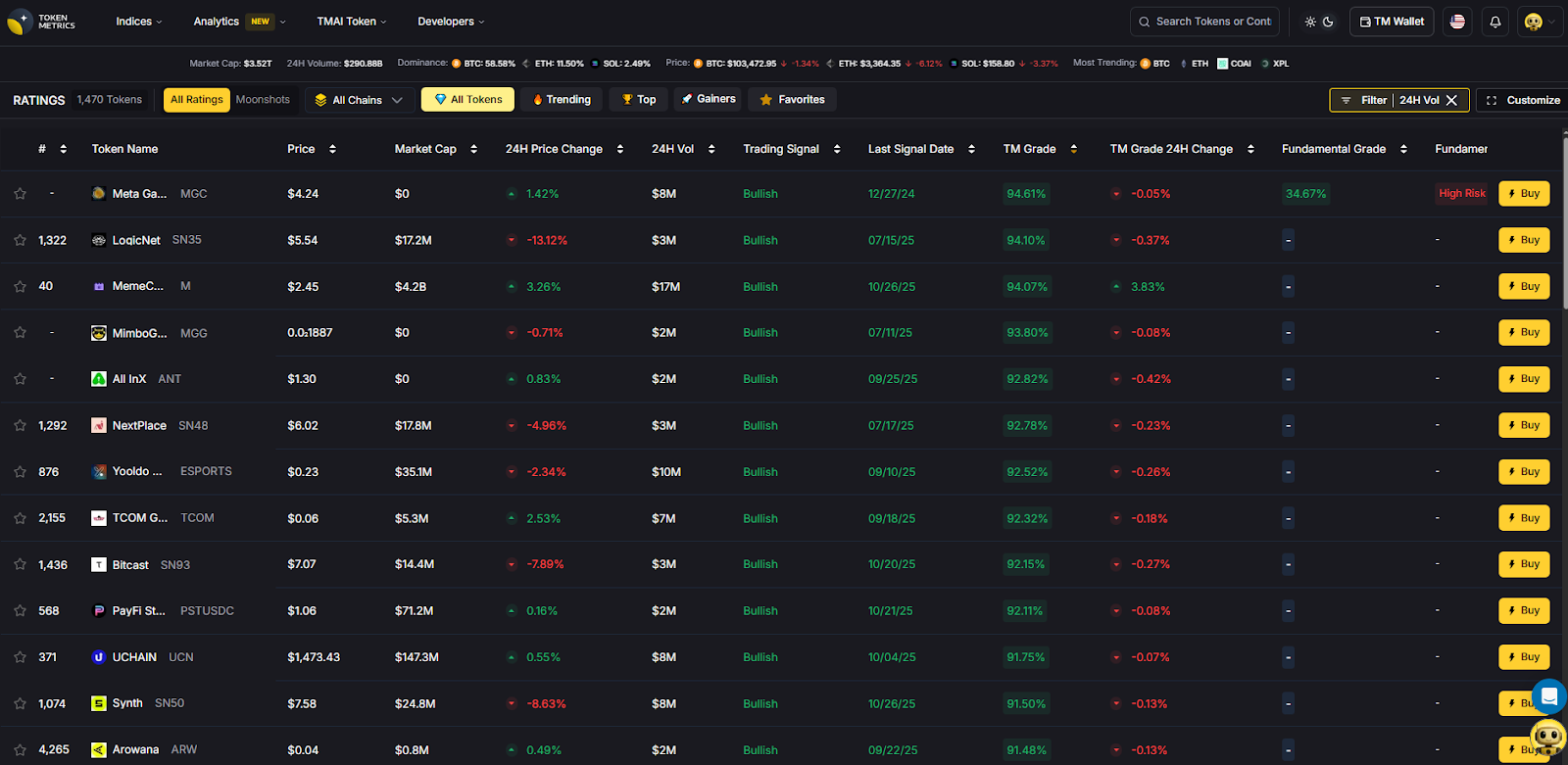
- Narrative Detection to spot inflows to on-chain RWAs.
- Portfolio Optimization to size metal exposure vs. crypto beta.
- Alerts & Signals to time entries/exits around macro prints.
Workflow: Research → Select issuer → Execute on-chain or via platform → Monitor with alerts.
CTA: Start free trial to screen assets and time entries with AI.
Security & Compliance Tips
- Use official issuer URLs only; beware look-alikes.
- Confirm fee schedules and redemption procedures before buying. (Tether)
- Verify vaulting jurisdiction and any bar-serial lookup tools. (VNX)
- Mind network fees, bridge risks, and exchange withdrawal rules.
- Keep custody keys secure; whitelist issuer addresses.
- If staking or yielding, confirm source of yield and counterparty exposure. (Kinesis)
This article is for research/education, not financial advice.
Beginner Mistakes to Avoid
- Treating all metal tokens as equal—redemption and custody differ widely.
- Ignoring region and KYC limits until you try to redeem.
- Overlooking minimums (e.g., full LBMA bars vs. gram redemptions). (help.paxos.com)
- Confusing defunct tokens with active ones (e.g., PMGT sunset; CGT backing ceased). (perthmint.com)
- Forgetting network/transfer fees when arbitraging across chains.
- Using unofficial contracts on the wrong chain.
How We Picked (Methodology & Scoring)
- Liquidity — 30%. Exchange presence, on-chain activity, practical tradability.
- Security — 25%. Custody details, audits/attestations, LBMA alignment, redemption design.
- Coverage — 15%. Metals (gold/silver/platinum), chains, tooling.
- Costs — 15%. Creation/redemption/storage/transfer and transparency of schedules.
- UX — 10%. Apps, dashboards, redemption flows.
- Support — 5%. Docs, status pages, human support.
We relied on official product, docs, fees, FAQ, and disclosure pages, cross-checking market datasets only for context. Last updated November 2025.
FAQs
What are gold-backed tokens?
They are blockchain tokens that represent ownership of a specific quantity of vaulted, insured gold, typically with published fees and, in some cases, physical redemption options.
Are gold-backed tokens safer than stablecoins?
They can diversify away from fiat risk, but introduce custody and redemption dependencies. Safety depends on the issuer’s vaulting, audits, legal structure, and your ability to redeem.
What fees should I expect?
Common fees include creation/redemption, possible storage, transfer, and network fees. Examples: XAUt lists 0.25% create/redeem; Paxos publishes creation/destruction fees and notes no storage fee currently. Always check the live schedules. (Tether)
Can I redeem tokens for a real gold bar?
Some issuers support bar redemption with minimum sizes and location constraints (e.g., LBMA bar logistics in London for PAXG). Others support gram-level redemption via partners. (help.paxos.com)
Which chains are supported?
Varies: PAXG (Ethereum), XAUt (Ethereum/TRON), VNX (Ethereum/Polygon/Q/Solana), Aurus (multi-chain), CGO (XDC), Kinesis (native + exchange listings). (paxos.com)
Are there discontinued tokens I should avoid?
Yes. PMGT has been discontinued; CACHE Gold (CGT) ceased backing as of Sept 30, 2025. Verify project status before buying. (perthmint.com)
Conclusion + Related Reads
Choose PAXG for bar-linked redemption and strong disclosures, XAUt for simple fees and brand reach, or Kinesis if you want to spend metals and earn fee-share yields. For EEA vaulting with allocation lookup, VNX is compelling; for gram-based DeFi exposure, Aurus is versatile.
Related Reads:
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.