



Uniswap Price Prediction - Investment Insights and Analysis
%201.svg)
%201.svg)

Uniswap has carved a niche for itself in the decentralized finance (DeFi) ecosystem. As one of the pioneering platforms introducing an automated market maker (AMM) system, it has significantly impacted how trading is conducted on decentralized exchanges.
With the cryptocurrency market being notably volatile, potential investors and crypto enthusiasts are constantly on the lookout for opportunities.
This brings us to the pertinent question, is investing in Uniswap a wise decision or is it better to steer clear? This post delves into a thorough analysis aiming to provide a well-informed answer to this query.
Uniswap Overview
Before diving into predictions, let's understand what Uniswap is. Uniswap is a decentralized exchange protocol built on Ethereum.
Unlike traditional exchanges, where you trade with an order book, Uniswap uses liquidity pools where users can trade directly from a shared fund, earning providers a fraction of the transaction fees in return.
Historical Data of Uniswap
To predict the future, we need to look at the past. Uniswap's native token, UNI, launched in September 2020, has witnessed significant volatility, much like the broader crypto market.
Despite several ups and downs, Uniswap maintained its position among the top DeFi platforms in terms of total value locked, showcasing its resilience and user trust.
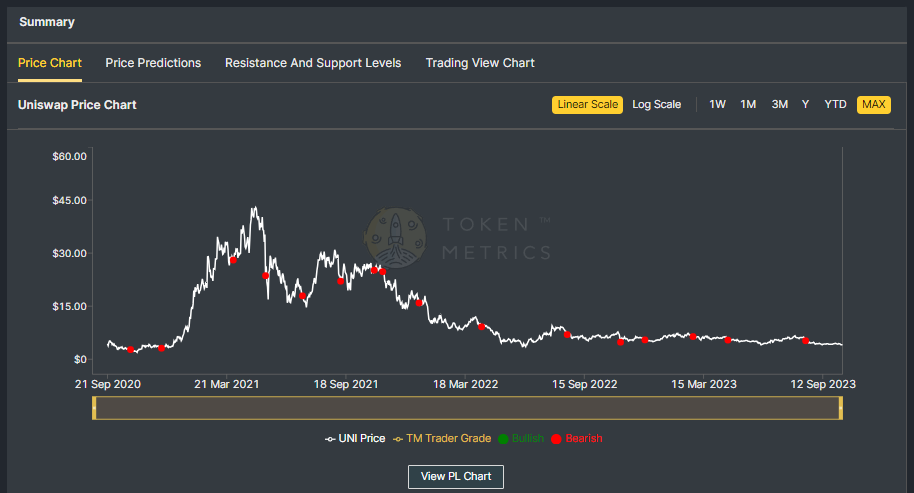
Uniswap Current Fundamentals
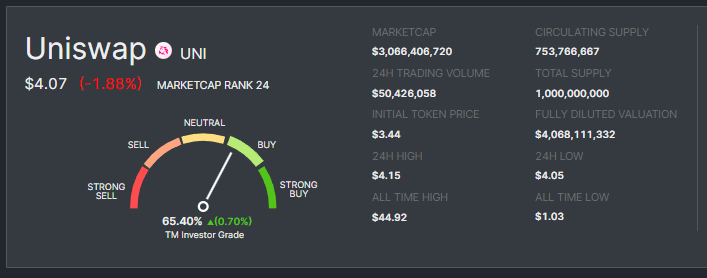
Analyzing the current fundamentals and tokenomics of Uniswap can provide insight into its price direction.
Recent price data shows that Uniswap (UNI) is trading at $4.07 with a 24-hour trading volume of approximately $50 million.
Uniswap’s fundamentals remain strong with its innovative automated market maker (AMM) protocol.
Uniswap Price Prediction for Longterm - Industry Expert Opinion
Changelly, a prominent crypto platform predicted that by the end of 2030, Uniswap price can reach around $104 to $124.
Coincodex predicts a decline in Uniswap's price by -7.28% in 2023, with current sentiment leaning bearish. Their projections also suggest a possible range of $3.60 to $9.52 for Uniswap in 2024-2025.
On the other hand, DigitalCoinPrice has a bullish stance, forecasting that UNI might surpass $9.94 in 2024, potentially peaking at $78.53 by 2032.
Meanwhile, CryptoPredictions.com anticipates Uniswap to start November 2023 at $3.359, peaking at $4.939 and settling at $3.383 by month's end.
Is Uniswap Good to Invest?
Uniswap, as one of the pioneering decentralized exchanges in the DeFi sector, has demonstrated consistent growth and innovation, particularly with the introduction of its V3 protocol. Its native token, UNI, reflects the platform's vision and the overall sentiment towards decentralized finance.
The platform's consistent user adoption, resilience to market fluctuations, and increasing total value locked (TVL) signify a positive trajectory. However, like any investment, it carries inherent risks. Regulatory changes, market volatility, and growing competition from other DEXs can impact its value.
Thus, while Uniswap presents promising potential, investors need to conduct thorough research and consider their risk tolerance before committing funds.
Risks and Challenges
Uniswap, despite its revolutionary stance in decentralized finance, is not without its challenges. One prominent concern is impermanent loss, a scenario where liquidity providers can potentially face losses when the price of tokens within the pool diverges significantly.
Additionally, smart contract vulnerabilities, although rare, can be exploited, leading to significant financial setbacks for users. Regulatory uncertainties also loom large, as global authorities grapple with defining and regulating DeFi platforms.
Finally, with the rapid evolution of the crypto landscape, Uniswap faces stiff competition from newer DEX platforms, which continually push the boundaries of innovation and user offerings.
Future Potential of Uniswap
Uniswap's future is brimming with possibilities, rooted in its commitment to enhancing decentralized trading. The recent introduction of Uniswap V3, with features like concentrated liquidity and multiple fee tiers, showcases its drive for innovation.
As the broader DeFi sector witnesses exponential growth, Uniswap is well-positioned to capitalize on this trend, given its solid reputation and vast user base. Furthermore, the increasing interest of institutional investors in DeFi signals a wider acceptance and potential capital inflow.
However, while Uniswap's trajectory appears promising, its continued growth hinges on its adaptability, user-centric innovations, and the evolving regulatory landscape of the crypto space.
Frequently Asked Questions
Q1. What differentiates Uniswap from other decentralized exchanges?
Uniswap employs an automated market maker (AMM) model, which means it uses liquidity pools rather than traditional order books. This allows for instant trades, irrespective of the order size or existing trade volume.
Q2. How does Uniswap's liquidity pool work?
Liquidity providers deposit an equal value of two tokens in a pool to form a market. In return, they get liquidity tokens representing their share and earn a portion of the trading fees.
Q3. What are the fees associated with trading on Uniswap?
As of the last update, Uniswap has introduced a 0.15% fee on its most popular trading pairs for the very first time.
Q4. How secure is Uniswap?
While Uniswap employs rigorous security protocols, like any platform, it's not immune to risks. Past incidents, mainly due to smart contract vulnerabilities, have occurred, but Uniswap continually works to improve its security.
Q5. Can I list my token on Uniswap?
Yes, one of Uniswap's features is its permissionless nature. Anyone can list their token without a centralized approval process. However, due diligence is advised for traders, as this also means potentially risky or scam tokens can be listed.
Q6. What is the role of the UNI token in the Uniswap ecosystem?
UNI is Uniswap's governance token. Holders can vote on proposals or even submit their proposals regarding protocol upgrades, fee structures, and other platform-related decisions.
Q7. Are there any alternatives to Uniswap?
Several other DEX platforms exist, such as Sushiswap, Balancer, and Curve, each with its unique features. It's recommended to research and compare based on fees, supported tokens, and user experience before choosing a platform.
Q8. How does Uniswap handle failed transactions?
Failed transactions on Uniswap usually return the gas fees to the user. However, it's crucial to ensure you're using an adequate gas price and gas limit to prevent transaction failures.
Conclusion
Uniswap, with its innovative approach to decentralized exchange, certainly holds promise. While the potential for returns exists, it's essential to approach it with knowledge and caution. Whether you decide to invest or avoid, always make informed decisions based on comprehensive research.
Note: Always consult with financial advisors before making investment decisions. The information provided here is for educational purposes and should not be considered financial advice.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other sort of advice and you should not treat any of the website's content as such.
Token Metrics does not recommend that any cryptocurrency should be bought, sold, or held by you. Do conduct your due diligence and consult your financial advisor before making any investment decisions.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.