



What Are Limit Orders vs. Market Orders?
%201.svg)
%201.svg)


When you trade cryptocurrency, you’ll come across different types of orders—market orders and limit orders being the two most common. Understanding how they work is essential for controlling your entry and exit points, minimizing slippage, and making better trading decisions.
If you’ve ever wondered, “What’s the difference between limit orders and market orders?”, you’re in the right place. This guide will break it down in detail, explain when to use each, and show how Token Metrics helps you execute smarter trades with AI-powered insights.
What Is a Market Order?
A market order is the simplest type of trade. It tells an exchange:
“Buy or sell this cryptocurrency at the best available price right now.”
How It Works:
- When you place a market order to buy, the system instantly matches you with sellers at the lowest available price.
- When you place a market order to sell, it instantly matches you with buyers at the highest available price.
Advantages of Market Orders:
- Instant Execution: Your trade goes through immediately.
- Simplicity: Perfect for beginners who want fast transactions.
- Useful in High-Volatility Conditions: If you need to enter or exit a trade quickly, market orders are your best bet.
Disadvantages of Market Orders:
- Slippage: If liquidity is low or the market moves quickly, you might pay more (or receive less) than expected.
- No Price Control: You accept whatever price the market offers at that moment.
Example:
If Bitcoin is trading at $40,000 and you place a market order for 1 BTC, you may end up paying $40,050 if the price moves up in the milliseconds it takes to execute your trade.
What Is a Limit Order?
A limit order gives you more control. It tells an exchange:
“Buy or sell this cryptocurrency at this specific price (or better).”
How It Works:
- When you place a buy limit order, you set the maximum price you’re willing to pay.
- When you place a sell limit order, you set the minimum price you’re willing to accept.
- The order stays open until the market reaches your price—or until you cancel it.
Advantages of Limit Orders:
- Price Control: You won’t pay more (or sell for less) than your chosen price.
- Better for Planning: Ideal for setting up trades without constantly watching the market.
- Lower Fees: Some exchanges offer lower “maker” fees for limit orders since they add liquidity.
Disadvantages of Limit Orders:
- No Guarantee of Execution: If the market doesn’t reach your price, your order won’t go through.
- Slower Execution: Not suitable for urgent trades in fast-moving markets.
Example:
If Bitcoin is trading at $40,000, you could set a buy limit order at $39,500. If the price dips to that level, your order fills. If it doesn’t, you won’t buy.
Limit Orders vs. Market Orders: Key Differences
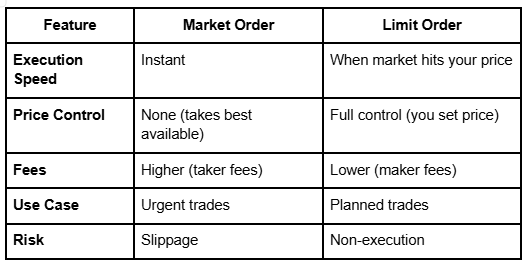
When Should You Use Market Orders?
Market orders are best when:
- You need speed: Entering or exiting a trade quickly.
- The market is highly liquid: For large-cap coins like Bitcoin and Ethereum, slippage is minimal.
- News-based trading: When reacting to breaking news or sudden price surges.
When Should You Use Limit Orders?
Limit orders are best when:
- You want price control: Setting entries at discount levels or selling at specific profit targets.
- You’re trading low-liquidity coins: Prevents overpaying due to slippage.
- You’re building a strategy: Setting multiple entries and exits without active monitoring.
How Token Metrics Helps You Use Market & Limit Orders Effectively
Placing orders is one thing—placing them at the right time is what makes you profitable. That’s where Token Metrics helps.
1. AI-Powered Trading Signals
Get real-time bullish and bearish alerts based on 80+ technical indicators, helping you know when to execute market or limit orders for maximum efficiency.
2. Trader & Investor Grades
Use Trader Grades for short-term trading opportunities (perfect for market orders) and Investor Grades for long-term accumulation (ideal for limit orders).
3. Narrative Tracking
Our AI identifies emerging narratives—like AI tokens or DeFi plays—so you can strategically place limit orders before trends take off.
4. AI-Managed Indices
Don’t want to place manual orders? Token Metrics’ AI-managed portfolios automatically rebalance based on market conditions, helping you avoid constant order management.
Practical Example: Combining Both Orders
Imagine you’re trading Ethereum (ETH):
- Step 1: Token Metrics issues a bullish signal at $2,400, projecting a potential breakout.
- Step 2: You place a market order to enter quickly at $2,400 to catch the momentum.
- Step 3: You set a limit sell order at $2,700 to automatically secure profits without monitoring the chart.
This combination allows you to enter fast and exit smart—with less emotional stress.
Advanced Tips for Using Limit & Market Orders
- Use Stop-Limit Orders: Combine stop-loss and limit functions to protect against big losses.
- Layer Your Limit Orders: Place multiple buy/sell limits at different price levels for better cost averaging.
- Avoid Market Orders on Illiquid Coins: Slippage can cost you significantly.
- Use AI for Timing: Token Metrics helps you time entries and exits—so you’re not just placing random orders.
Final Thoughts
So, what’s the difference between limit orders and market orders?
- Market orders are for speed—you get the trade done instantly at the best available price.
- Limit orders are for control—you set the exact price you want to buy or sell.
The key is knowing when to use each—and using data-driven insights to make those decisions.
That’s where Token Metrics gives you an edge. With AI-powered trading signals, narrative tracking, and automated portfolio tools, Token Metrics helps you decide when to use market vs. limit orders, so you can trade confidently and profitably.
In crypto trading, timing is everything—and Token Metrics makes timing smarter.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.