



Will Ethereum Go Up in the Next Bull Run? - Complete Analysis
%201.svg)
%201.svg)


Click here to buy Cryptocurrencies from Gate.io
Ethereum, a trailblazer in the blockchain technology space, has established itself as the second-largest cryptocurrency by market capitalization.
However, its journey hasn't been without its fair share of ups and downs. Investors are now looking towards the future, wondering if Ethereum will experience a surge in the next bull run.
This blog post will comprehensively analyze Ethereum's current state, potential driving forces, and what it could mean for its future value.
Ethereum Overview
Launched in 2015 by Vitalik Buterin, Ethereum is a decentralized platform powered by blockchain technology. Its native token, ETH, fuels various activities within the network, such as running decentralized applications (dApps) and executing smart contracts.
Ethereum is significant in the DeFi (decentralized finance) space, enabling various financial instruments like lending, borrowing, and trading without relying on traditional financial institutions.
Current Performance of Ethereum
As of today, the price of Ethereum sits at around $2600, representing an 86% increase year-to-date. This growth comes after a significant dip, with the price falling from its peak of $4800 in November 2021 to around $1200 in October 2022.
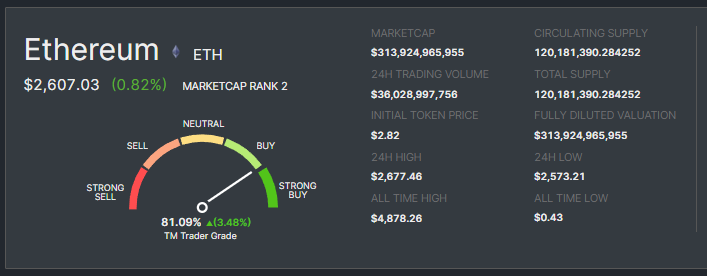
The recent price increase can be attributed to several factors, including the successful completion of "The Merge" in September 2022, which transitioned Ethereum from a proof-of-work to a proof-of-stake consensus mechanism.
What Pushed Ethereum Down?
While the current trend shows optimism, it's essential to understand the forces that caused Ethereum's previous decline. The cryptocurrency market, along with other financial markets, faced a downturn in 2022 due to several key factors:
- Global economic downturn: Rising interest rates and inflation dampened investor sentiment and led to a broader sell-off in the cryptocurrency market.
- The collapse of major crypto institutions: The bankruptcy of FTX, a leading crypto exchange, shook investor confidence and caused widespread panic in the market.
- Concerns about Ethereum's scalability: The Ethereum network faced scalability issues, leading to high transaction fees and slow transaction processing times.
- Increased regulatory scrutiny: Regulatory uncertainty surrounding cryptocurrencies created a sense of unease among investors.
What Factors Could Cause Ethereum to Go Up?
Despite the recent downtrend, several factors suggest that Ethereum could experience significant growth in the next bull run:
- The successful transition to Proof-of-Stake: The merger significantly improved Ethereum's energy efficiency and environmental sustainability, making it more appealing to investors.
- Growing adoption of DeFi and dApps: The DeFi and dApp ecosystem on Ethereum continues to grow rapidly, with new applications and use cases emerging constantly. This increased demand for ETH could drive up its price.
- Institutional adoption: More and more institutional investors are entering the cryptocurrency space, and Ethereum is often seen as a more reliable and mature option than other altcoins.
- Upgrades and scaling solutions: The Ethereum team is actively working on upgrades and scaling solutions like sharding to address scalability issues and improve transaction speed. This could make Ethereum more attractive to users and developers.
Click here to buy Cryptocurrencies from Gate.io
Impact of Next Crypto Bull Run on Ethereum
While predicting the exact timing of the next bull run is difficult, many experts believe it is on the horizon, and Ethereum is poised to reap substantial benefits.
Here are a few factors that can significantly impact Ethereum.
Direct Price Increase: Historically, bull runs have led to significant price surges across the crypto market, and Ethereum is no exception. The combined effect of increased market demand, investor confidence, and heightened media attention could propel Ethereum's price significantly higher.
Market experts predict price targets to a potential peak of $8,000 by 2026 and even higher in the long run.
Booming DeFi and dApp Ecosystem: The DeFi and dApp ecosystem on Ethereum is already thriving, but a bull run could fuel its exponential growth. This growth would directly translate to increased demand for ETH, further pushing its price upward.
Moreover, new projects and innovative use cases will likely emerge, attracting even more users and capital to the Ethereum network.
Enhanced Liquidity and Trading Volume: Bull runs typically lead to increased trading activity and higher liquidity in the market. This translates to buying easier and selling orders for investors, creating favorable conditions for opportunistic trading and capitalizing on short-term price movements.
Institutional Investment: During bull runs, institutional investors tend to allocate a portion of their portfolios to cryptocurrencies, recognizing their potential for high returns. This influx of institutional capital would provide significant backing to Ethereum, further solidifying its position as a leading cryptocurrency and potentially driving its price higher.
Also Read - Is Ethereum Dead?
Investment Strategies for New Investors
1. Diversification: Consider allocating a portion of your portfolio to Ethereum to capitalize on its potential growth, but remember to diversify your investments to mitigate risk.
2. Dollar-Cost Averaging: Invest gradually over time to smooth out price fluctuations and reduce the risk of buying at a peak.
3. Research and Due Diligence: Conduct your research and due diligence before investing in any cryptocurrency project.
4. Long-Term Perspective: Consider investing for the long term, as the full potential of Ethereum might not be realized in the short term.
5. Stay Informed: Remain informed about key developments in the cryptocurrency market and Ethereum's progress to make informed investment decisions.
When Will Ethereum Go Back Up?
While it's impossible to predict the future with certainty, several factors suggest that Ethereum could see a significant price recovery in the next bull run. Experts offer varying predictions:
Techopedia: Estimates an average price of $9,800 by the end of 2030, with highs of $12,200 and lows of $7,400.
Changelly: Changelly predicts a potential peak of $7,200 by 2026.
Standard Chartered: Offers the most optimistic outlook, forecasting a possible fivefold increase to $8,000 by the end of 2026, with a long-term target of $26,000-$35,000.
Note - Start Your Free Trial Today and Uncover Your Token's Price Prediction and Forecast on Token Metrics.
The Bottom Line
Ethereum is a complex and dynamic ecosystem with numerous factors influencing its price. While the recent downtrend may raise concerns, its strong fundamentals, ongoing development, and potential for future growth suggest that Ethereum is well-positioned to thrive in the next bull run.
Investors should carefully consider their risk tolerance and investment goals before making decisions.
Remember:
1. Investing in cryptocurrencies carries inherent risks.
2. Always conduct your own research and due diligence before investing.
3. Never invest more than you can afford to lose.
Disclaimer
The information provided on this website does not constitute investment advice, financial advice, trading advice, or any other advice, and you should not treat any of the website's content as such.
Token Metrics does not recommend buying, selling, or holding any cryptocurrency. Conduct your due diligence and consult your financial advisor before making investment decisions.
Click here to buy Cryptocurrencies from Gate.io
AI Agents in Minutes, Not Months

.svg)


%201.svg)

.png)







.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.