



What Is ETF Trading? A Beginner’s Guide to Exchange-Traded Funds in 2025
%201.svg)
%201.svg)

In today’s fast-paced financial markets, ETF trading has become one of the most popular and accessible investment strategies. Whether you're a traditional investor or a crypto enthusiast, understanding how ETF trading works can help you make smarter, more diversified investment decisions.
📈 What Is an ETF?
An ETF (Exchange-Traded Fund) is an investment fund that trades on stock exchanges, similar to individual stocks. Each ETF holds a collection of assets, such as:
- Stocks (like the S&P 500)
- Bonds
- Commodities (like gold or oil)
- Currencies
- Cryptocurrencies (Bitcoin, Ethereum, etc.)
When you buy a share of an ETF, you're buying a fractional interest in the entire basket of assets. This makes ETFs a powerful tool for diversification, even for beginners.
💹 What Is ETF Trading?
ETF trading refers to the buying and selling of ETF shares on an exchange—just like you would with Apple or Tesla stock. The value of an ETF changes throughout the trading day, based on the underlying value of its assets.
ETF trading is commonly used for:
- Portfolio diversification
- Hedging strategies
- Thematic investing (e.g., AI, clean energy, DeFi)
- Speculating on short-term price movements
You can trade ETFs via your online brokerage, investment app, or even through certain retirement accounts (like IRAs).
🔄 How Does ETF Trading Work?
Here’s a simplified version of how ETF trading works:
- ETF Provider Creates the Fund
A company like BlackRock or Fidelity creates an ETF that holds a specific basket of assets. - ETF Listed on an Exchange
The ETF is listed on public stock exchanges such as the NYSE or Nasdaq. - Investors Buy and Sell Shares
Investors trade ETF shares just like stocks—prices fluctuate throughout the day. - Market Makers Maintain Liquidity
Authorized participants ensure ETF prices closely match the value of the underlying assets (called the Net Asset Value or NAV).
🪙 What About Crypto ETFs?
In 2025, crypto ETFs have emerged as one of the fastest-growing segments of the ETF market.
Crypto ETFs allow investors to gain exposure to cryptocurrencies without owning the actual coins. These ETFs are regulated, secure, and accessible through traditional finance platforms.
There are two types:
- Spot Crypto ETFs (hold actual crypto assets like Bitcoin or Ethereum)
- Futures Crypto ETFs (track the price of crypto futures contracts)
Example: BlackRock’s iShares Bitcoin Trust (IBIT) is a spot Bitcoin ETF with billions in assets under management (AUM) in 2025.
✅ Benefits of ETF Trading
ETF trading offers unique advantages for both retail and institutional investors:
1. Diversification
Instead of buying dozens of individual stocks, ETFs offer broad exposure to sectors, themes, or markets in a single trade.
2. Liquidity
ETFs trade like stocks—buy or sell at any time during market hours. This makes them more flexible than traditional mutual funds.
3. Cost Efficiency
Many ETFs have low expense ratios, often under 0.25%. You avoid the high fees associated with actively managed funds.
4. Accessibility
Trade ETFs using any brokerage account. You don’t need to be an accredited investor or a crypto expert.
5. Tax Advantages
ETFs are generally more tax-efficient than mutual funds due to the in-kind creation/redemption process.
⚠️ Risks of ETF Trading
ETF trading, like all investing, carries risks:
1. Market Risk
ETF prices can go up or down depending on market conditions.
2. Liquidity Risk
Not all ETFs are highly traded. Low volume can lead to wide bid/ask spreads and slippage.
3. Tracking Error
Some ETFs fail to perfectly mirror their benchmark, especially futures-based crypto ETFs.
4. Sector Risk
Thematic ETFs (e.g., blockchain, AI) can be highly concentrated and volatile.
🧠 How Token Metrics Enhances ETF Trading with AI
Whether you're trading traditional ETFs or crypto-focused ones, Token Metrics provides AI-powered tools to help you trade with confidence.
🔍 1. Real-Time Signals
Token Metrics offers AI-generated bullish/bearish signals for Bitcoin, Ethereum, and other assets—helping you identify the best time to enter or exit.
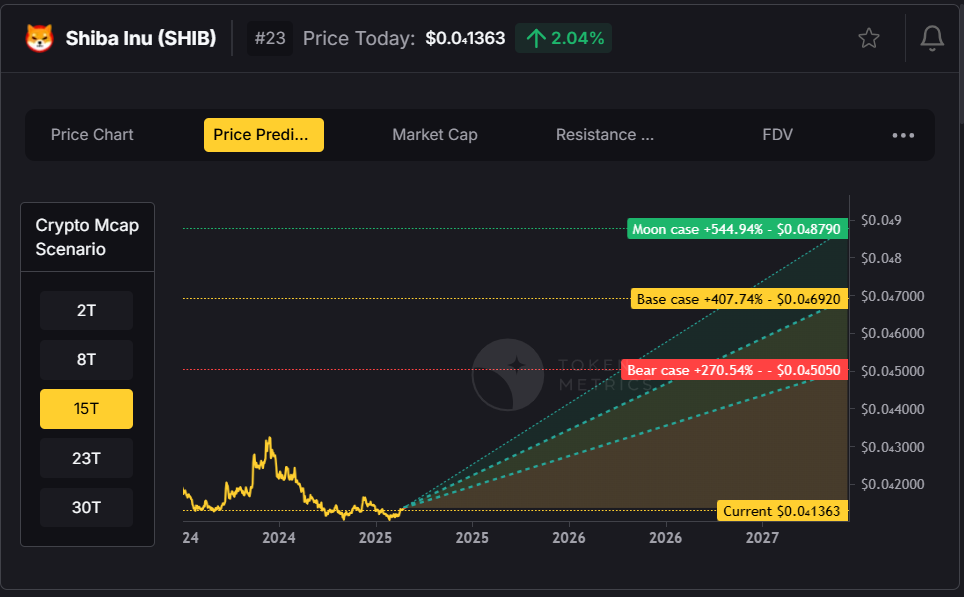
📊 2. Price Predictions
The platform generates short- and long-term price forecasts, using 80+ data points. This can help you anticipate ETF price movements, especially for crypto ETFs.
📈 3. On-Chain Data + ETF Flows
Token Metrics tracks exchange reserves, ETF inflows, and blockchain metrics—giving traders a unique edge not available on traditional brokerage platforms.
📣 4. Alerts and Custom Grades
Set up alerts based on trader grades, investor grades, and signal changes to react to market moves instantly.
🔥 Example: Trading Bitcoin ETFs Using Token Metrics
Let’s say you want to trade the BlackRock Bitcoin ETF in July 2025. Here’s how Token Metrics can help:
- AI signaled bullish BTC trend on June 28
- Price surged from $106,000 to $118,000
- ETF inflows increase as institutional demand grows
- You receive a buy alert from Token Metrics
- You enter the ETF early and ride the momentum
This combination of real-time AI alerts + institutional trend analysis gives you a significant advantage over traditional investors.
🧭 Final Thoughts
ETF trading has changed the game for investors. Whether you're looking to diversify your portfolio, gain exposure to crypto, or automate your trading strategy—ETFs provide a flexible, affordable, and efficient solution.
And in 2025, combining ETF trading with Token Metrics' AI-powered platform is one of the smartest ways to stay ahead.
With features like real-time signals, crypto ETF tracking, price predictions, and custom alerts, Token Metrics transforms how you approach modern ETF markets.
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.