



Treasury Companies and ETFs: How Institutional Money is Reshaping Crypto in 2025
%201.svg)
%201.svg)


The cryptocurrency market is experiencing a seismic shift as institutional adoption accelerates through treasury companies and exchange-traded funds. This institutional wave is fundamentally altering market dynamics and creating new investment opportunities for both retail and professional investors.
The Treasury Company Explosion
Treasury companies have emerged as the dominant force driving crypto adoption in 2025. These entities, which hold cryptocurrency as primary treasury assets, are experiencing unprecedented growth and creating massive buying pressure across major digital assets.
MicroStrategy Leads the Charge
MicroStrategy continues to dominate Bitcoin treasury holdings with an impressive $70 billion worth of Bitcoin, including $23 billion in unrealized gains. The company's strategy has proven so successful that it's spawning imitators across multiple cryptocurrency ecosystems.
Recent data shows treasury companies are expanding beyond Bitcoin into Ethereum and other major cryptocurrencies, creating diversified institutional exposure to digital assets.
Ethereum Treasury Revolution
BitMine recently made headlines with a $2.2 billion Ethereum purchase, signaling institutional confidence in ETH's long-term prospects. The company has set an ambitious target of capturing 5% of Ethereum's total supply, demonstrating the scale of institutional appetite.
This move coincides with Ethereum hitting new all-time highs of $4,946, up 250% from April lows. The combination of treasury company purchases and growing DeFi activity has created a powerful upward momentum for ETH.
Beyond Bitcoin: Diversification Across Ecosystems
Solana Treasury Strategies
The Solana ecosystem is witnessing significant institutional interest:
- Sharp Technologies raised $400 million with Paradigm and Pantera for SOL treasury operations
- Galaxy Jump and Multicoin are raising $1 billion for a Solana-focused treasury company
- These developments suggest Solana may soon follow Bitcoin and Ethereum's institutional adoption path
BNB Strategic Holdings
B Strategy, backed by Binance founder CZ and former Bitman CFO, launched a $1 billion US-listed vehicle specifically to purchase BNB tokens. This institutional backing provides significant credibility to Binance's native token and demonstrates the expanding scope of treasury strategies.
The Stablecoin Revolution
Parallel to treasury company growth, stablecoins are experiencing explosive expansion. Total stablecoin supply now exceeds $250 billion, with projections suggesting growth to $1 trillion by next year.
MetaMask Enters the Stablecoin Race
MetaMask's launch of MUSD, their native stablecoin developed with Bridge (acquired by Stripe), represents a significant development. Key features include:
- Multi-chain deployment: Initially on Ethereum and Linea
- 30 million user base: Immediate access to a massive user network
- MasterCard integration: Direct retail spending capabilities
- Seamless experience: On-ramp, swap, transfers, and bridging within MetaMask
Current supply stands at 41 million MUSD with 5,000 holders, but this is expected to grow rapidly to billions given MetaMask's user base.
Traditional Institution Adoption
Several major developments indicate mainstream financial adoption:
Singapore's DBS Bank launched tokenized structured notes on Ethereum mainnet, though initially limited to accredited investors.
SBI Holdings from Japan, managing $74 billion, entered a joint venture with Startale to tokenize US and Japanese stocks, enabling 24/7 trading and fractional ownership.
Multiple South Korean banks are in discussions with Tether and Circle to distribute USD stablecoins, following increasing regulatory clarity.
ETF Expansion and Regulatory Progress
The ETF landscape continues expanding beyond Bitcoin, creating new institutional access points:
Solana ETF Applications
- VanEck and Jito filed for Solana ETF applications
- Solana Foundation and Multicoin are leveraging SEC guidelines for liquid staking ETFs
- The deadline for approval is October, with industry experts optimistic about approval
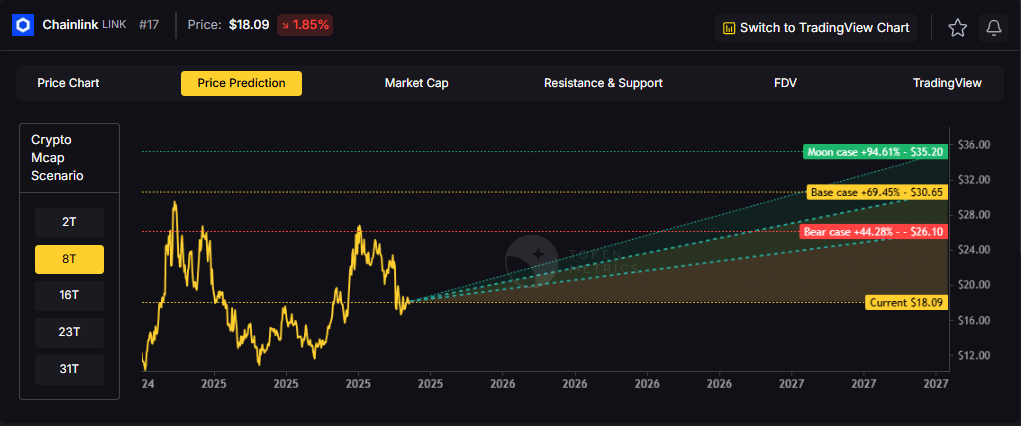
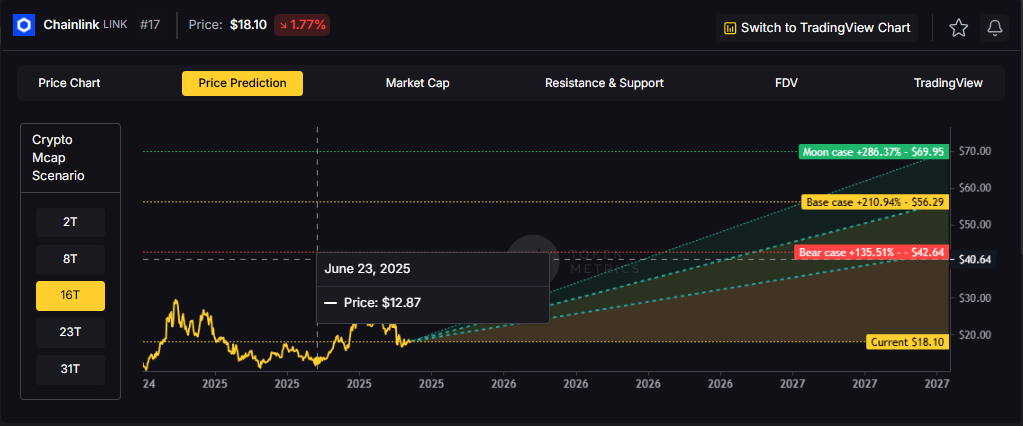
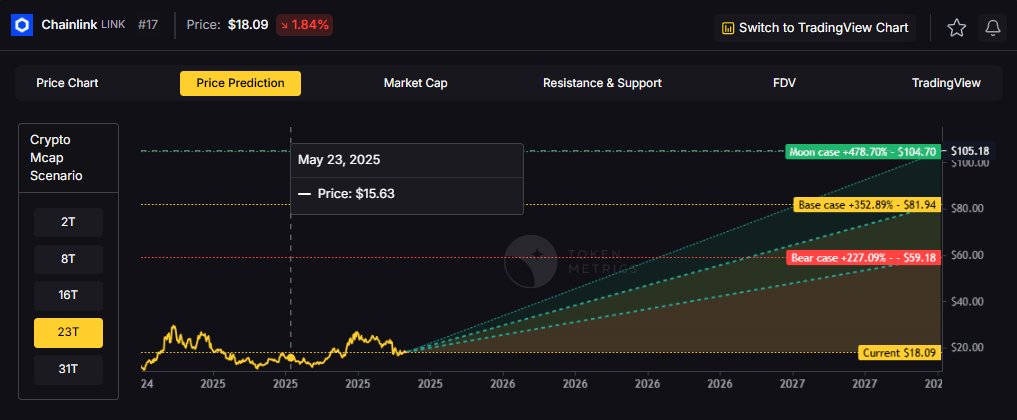
Ethereum Momentum
Ethereum ETFs are seeing increased inflows as institutional interest grows. The combination of ETF buying and treasury company purchases is creating sustained upward pressure on ETH prices.

AI and Privacy Tokens Gaining Institutional Interest
Venice AI: Privacy-Focused Innovation
Vanna AI represents a new category of projects attracting institutional attention. Founded by Eric Voorhees (Shapeshift founder), the project offers:
- Privacy-first AI: Local inference without data upload to centralized servers
- Multiple AI models: Text, image, and specialized model integration
- Fair token distribution: 50% airdropped to community
- Stake for Access: API credits model with $1 per day per staked token
- Growing adoption: 6 million monthly visitors indicate mainstream appeal
The project demonstrates how utility-focused tokens can attract both institutional and retail interest through genuine product-market fit.
Hidden Opportunities in Emerging Ecosystems
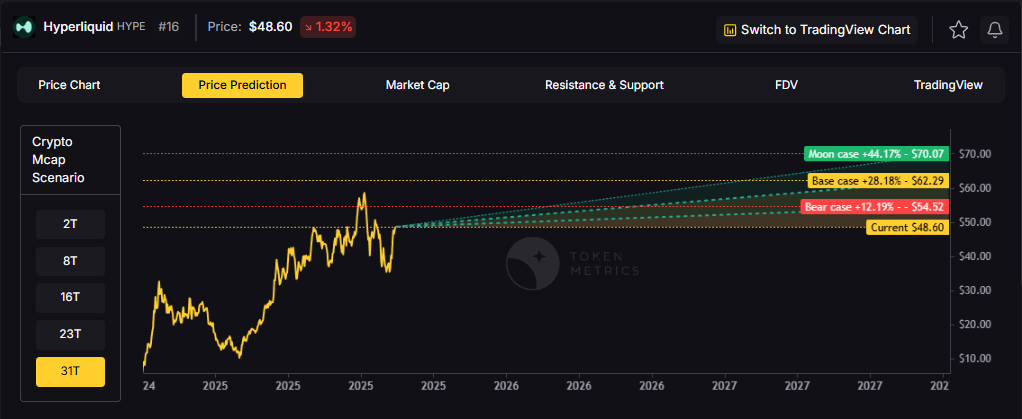
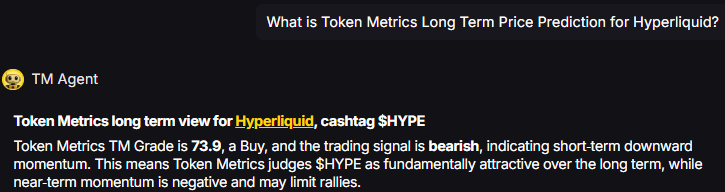
Hyperliquid Ecosystem Growth
The Hyperliquid ecosystem is experiencing explosive growth, with several projects showing institutional-grade metrics:
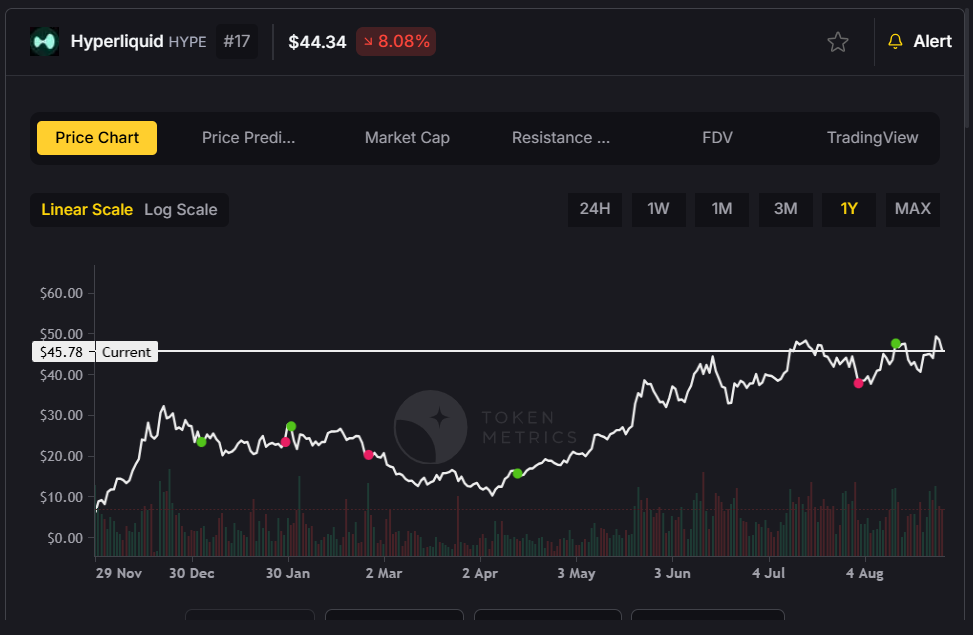
Kinetic Protocol serves as the liquid staking solution for Hyperliquid's native HYPE token, similar to Lido for Ethereum. TVL has grown from under $400 million to over $1.7 billion, demonstrating organic adoption.
Unit Protocol acts as the native bridge for Bitcoin, Ethereum, and USDC to Hyperliquid, with nearly $1 billion TVL despite no active point system.
DeFi Infrastructure Expansion
Traditional DeFi protocols are expanding to capture multi-chain market share:
- AAVE launched on Aptos, becoming the first major DeFi protocol on a Move-language blockchain
- Multi-chain strategies are becoming standard for major protocols
- Increased TVL across networks shows growing institutional DeFi adoption
Consumer Applications and Mass Adoption
Base Ecosystem Leadership
Base, Coinbase's Layer 2 solution, is emerging as a leader in consumer-focused crypto applications. The rebrand from Coinbase Wallet to Base App signals a broader strategy to become the "super app" for crypto.
Recent consumer applications include:
- Fantasy Football platforms generating millions in revenue within days of launch
- Gaming integrations bringing Web2 users into crypto seamlessly
- Social and entertainment apps abstracting blockchain complexity
Investment Strategies for the New Landscape
Blue Chip Focus
Given the institutional wave, experts recommend focusing on established assets:
- Bitcoin: Continued treasury adoption and regulatory clarity
- Ethereum: DeFi growth and institutional ETF flows
- Solana: Emerging treasury strategies and ETF potential
- Hyperliquid: Revenue-generating protocol with strong tokenomics
Emerging Opportunities
Secondary opportunities include:
- Liquid staking tokens on growing ecosystems
- Bridge and infrastructure protocols with real revenue
- Privacy-focused AI projects with utility beyond speculation
- Consumer applications with demonstrated product-market fit
Risk Management in Institutional Markets
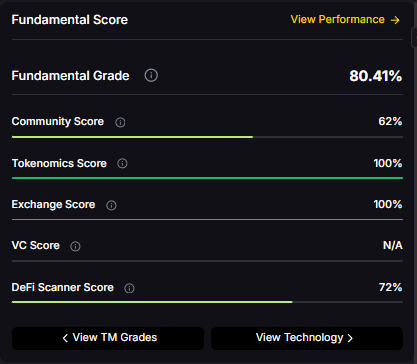
Valuation Metrics
Treasury companies often trade at premiums to their underlying holdings, similar to traditional investment vehicles. Key metrics to monitor:
- Net Asset Value (NAV): Compare stock price to underlying crypto holdings
- Premium levels: Historical peaks around 2.5x suggest caution
- Revenue generation: Focus on companies with operating businesses beyond holding crypto
Market Timing
The altcoin season indicator currently sits at 58%, approaching the 60%+ zone that historically marks cycle tops. This suggests:
- Profit-taking opportunities may emerge soon
- Risk management becomes crucial as markets mature
- Diversification across asset classes and strategies
The Future of Institutional Crypto
The institutional adoption wave shows no signs of slowing. Predictions suggest:
- $10 trillion stablecoin market within 2-3 years
- Multiple treasury companies for each major cryptocurrency
- Regulatory clarity enabling broader institutional participation
- Consumer applications bringing billions of users to crypto
Conclusion
The convergence of treasury companies, ETF expansion, and consumer application growth is creating a new phase of cryptocurrency adoption. Unlike previous cycles driven by retail speculation, this institutional wave appears sustainable and growing.
Investors who understand these trends and position accordingly—whether through direct cryptocurrency exposure, treasury company stocks, or emerging ecosystem tokens—are likely to benefit from this fundamental shift in crypto market structure.
The key is recognizing that we're no longer in an early-stage speculative market, but rather witnessing the birth of a mature digital asset class with institutional backing, regulatory clarity, and real-world utility. This transformation creates both opportunities and risks that require sophisticated analysis and strategic positioning.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)


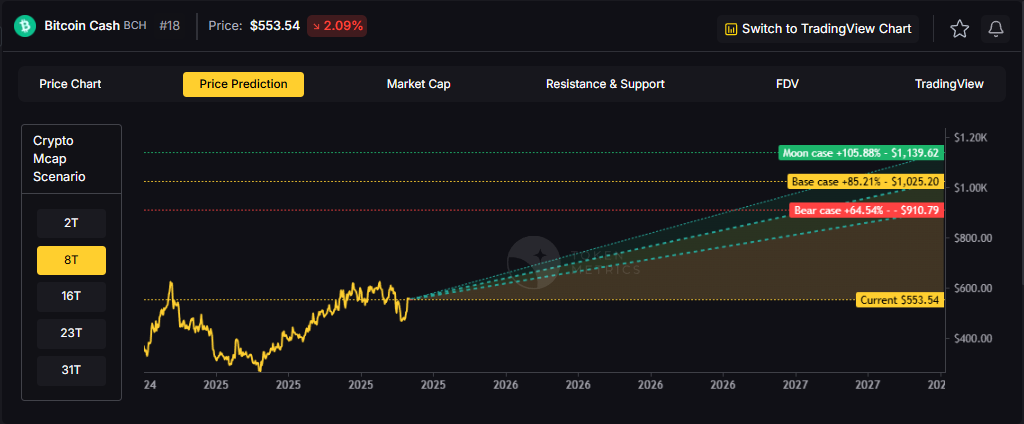


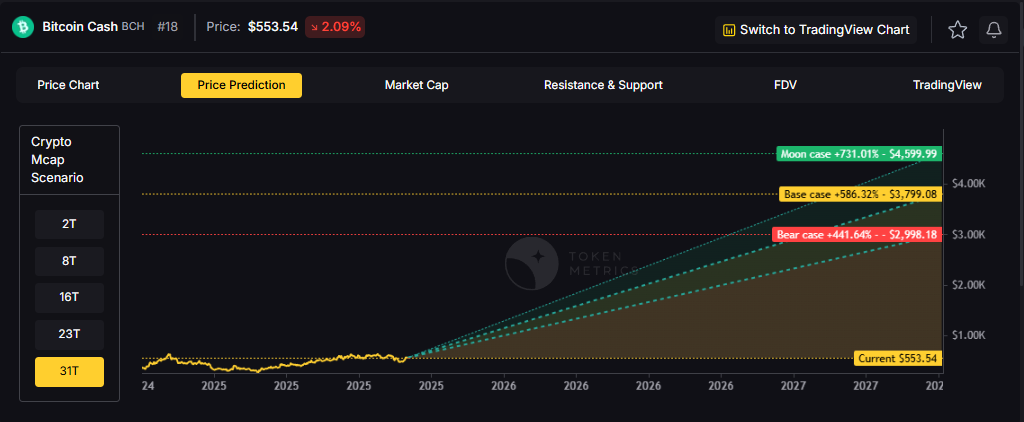













.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.