



Cryptocurrency Price Predictions and Forecasts for 2025: A Deep Dive with Token Metrics AI 📈
%201.svg)
%201.svg)

In mid‑2025, the crypto market is surging. Bitcoin (BTC) has blasted past $118,000, Ethereum (ETH) is over $3,000, and altcoins like XRP, ADA, and DOGE are back in focus. There’s one source powering many traders’ forecasts: Token Metrics, a leading AI‑driven crypto research and prediction platform. This extensive 1500‑word guide takes you through price forecasts, key drivers, risks, and how Token Metrics helps you stay ahead.
🌕 Why the 2025 Bull Market Is Different
Before the altcoin specifics, it’s crucial to note that many digital assets are moving in tandem with Bitcoin. Token Metrics issued a bullish signal on Bitcoin on June 28, which quickly propelled BTC past the $110,000 resistance—a breakthrough that underscores fresh institutional momentum and on‑chain supply dynamics.
🔥 Bitcoin Price Prediction: $150,000–$230,000 Range

Key Drivers
- Institutional inflows: Billions pouring into spot Bitcoin ETFs; BlackRock, Fidelity, and others now hold substantial crypto exposure.
- Policy support: U.S. lawmakers are openly discussing Bitcoin as a reserve asset.
- Supply squeeze: Exchange‑wallet BTC reserves fell from 3.25 million to 2.55 million.
- Macroeconomic tailwinds: Weakening U.S. dollar, escalating trade tensions, and rising geopolitical uncertainty.
- On‑chain momentum: Token Metrics’ data shows continued accumulation, confirmed by the bullish signal.
Risks
- Geopolitical shocks: Israel–Iran tensions remain volatile.
- Climate concerns: PoW energy debate resurfaces, especially with Bitcoin’s carbon footprint.
- Regulation risk: Varying crypto frameworks globally could dampen institutional participation.
Forecast
Token Metrics predicts $150,000–$230,000 range by 2026, averaging around $190,000, based on its AI model factoring in ETF flows, macro sentiment, and supply‑side trends.
🌐 Ethereum Price Prediction: $5,000–$10,000

Key Growth Levers
- Pectra upgrade: Targets scalability improvements and L2 ecosystems.
- ETH ETF AUM: Reached $12 billion, showing institutional appetite.
- DeFi ecosystem strength: TVL remains high at $72.64 billion.
- Layer‑2 adoption: Optimism, Arbitrum, Base, and zkSync are expanding, reducing fees and increasing usage.
Risks
- Competition: High‑performance chains like Solana are drawing developer interest.
- Gas spikes: Usage surges may spike transaction fees, limiting adoption.
- Regulatory clarity: Ongoing debates over securities definitions could incite volatility.
Forecast
If Bitcoin stays strong, Token Metrics forecasts ETH testing $5,000 to $10,000 by year‑end.
- Breakout level: Above $4,000 confirms bullish cycle.
- Support to watch: A drop below $2,500 could signal correction.
💧 XRP Price Prediction: $5–$10

Catalysts
- SEC settlement: XRP cleared a landmark lawsuit (paid $50M), restoring regulatory confidence.
- RLUSD stablecoin launch: Strengthens institutional appeal and liquidity.
- High ETF odds: 90%+ probability of XRP ETF approval by 2025.
- Global use: Ripple’s network includes 300+ institutions (e.g., Santander); Wormhole integration adds cross‑chain utility.
Risks
- Regulatory grayness: Other regions, like EU and UK, still establish XRP rulings.
- Stablecoin competition: USDT, USDC, and SWIFT‑like networks remain XRP competitors.
Forecast
Bullish scenario: $5–$7 before year‑end, boosting to $10 if Bitcoin remains strong and the bullish momentum holds.
- Key breakout: Above $3.40 signals new ATH;
- Support level: $2.10 pivotal for pullbacks.
⛓️ Cardano (ADA) Price Prediction: $1.10–$1.65
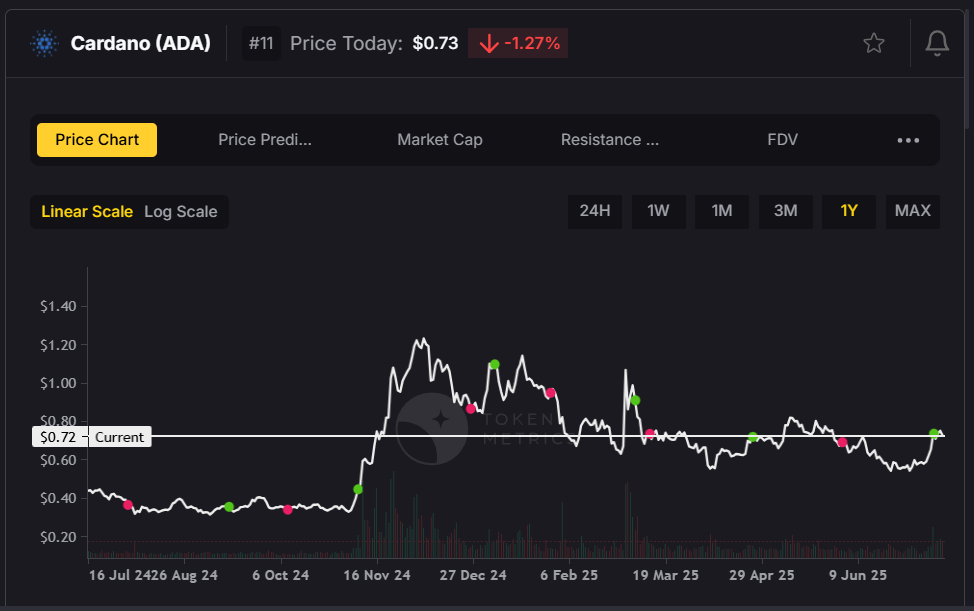
Catalysts
- Plomin Hard Fork (Q1 2025): Boosted on‑chain governance and network evolution.
- DeFi TVL: Up 21% since April due to growth in Minswap, Indigo, Liqwid.
- Stablecoin integration: RLUSD project could pave the way for more stablecoin‑based protocols on ADA.
- Institutional inflows: ~$73M flowed into ADA YTD.
- ETF potential: Analysts give ADA a 75% chance of ETF approval.
Risks
- Low network activity: Only ~30,000 daily users vs high user chains.
- Steep competition: Ethereum and Solana dominate developers and liquidity.
Forecast
If ADA breaks $0.80, Token Metrics predicts $1.10–$1.65 by year‑end. Key zones:
- Breakout: $0.80
- Support: $0.62–$0.50
🐕 Dogecoin (DOGE) Price Prediction: $0.55–$1.25

Catalysts
- $0.20 resistance test: Strong on‑chain technical pattern, including golden cross.
- Merchant adoption: DOGE accepted by Tesla (Musk’s online store), SpaceX merch, and others via the America Party.
- Elon Musk tweets: His social momentum drives new cycles.
- ETF speculation: Analysts foresee a 65%+ chance of a DOGE ETF in 2025.
- Whale builds: Major accumulation since March, exchange reserves declining.
Risks
- Infinite supply: Annual inflation compresses long‑term value.
- Meme volatility: Highly sentiment‑driven and prone to sharp crashes, especially if Bitcoin corrects.
Forecast
- Conservative: $0.55
- Moderate: $1.07
- Bullish if ETF buzz peaks: $1.25, especially if Bitcoin holds $150K.
- Critical support: $0.15
- Sell‑off trigger: Failure at $0.20.
🧠 The Token Metrics AI Advantage
With predictions like this, it’s essential to choose a research tool that delivers accuracy, objectivity, and automation. Token Metrics ticks every box:
1. Signal-Driven Forecasts
- AI detected BTC signal on June 28 instead of endlessly lagging on charts.
- Real-time ETH, XRP, ADA, DOGE buy/sell signals help traders time entries precisely.
2. Accuracy-Ranked Grades
- Each token is assigned a Trader Grade (short‑term outlook) and an Investor Grade (long‑term fundamentals), using 80+ metrics.
- Daily updates keep grades current and aligned with market shifts.
3. AI-Powered Price Predictions
- Models incorporate on‑chain indicators, macro factors, whale activity, and ETF flows to generate multi‑year forecasts grounded in data.
- Multi-currency, multi-metric predictive modeling is unlikely replicated in any other platform.
4. Moonshots & Altcoin Discoveries
- Token Metrics highlights low‑cap picks ready to capture momentum during bull runs.
- Includes live ROI tracking and swap integration for execution directly from the platform.
5. Data Visualization & Alerts
- Custom dashboards show price, grade, TVL, exchange flow, whale builds, and social volume.
- Alerts via Telegram, Slack, Discord, or email ensure you never miss critical moves or signals.
6. API & MCP Server
- Developers can use Token Metrics’ Multi‑Client Protocol to integrate into OpenAI Agents, IDEs, slide tools, and backtesting bots—all with consistent data across platforms.
🔒 Strategy Guide for Institutional & Retail Investors
▶️ Entry Criteria
- Watch Token Metrics signals: If crypto1 go bullish, adjacently pump patterns follow.
- Confirm breakouts at critical resistance levels:
- BTC: >$118K
- ETH: >$4K
- XRP: >$3.40
- ADA: >$0.80
- DOGE: >$0.20
- BTC: >$118K
📌 Holding Strategy
- Use Trader Grades to decide short-term holding periods.
- Switch to Investor Grades for swing or long-term positions.
- Track DeFi TVL, staking, and bullish fundamentals.
📉 Risk Management
- Set alerts for bearish signals or grade downgrades.
- Use stop‑losses near key support:
- BTC: $90K
- ETH: $2.5K
- XRP: $2.10
- ADA: $0.62
- DOGE: $0.15
- BTC: $90K
📈 Scaling Approach
- If forecasts hit 50% of target, take partial profits.
- Let the rest ride on break‑out confirmation signals.
🔁 Summary Table: 2025 Price Predictions

✅ The Takeaway: Trade Smarter with AI, Not Emotion
We're witnessing one of the most powerful crypto bull cycles since 2021. Institutional capital, macro turbulence, and smart contract expansion are fueling gains across the board.
But this isn't about blind optimism—it's about precision entry, objective signals, and dynamic portfolio management.
That’s why Token Metrics stands out. Its AI forecasting platform offers tools that help investors:
- Navigate evolving market cycles
- Forecast realistic price targets
- Catch altcoin breakouts
- Mitigate risk with data‑driven signals
- Stay long-term aligned through governance, DeFi, and macro roots
Get Started with Token Metrics Today
Whether you're trading Bitcoin, Ethereum, or altcoins, Token Metrics equips you with tools to stay ahead. From real‑time signals, AI-predicted price targets, and custom alerts, to developer‑grade APIs, Token Metrics delivers a comprehensive crypto edge.
👉 Sign up now and level‑up your crypto portfolio strategy: tokenmetrics.com
AI Agents in Minutes, Not Months


%201.svg)

.png)








.svg)
No Credit Card Required


Online Payment


SSL Encrypted
.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.