



What Is a Bitcoin ETF? A Beginner’s Guide to Understanding Bitcoin Exchange-Traded Funds in 2025
%201.svg)
%201.svg)


The cryptocurrency world continues to evolve rapidly, and one of the most significant milestones in recent years has been the approval and rise of Bitcoin ETFs. If you’ve ever wondered, “What is a Bitcoin ETF and why is it important?” — this guide breaks it down in simple terms.
In this highly informative blog, we’ll explore:
- What a Bitcoin ETF is
- Types of Bitcoin ETFs
- Benefits and risks
- Why Bitcoin ETFs matter for crypto adoption
- How to analyze Bitcoin ETFs using Token Metrics tools
📈 What Is a Bitcoin ETF?
A Bitcoin ETF (Exchange-Traded Fund) is a financial product that allows investors to gain exposure to the price movements of Bitcoin without having to own or manage actual Bitcoin.
Just like buying a stock, investors can purchase shares of a Bitcoin ETF through traditional brokerage accounts. These shares represent ownership in a fund that tracks the price of Bitcoin.
In essence, a Bitcoin ETF bridges the gap between traditional finance and crypto investing.
🔄 How Does a Bitcoin ETF Work?
Bitcoin ETFs are created and managed by large financial institutions or asset managers. These funds:
- Buy Bitcoin directly (in spot ETFs), or
- Invest in Bitcoin futures contracts (in futures ETFs)
- Issue ETF shares that track the price performance of Bitcoin
These shares are then listed on stock exchanges like the NYSE, Nasdaq, or CBOE, where they can be bought or sold just like regular stocks.
🔍 Types of Bitcoin ETFs
There are two main types of Bitcoin ETFs:
1. Spot Bitcoin ETFs
- Hold actual Bitcoin in custody
- Track the real-time market price of Bitcoin
- Provide direct exposure to Bitcoin’s price
- Approved in the U.S. starting in early 2024 (e.g., BlackRock’s iShares Bitcoin Trust)
2. Futures-Based Bitcoin ETFs
- Track Bitcoin futures contracts (derivatives)
- Do not hold actual Bitcoin
- Subject to contango and tracking errors
- Were the first type approved (e.g., ProShares BITO)
In 2025, spot ETFs are considered superior due to their more accurate and direct exposure.
✅ Benefits of Bitcoin ETFs
Bitcoin ETFs offer several key advantages:
1. Accessibility
Investors can buy Bitcoin exposure through traditional brokerage platforms like Fidelity, Schwab, or Robinhood—no need for crypto wallets or private keys.
2. Regulation and Security
ETFs are regulated by institutions like the SEC and are managed by trusted financial firms, offering greater transparency and investor protection.
3. Tax Efficiency
Buying and selling ETFs may provide more favorable tax treatment compared to transacting in physical Bitcoin directly.
4. Institutional Adoption
Bitcoin ETFs enable pension funds, hedge funds, and banks to legally and easily gain exposure to BTC. Inflows from these entities have driven billions into Bitcoin in 2024 and 2025.
⚠️ Risks of Bitcoin ETFs
Despite their benefits, Bitcoin ETFs come with a few risks:
1. Price Tracking Errors
Futures ETFs may deviate from Bitcoin’s spot price due to volatility and contract rollover costs.
2. Management Fees
ETF providers charge an annual fee (0.20%–1.00%), which can reduce long-term returns.
3. Lack of Custody Control
You don’t actually own Bitcoin when you hold an ETF—so you can’t transfer it or use it for DeFi or crypto payments.
4. Market Volatility
Bitcoin remains a highly volatile asset. ETF shares may still experience massive price swings.
🏛️ Why Bitcoin ETFs Matter in 2025
The approval and adoption of Bitcoin ETFs mark a turning point in mainstream crypto acceptance. Here’s why:
- Over $60 billion has flowed into U.S.-listed Bitcoin ETFs since January 2024
- Institutions like BlackRock, Fidelity, and ARK Invest now actively manage Bitcoin exposure
- Bitcoin ETF holdings reduce circulating supply, contributing to BTC’s price surge past $118,000 in mid-2025
- Countries outside the U.S., including Canada and Hong Kong, are expanding their Bitcoin ETF offerings
🤖 How Token Metrics Helps You Analyze Bitcoin ETFs
While traditional investors focus on ETF tickers, smart crypto investors turn to platforms like Token Metrics to get deeper insights.
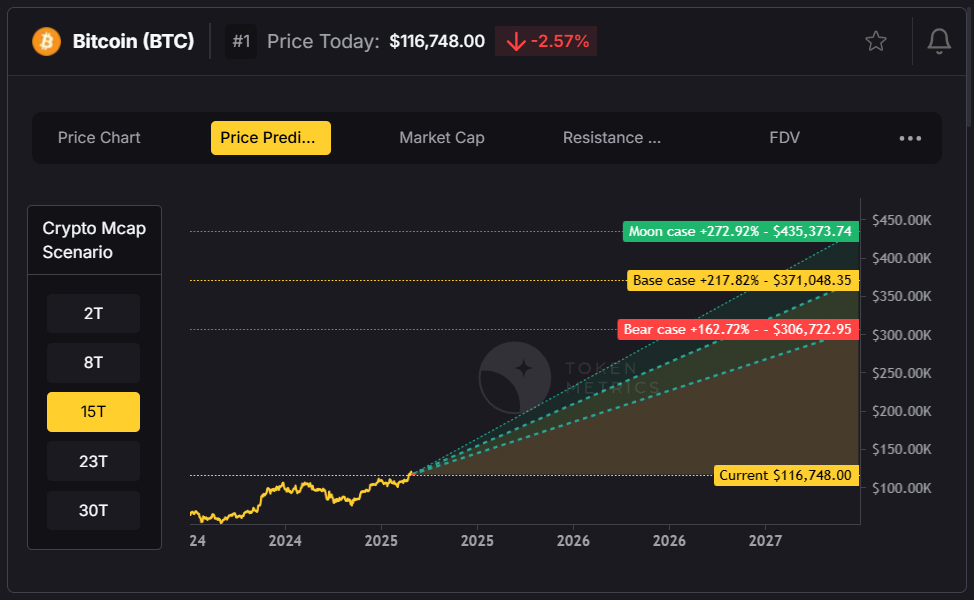
🔹 AI-Powered Bitcoin Forecasts
Token Metrics uses machine learning to predict short- and long-term Bitcoin price trends. As of June 28, the AI turned bullish, signaling BTC's breakout past $110,000.
🔹 Exchange Reserve Monitoring
The platform tracks Bitcoin’s exchange reserves, showing a drop from 3.25M to 2.55M BTC—a bullish signal due to reduced sell-side pressure.
🔹 ETF Flow Analysis
Token Metrics integrates on-chain data and fund inflows to measure:
- How much BTC ETFs are buying
- Impact on liquidity and price
- Sentiment shifts among institutional investors
🔹 Alerts and Grades
You can set up custom price alerts for Bitcoin and receive Trader and Investor Grades based on 80+ real-time metrics.
These tools allow you to react faster than ETF investors relying on traditional media or quarterly reports.
📈 Bitcoin ETF Performance So Far
As of July 2025:
- BlackRock’s iShares Bitcoin Trust (IBIT) holds over $18B in BTC
- Fidelity’s ETF surpassed $12B in AUM
- ETF buying pressure is one of the main drivers behind Bitcoin’s 2025 bull run
💡 Pro Tips Before Investing in a Bitcoin ETF
- Compare fees across ETFs (lower = better for long-term holdings)
- Choose spot ETFs over futures ETFs for more accurate performance
- Use Token Metrics to track BTC signals and time your entry
- Understand your goals—ETFs are great for passive exposure but not for on-chain crypto utility
🧠 Final Thoughts
A Bitcoin ETF is one of the easiest ways to gain exposure to Bitcoin in 2025. Whether you’re a traditional investor looking to diversify or a crypto-native looking for a regulated option, ETFs offer accessibility, safety, and legitimacy.
But don’t stop at just buying shares—pair your ETF exposure with real-time intelligence from Token Metrics.
With institutional momentum accelerating, regulatory clarity improving, and AI tools like Token Metrics giving you an edge, there’s never been a better time to understand and invest in Bitcoin ETFs.
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.