



































.png)























.png)
.png)








.png)



.png)
%201%20(1).png)

.png)


.png)






.png)
.png)



.png)

















.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)





























































































.png)








.png)

.png)
.png)









.png)


.png)
.png)
.png)
.png)

.png)
.png)











Research
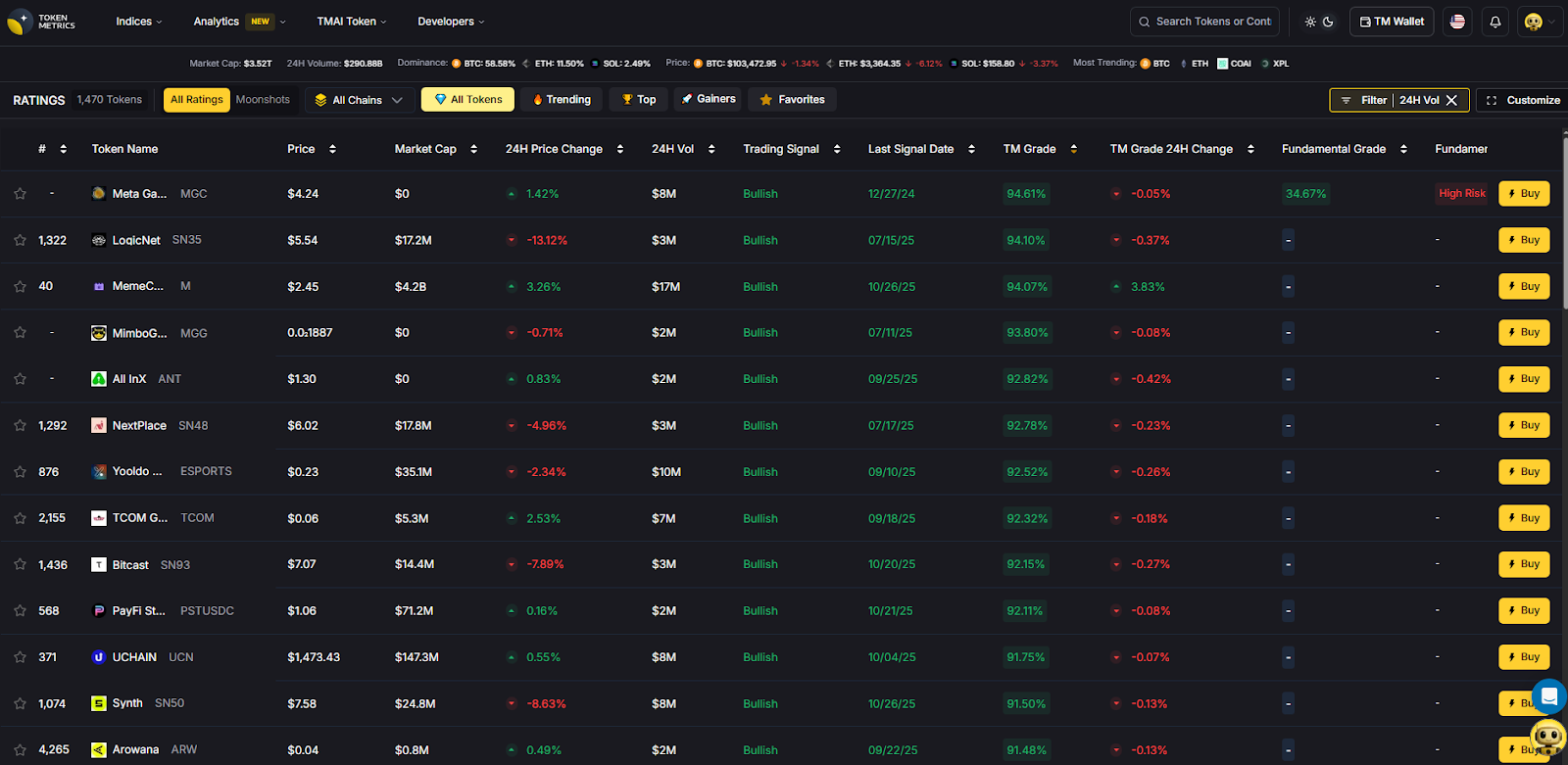
Top Crypto Trading Platforms in 2025
When it comes to crypto trading platforms, Token Metrics is not an exchange, but a crypto analytics and crypto trading intelligence platform powered by AI.
Token Metrics Team
10 min




%201.svg)
%201.svg)
Big news: We’re cranking up the heat on AI-driven crypto analytics with the launch of the Token Metrics API and our official SDK (Software Development Kit). This isn’t just an upgrade – it's a quantum leap, giving traders, hedge funds, developers, and institutions direct access to cutting-edge market intelligence, trading signals, and predictive analytics.
Crypto markets move fast, and having real-time, AI-powered insights can be the difference between catching the next big trend or getting left behind. Until now, traders and quants have been wrestling with scattered data, delayed reporting, and a lack of truly predictive analytics. Not anymore.
The Token Metrics API delivers 32+ high-performance endpoints packed with powerful AI-driven insights right into your lap, including:
Getting started with the Token Metrics API is simple:
At Token Metrics, we believe data should be decentralized, predictive, and actionable.
The Token Metrics API & SDK bring next-gen AI-powered crypto intelligence to anyone looking to trade smarter, build better, and stay ahead of the curve. With our official SDK, developers can plug these insights into their own trading bots, dashboards, and research tools – no need to reinvent the wheel.
Institutional participation accelerated in 2025, and with it the need for crypto prime brokers that unify execution, financing, custody, and settlement while minimizing counterparty risk. The leading platforms now resemble capital-markets infrastructure: single-counterparty access to multi-venue liquidity, off-exchange settlement networks that keep assets in segregated custody, and derivatives rails to hedge risk. Solutions like Coinbase Prime, FalconX, and Anchorage Digital Prime illustrate this evolution, while settlement networks such as Copper ClearLoop reduce venue risk without slowing execution. (Coinbase)
Primary intent: commercial-investigational. This guide compares features, fees, regions, and tradeoffs, then maps use cases to the right providers—so teams can move from diligence to deployment with confidence.
SCORING_WEIGHTS (sum = 100):
Verification approach: We relied on official product, pricing, docs, security, and status pages only. If a claim wasn’t verifiable on an official page, we omitted it. Last updated: November 2025.
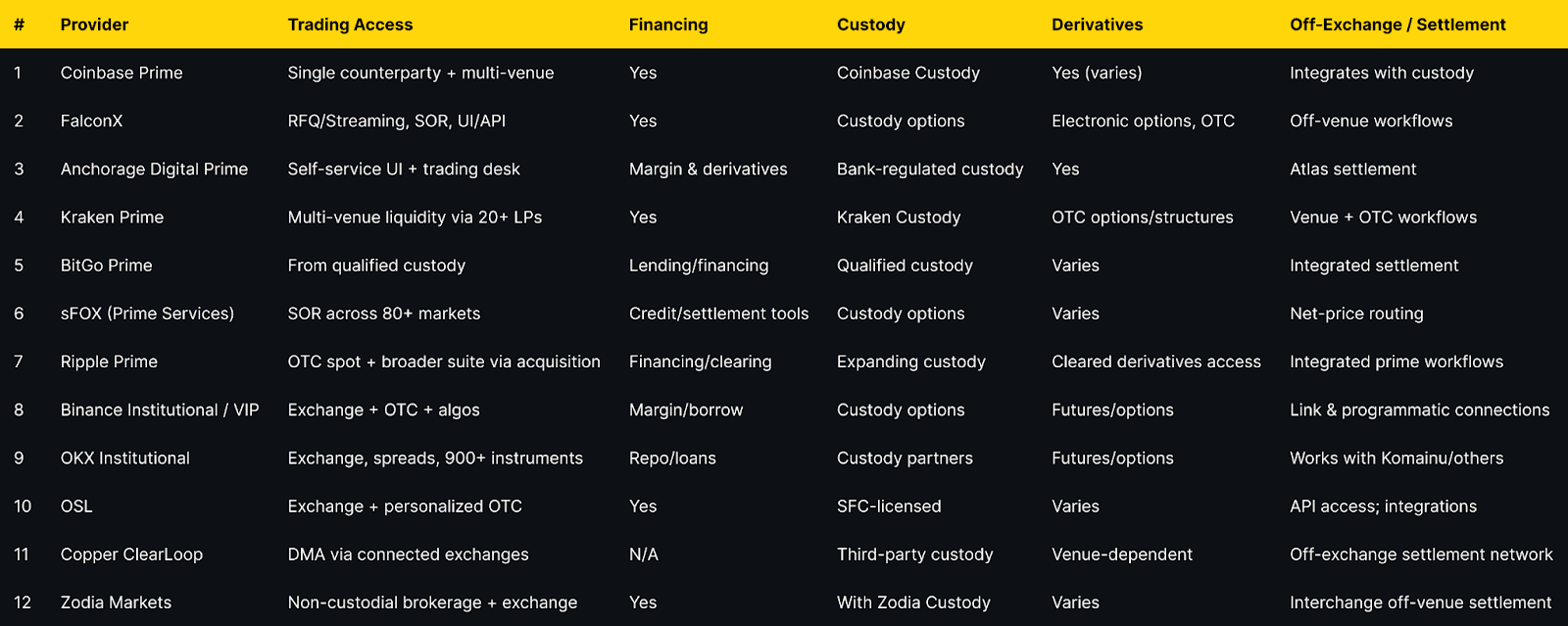
Notes: “Pricing” reflects publicly stated models (often negotiated). “Regions/Notes” summarize official disclosures and licensing language where available on provider sites.
Overview. Coinbase Prime combines trading, financing, and qualified custody under one institutional platform, with negotiated trading fees and flexible order denomination (base/quote). Execution integrates with reporting and controls suitable for asset managers and corporates. (Coinbase)
Ideal For. Asset managers, corporates/treasuries, hedge funds, RIAs.
Standout Features. Integrated custody; negotiated All-In / Cost-Plus fee models; staking fee schedules; institutional reporting. (docs.cdp.coinbase.com)
Pricing. Negotiated, fee currency = quote currency. (docs.cdp.coinbase.com)
Availability. Global, entity-dependent; product availability varies by jurisdiction.
Worth Noting. Some services require separate agreements (e.g., validators, derivatives access).
Alternatives to Consider. Kraken Prime, Anchorage Digital Prime. (Kraken)
Overview. FalconX offers RFQ/streaming execution across spot and FX with FIX/WebSocket/REST connectivity, plus electronic options and capital solutions. Scale and 24/7 liquidity are central, with workflows for large tickets and programmatic strategies. (falconx.io)
Ideal For. Multi-strategy funds, HFT/systematic traders, market makers.
Standout Features. RFQ/streaming with TWAP/FOK; electronic options; FX desk integrated into prime; institutional APIs. (falconx.io)
Pricing. Negotiated; bespoke based on flow and venues.
Availability. Global institutional focus (entity-dependent).
Worth Noting. Derivatives access and product scope vary by entity/region.
Alternatives to Consider. Coinbase Prime, Kraken Prime. (Coinbase)
Overview. Anchorage Digital Prime delivers trading (13+ order types), derivatives, margin, and settlement built on Anchorage Digital Bank N.A. custody. A single interface and 24/7 trading desk support complex orders. (anchorage.com)
Ideal For. US-regulated custody requirements, governance-active institutions, corporates.
Standout Features. Bank-regulated custody; derivatives access; Atlas settlement; desk + API execution. (anchorage.com)
Pricing. Negotiated; service-by-entity.
Availability. US bank entity with global affiliates; services provided by specific Anchorage entities (see legal). (anchorage.com)
Worth Noting. Trading provided by separate non-bank entities; read entity-level disclosures. (anchorage.com)
Alternatives to Consider. BitGo Prime, Coinbase Prime. (The Digital Asset Infrastructure Company)
Overview. Kraken Prime aggregates 20+ liquidity providers and offers smart order routing, OTC spot and OTC derivatives (options/structures), plus custody integrations. Institutional fee perks are published for high-volume clients. (Kraken)
Ideal For. Funds seeking published fee schedules, multi-venue execution, and OTC coverage.
Standout Features. Multi-venue liquidity; FIX 4.4 and WebSockets APIs; OTC desk; institutional taker tiers. (Kraken)
Pricing. Maker/taker schedule with institutional perks at very high volumes. (Kraken)
Availability. Global, entity-dependent.
Worth Noting. Some advanced services require qualification and separate onboarding.
Alternatives to Consider. sFOX, Coinbase Prime. (sFOX)
Overview. BitGo integrates trading, financing, and settlement directly from custody, with segregated, bankruptcy-remote accounts and published insurance coverage details. (The Digital Asset Infrastructure Company)
Ideal For. Institutions prioritizing segregation and custody-first workflows.
Standout Features. Segregated accounts; insurance disclosures; custody-integrated prime trading. (The Digital Asset Infrastructure Company)
Pricing. Negotiated; custody/prime fees depend on assets and activity.
Availability. Global entities with varying regulatory regimes.
Worth Noting. Derivatives access varies by entity/partner networks.
Alternatives to Consider. Anchorage Digital Prime, Copper ClearLoop. (anchorage.com)
Overview. sFOX acts as an agnostic agent routing across 80+ markets for best execution, with net-price routing and institutional reporting. The platform positions itself as a full-service prime dealer for institutions. (sFOX)
Ideal For. Systematic strategies, RIAs/allocators, corporates seeking agency execution.
Standout Features. SOR across venues; platform-level price improvement; custody options. (sFOX)
Pricing. Tiered/negotiated; historical content points to fee optimization via routing. (sFOX)
Availability. US/global entities; enterprise onboarding.
Worth Noting. Product scope (derivatives, margin) varies; confirm coverage.
Alternatives to Consider. Kraken Prime, Coinbase Prime. (Kraken)
Overview. Following the acquisition and subsequent close of Hidden Road, Ripple Prime offers U.S. spot OTC execution and positions Ripple as the first crypto company to own and operate a global, multi-asset prime broker; custody capabilities expanded further in late 2025. (Ripple)
Ideal For. Institutions seeking an integrated multi-asset prime platform with digital asset rails.
Standout Features. OTC spot execution (U.S.); multi-asset coverage; financing/clearing. (Ripple)
Pricing. Negotiated.
Availability. U.S. launch and global expansion via Ripple entities. (Ripple)
Worth Noting. Product availability differs by jurisdiction and entity.
Alternatives to Consider. FalconX, Coinbase Prime. (falconx.io)
Overview. Binance’s institutional suite spans exchange, OTC RFQ, algos, and programmatic connectivity with VIP tiers. Coverage and eligibility depend on jurisdiction; Binance.US operates separately for U.S. clients. (binance.com)
Ideal For. Non-US teams wanting direct exchange liquidity with OTC tools.
Standout Features. VIP tiers, proof-of-reserves, OTC block trading. (binance.com)
Pricing. Exchange/VIP schedules; negotiated OTC.
Availability. Region-dependent; check supported regions. (binance.com)
Worth Noting. U.S. availability/routes differ; compliance and onboarding vary by entity.
Alternatives to Consider. OKX Institutional, OSL. (OKX)
Overview. OKX highlights high uptime, 900+ instruments, and institutional connectivity. U.S. availability exists through OKX US with scope/policies noted in compliance disclosures. (OKX)
Ideal For. Proprietary firms and funds trading a broad instrument set with API access.
Standout Features. Nitro Spreads, derivatives suite, institutional support. (OKX)
Pricing. Exchange schedule + VIP; negotiated for blocks.
Availability. Global; US services via OKX US (scope varies). (OKX)
Worth Noting. Product availability and licensing differ by region.
Alternatives to Consider. Binance Institutional, Kraken Prime. (binance.com)
Overview. OSL provides a licensed Hong Kong platform spanning custody, exchange, and OTC brokerage for institutions, with dedicated coverage in the region. (osl.com)
Ideal For. APAC institutions needing SFC-regulated venue/custody.
Standout Features. SFC-licensed exchange; institutional API; custody with insurance positioning. (sfc.hk)
Pricing. Schedule/negotiated.
Availability. Hong Kong and supported regions; institutional focus.
Worth Noting. Product availability differs by license and region.
Alternatives to Consider. Zodia Markets, Coinbase Prime. (Zodia Markets)
Overview. ClearLoop enables instant delegation to connected exchanges while assets remain in segregated custody—now supporting third-party custodians like BitGo and Komainu. (Copper)
Ideal For. Institutions prioritizing venue risk reduction and capital efficiency.
Standout Features. Multi-custodial support; instant asset delegation; network of venues/prime brokers. (Copper)
Pricing. Varies by participants and volumes.
Availability. Global network; coverage depends on participating venues/custodians.
Worth Noting. Not a full prime broker by itself; pairs well with custody/venues.
Alternatives to Consider. Zodia Interchange, Komainu Connect. (zodia-custody.com)
Overview. Zodia Markets offers institutional brokerage/exchange with non-custodial design, while Zodia Custody’s Interchange provides off-venue settlement (OVS)—trade while assets remain in custody. Registrations span UK, Ireland, ADGM. (Zodia Markets)
Ideal For. Institutions wanting bank-backed governance and segregated settlement flows.
Standout Features. Non-custodial brokerage; Interchange OVS network; institutional registrations. (Zodia Markets)
Pricing. Negotiated.
Availability. UK/EU/MENA institutional coverage (entity-specific). (Zodia Markets)
Worth Noting. Product scope varies by entity and venue integrations.
Alternatives to Consider. OSL, Copper ClearLoop. (osl.com)
Start a Token Metrics trial to bring quantitative screening and scenario analysis into your institutional workflow.
Compliance note: This article is for research/education, not financial advice.
What is a crypto prime broker?
A provider that consolidates institutional trading, financing, custody, and settlement, often with multi-venue access and risk controls. Modern variants add off-exchange settlement so assets remain in custody during execution. (zodia-custody.com)
Do prime brokers publish fees?
Often no—fees are negotiated based on volumes, products, and relationship tier. Some venues publish maker/taker schedules with institutional perks. (docs.cdp.coinbase.com)
How does off-exchange settlement work?
Networks like ClearLoop and Interchange let you delegate assets to venues for trading while keeping them in segregated custody, reducing counterparty risk. (Copper)
Which providers are strongest for regulated custody?
Anchorage Digital Prime (US bank custody), BitGo (qualified custody), OSL (HK SFC-licensed custody/exchange), and Zodia (bank-backed with EU/UK registrations). (anchorage.com)
Can U.S. institutions use OKX or Binance?
Access is region-dependent and varies by entity (e.g., OKX US scope). U.S. clients typically cannot use Binance.com and instead must evaluate Binance.US or other U.S.-eligible routes. Always check official disclosures. (OKX)
For most global institutions, a two-stack works best: (1) an integrated prime broker with qualified custody (Coinbase Prime, Anchorage Digital Prime, or BitGo Prime) and (2) a venue-risk mitigator like Copper ClearLoop or Zodia Interchange. Execution-heavy funds should add FalconX or Kraken Prime for multi-venue and OTC derivatives coverage, while OSL anchors APAC/HK mandates and OKX/Binance expand exchange reach where eligible. (Coinbase)
Related Resources:
The real-world asset tokenization market has experienced explosive growth, surging from $85 million in April 2020 to over $25 billion by mid-2025—representing a staggering 245-fold increase driven primarily by institutional demand for yield, transparency, and regulatory clarity. Private credit dominates at approximately 61% of total tokenized assets, followed by treasuries at 30%, with major asset managers like BlackRock, Apollo, and Franklin Templeton now actively tokenizing institutional-grade products.
The convergence of traditional finance and decentralized infrastructure has created unprecedented opportunities for investors seeking stable, real-world yields without exposure to cryptocurrency volatility. The tokenized RWA market is projected to reach between $9.43 trillion and $18.9 trillion by 2030, with regulatory frameworks in Singapore, Hong Kong, and Dubai providing clear pathways for compliant innovation.
For crypto-native investors, RWA yield marketplaces offer a critical bridge to sustainable income streams backed by productive assets rather than purely speculative token emissions. Traditional allocators gain 24/7 access to fractional ownership, instant settlement, and programmable compliance—advantages impossible in legacy financial infrastructure.
We assessed platforms across six weighted criteria totaling 100 points:
Data sources: Official platform documentation, on-chain analytics from RWA.xyz and DeFiLlama, third-party audits, and regulatory filings. Research conducted October 2024-January 2025.
Verification approach: Every fee structure, yield figure, and regional restriction cited was verified on official platform pages or regulatory disclosures. Unverifiable claims were excluded.

Overview
Ondo Finance manages over $1.6 billion in tokenized assets, offering institutional-grade access to US Treasury exposure through OUSG (backed by BlackRock's BUIDL fund) and USDY (a yield-bearing stablecoin). The platform bridges TradFi stability with DeFi composability through multi-chain deployment across Ethereum, Solana, Base, and XRP Ledger.
Ideal For
Standout Features
Pricing
Management fees embedded in net yield; typical 0.15-0.30% annual fee depending on product. OUSG requires $100K minimum; USDY accessible at lower thresholds with 4.29% APY.
Availability
Global except US persons for certain products. Ethereum, Solana, Polygon, Aptos, Sei, Base, XRP Ledger, and Sui supported.
Worth Noting
OUSG designed for qualified purchasers with extended lockup periods; less suitable for retail or high-frequency traders. Platform prioritizes institutional relationships over retail accessibility.
Alternatives to Consider: Franklin Templeton BENJI, OpenEden TBILL
Overview
Franklin Templeton's $775 million Franklin OnChain U.S. Government Money Fund (BENJI) pioneered tokenized mutual funds in 2021, offering exposure to US government securities across eight blockchains with patent-pending intraday yield calculation.
Ideal For
Standout Features
Pricing
7-day current yield approximately 4.5-5.5% gross; 0.25% management fee. No minimum investment restrictions beyond standard mutual fund requirements.
Availability
Global availability with specific KYC requirements. Active on Stellar, Ethereum, Arbitrum, Base, Avalanche, Polygon, Aptos, Solana, BNB Chain.
Worth Noting
Traditional mutual fund constraints apply including daily NAV calculations and potential redemption delays during market stress.
Alternatives to Consider: Backed bIB01, Superstate Short Duration Government Securities
Overview
Maple Finance manages over $4 billion in assets, specializing in institutional over-collateralized lending backed by Bitcoin, Ethereum, Solana, and XRP, targeting $100 billion in annual loan volume by 2030. The platform introduced SyrupUSDC for permissionless retail access alongside KYC-gated institutional pools.
Ideal For
Standout Features
Pricing
Variable by pool; typical effective yields 9-12% after protocol fees. Minimum investments pool-dependent, generally $10K-$50K for retail syrup products.
Availability
Global with KYC requirements for lending. Institutional Maple requires accreditation; Syrup.fi open to broader participants.
Worth Noting
Platform transitioned from uncollateralized to over-collateralized model after 2022 market turmoil. Historical defaults impacted certain pools; robust recovery mechanisms now in place.
Alternatives to Consider: Credix (emerging markets), TrueFi (uncollateralized DeFi)
Overview
Goldfinch Prime aggregates exposure to multi-billion dollar private credit funds from Ares, Apollo, Golub Capital, and KKR, providing on-chain access to institutional-grade senior secured loans with over $1 trillion in collective AUM.
Ideal For
Standout Features
Pricing
Net yields 9-12% after embedded management fees and profit sharing. Minimum investments vary by pool structure; typically institutional minimums apply.
Availability
Non-US persons only due to regulatory structure. KYC and accreditation verification required.
Worth Noting
Exposure is indirect through fund shares rather than direct loan origination; fund managers absorb individual borrower default risk into aggregate yields. Liquidity limited compared to Treasury products.
Alternatives to Consider: Centrifuge private credit pools, Credix fintech lending
Overview
Centrifuge operates as a multichain infrastructure platform enabling asset managers to tokenize real estate, trade finance, carbon credits, and structured credit with $1.2 billion TVL and recent 10x growth driven by the first on-chain CLO and tokenized S&P 500 index fund.
Ideal For
Standout Features
Pricing
Yields vary by pool and tranche: typically 6-8% for senior tranches, 10-14% for junior tranches. Management fees embedded; pool-specific minimums apply.
Availability
Global with KYC requirements. Pools may have additional jurisdictional restrictions based on underlying asset location.
Worth Noting
Platform complexity requires understanding of tranched structures and asset-specific risks. Less liquid credit instruments offer less frequent pricing updates than treasury products.
Alternatives to Consider: RealT (US residential real estate focus), Republic (equity crowdfunding)
Overview
Credix specializes in providing credit facilities to fintech lenders in Latin America, offering high-yield exposure to underserved credit markets with institutional-grade underwriting and local market expertise.
Ideal For
Standout Features
Pricing
Pool-dependent yields typically 12-18% gross with management fees of 1-2%. Minimum investments generally $50K+ for accredited investors.
Availability
Non-US persons primarily; requires accreditation verification and enhanced KYC given emerging market exposure.
Worth Noting
Higher yields reflect higher credit and currency risk. Platform experienced challenges during regional economic volatility; enhanced risk controls now implemented.
Alternatives to Consider: Goldfinch V1 pools (emerging market focus), TrueFi uncollateralized pools
Overview
Securitize has tokenized over $4.5 billion in assets for 1.2 million investors across 3,000+ clients, operating as an SEC-registered transfer agent with integrated ATS for secondary trading. The platform powers major offerings including BlackRock's BUIDL fund.
Ideal For
Standout Features
Pricing
Platform fees vary by issuance size and complexity; typically 0.5-2% of AUM plus basis point fees on transactions. White-label solutions available for enterprise clients.
Availability
Global operations with jurisdiction-specific compliance modules. Primary focus on US, EU, and APAC institutional markets.
Worth Noting
Securitize is an issuance platform rather than direct investment product; investors access opportunities through partner funds and offerings launched on the infrastructure.
Alternatives to Consider: Tokeny (EU-focused), Polymath/Polymesh (security token specialists)
Token Metrics provides critical intelligence for navigating RWA yield opportunities through data-driven analysis and market insights.
Research Phase: Leverage Token Metrics' fundamental analysis to evaluate tokenized asset protocols, comparing on-chain metrics, TVL trends, and yield sustainability indicators. Our RWA sector reports identify emerging platforms and highlight regulatory developments across jurisdictions.
Portfolio Construction: Use quantitative scoring to allocate across risk tiers—balancing stable treasury exposure with higher-yield credit products. Token Metrics' portfolio tools help optimize diversification while monitoring correlation to traditional crypto markets.
Ongoing Monitoring: Real-time alerts notify you of yield changes, protocol upgrades, and risk events. Our dashboard aggregates performance across multiple RWA platforms, tracking your yield-bearing positions alongside broader cryptocurrency holdings.
Risk Management: Token Metrics' risk analytics assess smart contract security, custody arrangements, and counterparty exposure. Our reports flag platforms with concerning yield sustainability metrics or operational red flags before they impact your capital.
Start your Token Metrics free trial to access institutional-grade RWA research and optimize your real-world asset allocation.
This article is for research and educational purposes, not financial advice. RWA investments carry risks including loss of principal.
What's the difference between tokenized treasuries and yield-bearing stablecoins?
Tokenized treasuries (like OUSG) represent direct ownership of US Treasury securities with yield passed through to holders. Yield-bearing stablecoins (like USDY) maintain $1 peg while distributing treasury yields via rebasing or airdrops. Treasuries may fluctuate slightly with NAV; yield stablecoins prioritize price stability.
Are RWA yields taxable differently than crypto staking rewards?
Likely yes, though tax treatment varies by jurisdiction. RWA yields from treasuries or credit facilities often classified as interest income taxed at ordinary rates. Crypto staking may be treated as income at receipt or capital gains at sale depending on location. Consult tax professionals for specific guidance.
Can I use tokenized RWAs as collateral in DeFi protocols?
Increasingly yes. Platforms like Maple, Ondo (via Flux Finance), and Centrifuge enable using tokenized assets as DeFi collateral. However, support varies by protocol and asset—USDY and OUSG see broader integration than niche real estate tokens. Liquidation risks apply if collateral value drops.
What happens if the platform goes bankrupt?
Properly structured tokenization isolates assets in bankruptcy-remote SPVs, protecting investor claims even if platform operator fails. However, redemption processes may be delayed and require legal navigation. This is why verifying legal structure and custodial arrangements is critical.
How liquid are RWA tokens compared to stablecoins?
Significantly less liquid. While stablecoins have billions in daily DEX volume, most RWA tokens trade thinly or only through platform-controlled redemption mechanisms. Treasury tokens offer better liquidity than private credit or real estate, but all lag traditional stablecoins substantially.
Do I need to be an accredited investor?
Depends on the platform and your location. US-based offerings often require accreditation; international platforms may have lower barriers. Products like USDY, syrupUSDC, and BENJI target broader accessibility, while institutional credit pools restrict to qualified purchasers.
What are the main risks that could cause loss of principal?
(1) Underlying asset default (credit risk), (2) smart contract exploitation, (3) platform insolvency without proper asset segregation, (4) regulatory action freezing operations, (5) stablecoin de-pegging for yield products denominated in USDC/USDT, (6) liquidation cascades in collateralized structures.
How do yields compare to traditional finance alternatives?
Tokenized treasuries (4-5%) match conventional money market funds but with 24/7 access. Private credit RWAs (9-12%) offer premiums over corporate bonds due to illiquidity and platform novelty. Emerging market RWA yields (12-18%) comparable to EM debt funds with added smart contract risk.
Real-world asset yield marketplaces represent the maturation of blockchain infrastructure beyond speculation into productive finance. For investors seeking stable, asset-backed returns uncorrelated to cryptocurrency volatility, platforms like Ondo Finance and Franklin Templeton deliver institutional-grade treasury exposure with DeFi composability. Those comfortable with credit risk can access superior yields through Maple Finance's collateralized institutional lending or Goldfinch Prime's diversified private credit exposure.
The key to success: match platform selection to your specific risk tolerance, liquidity needs, and regulatory constraints. Treasury products suit conservative allocators prioritizing capital preservation; credit platforms reward investors accepting higher risk for enhanced returns; multi-asset infrastructure like Centrifuge offers diversification across real-world credit types.
Start with smaller allocations to understand platform mechanics, redemption processes, and yield consistency before committing substantial capital. The RWA sector's rapid growth will continue creating opportunities, but also attracting lower-quality offerings—due diligence remains paramount.
Methodology: This guide evaluated 20+ RWA platforms through analysis of official documentation, on-chain data, regulatory filings, and third-party audits. Platforms selected represent meaningful TVL (>$100M), regulatory compliance, and operational track record. Final selection prioritized diversity across asset classes and investor accessibility tiers.
Research Sources:
All data current as of January 2025. Platform features and yields subject to change; verify current terms on official websites before investing.
Who this guide is for. Crypto investors and treasurers comparing gold-backed tokens and other commodity-backed assets that can be audited and, in many cases, redeemed for metal.
Top three picks. PAX Gold (PAXG) for regulated, bar-linked redemption; Tether Gold (XAUt) for broad awareness and simple fees; Kinesis (KAU/KAG) for spend-and-yield use cases.
Key caveat. Redemption minimums, custody locations, and fees vary by issuer; always confirm regional eligibility and schedules on the official pages.
Gold-backed tokens give on-chain ownership exposure to vaulted bullion with transparent allocation and, often, physical redemption, blending the inflation hedge of metals with crypto liquidity. In 2025, they’re used for hedging, collateral, cross-border settlement, and “digital cash” backed by tangible assets. A commodity-backed token is a blockchain token that represents title to a specific quantity of a real-world commodity (for example, 1 troy ounce or 1 gram of gold) held by a custodian, typically with published fees, vault locations, and redemption rules. Our picks prioritize liquidity, security controls, breadth of metals, cost transparency, and global accessibility.

We excluded defunct or sunset projects (e.g., PMGT; CACHE Gold ceased backing CGT on Sept 30, 2025). (perthmint.com)
Why Use It. PAXG links each token to specific LBMA Good Delivery bars stored in London, offering direct bar redemption (institutional minimums apply) or USD redemption at spot. Paxos publishes fee schedules and notes no storage fee charged to customers at this time. (paxos.com)
Best For. Institutions; HNW hedgers; DeFi users needing reputable collateral.
Notable Features. LBMA bars; serial-number linkage; custodied in London; fiat redemption option. (paxos.com)
Fees Notes. Creation/destruction fees; no storage fee currently per issuer help center. (help.paxos.com)
Regions. Global (issuer KYC).
Consider If. You can meet bar redemption minimums and UK vault logistics. (help.paxos.com)
Alternatives. Tether Gold (XAUt); VNX Gold (VNXAU).
Why Use It. XAUt represents allocated gold and can be redeemed for physical gold or USD; Tether publishes a straightforward 0.25% creation/redemption fee and a one-time verification fee for onboarding. FAQs outline redemption mechanics and bar specifics. (Tether)
Best For. Traders seeking brand familiarity; cross-chain users (ETH/TRON).
Notable Features. Bar metadata; physical or USD redemption; no custody fee disclosed beyond the transaction fee. (Tether)
Fees Notes. 25 bps create/redeem; separate KYC verification fee. (Tether)
Regions. Global (issuer KYC).
Consider If. You need clear fee math but don’t require bar-specific allocation like PAXG.
Alternatives. PAX Gold (PAXG); Kinesis (KAU).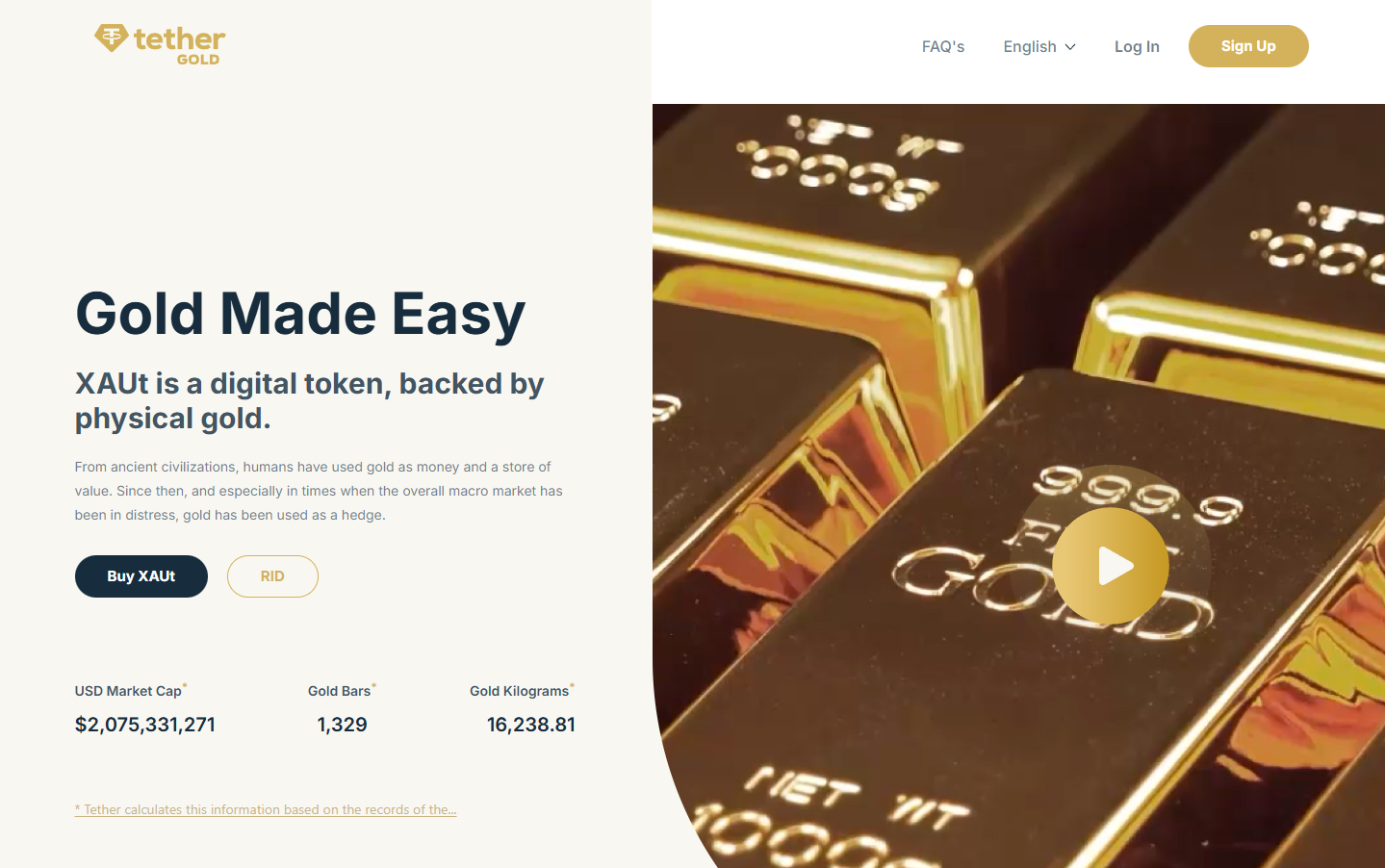
Why Use It. Kinesis combines metal-backed tokens with an exchange, cards, and yields funded from platform fees (published yield-share). Trading and precious metals transactions show ~0.22% execution fees on official schedules. (Kinesis)
Best For. Users wanting to spend gold/silver, earn monthly yields, and keep fees predictable.
Notable Features. Fee-share yield (published); exchange, card rails; gold & silver pairs. (Kinesis)
Fees Notes. ~0.22% buy/sell/trade; other fees per schedule. (Kinesis)
Regions. Global (platform KYC/availability).
Consider If. You prefer an integrated platform over a standalone token.
Alternatives. VNX (VNXAU/VNXAG); Aurus (tXAU/tXAG).
Why Use It. CGO tokenizes 1g gold units on the XDC (XRC-20) network, with a published fee structure for mint/redeem (0.50%), transfers (0.50%), and custody notes in FAQs. Documentation details creation/redemption and delivery fees. (comtechgold.com)
Best For. XDC builders; users needing Shariah-compliant structuring.
Notable Features. On-chain proofing; fee schedule; vault delivery options. (comtechgold.com)
Fees Notes. 0.50% mint/redeem; 0.50% transfer; custody terms disclosed. (comtechgold.com)
Regions. Global (issuer terms apply).
Consider If. You’re comfortable with XDC rails and issuer fee model.
Alternatives. PAXG; VNXAU.
Why Use It. VNXAU gives direct ownership of allocated bars stored in Liechtenstein with a public allocation lookup tool. VNX runs on Ethereum, Polygon, Q, and Solana, and has communications on redemption and delivery. (VNX)
Best For. EEA users; diversification across chains.
Notable Features. Allocation lookup by serial; segregated AAA-jurisdiction vault; multi-chain. (VNX)
Fees Notes. See VNX pricing and product pages for current schedules.
Regions. EEA emphasis; global availability varies by KYC.
Consider If. You want EEA custody and serial-level transparency.
Alternatives. PAXG; XAUt.
Why Use It. Aurus issues 1-gram tokens backed by vaulted gold and silver with insured, audited storage. tGOLD and tSILVER support multi-chain DeFi integrations and a mobile app, with ecosystem partners for mint/redeem. (AURUS)
Best For. DeFi users; small-denomination accumulation; multi-metal portfolios (includes platinum via tXPT).
Notable Features. 1g units; insured vaulted metals; app & dashboard; partner network. (AURUS)
Fees Notes. Exchange/network fees; issuer/partner fees may apply.
Regions. Global (partner KYC where required).
Consider If. You want gram-level flexibility and cross-chain access.
Alternatives. Kinesis; VNX.
Why Use It. Tokens AUS (gold) and AGS (silver) are backed by allocated bullion held in Australian high-security vaults with $0 storage and transfer at the issuer level and partner-facilitated redemptions. (goldsilverstandard.com)
Best For. AUD-centric investors; straightforward physical pickup/delivery via partners.
Notable Features. 1g linkage; local redemption via Ainslie partners; Australia-first focus. (goldsilverstandard.com)
Fees Notes. Issuer lists $0 storage/transfer; exchange and redemption partner fees may apply. (goldsilverstandard.com)
Regions. Australia focus; global varies.
Consider If. You need straightforward redemption in Australia.
Alternatives. PAXG; VNXAU.
Why Use It. VNXAG mirrors the VNXAU model for silver, backed by allocated metal with the same allocation lookup tooling and multi-chain issuance. (VNX)
Best For. EEA investors prioritizing silver in segregated storage.
Notable Features. Allocation lookup; EEA custody; multi-chain support. (VNX)
Fees Notes. See VNX site for current schedules.
Regions. EEA emphasis; global varies.
Consider If. You want EEA-vaulted silver with serial-level transparency.
Alternatives. KAG; tXAG.
Why Use It. VRO is an ERC-20 token pegged to 1 gram of LBMA-standard gold, issued by a long-standing French precious-metal group; materials describe secured storage and regular audits. (VeraOne)
Best For. EU users; gram-based savings; euro on-ramps.
Notable Features. 1g linkage; audited storage; EU presence. (VeraOne)
Fees Notes. Issuer materials outline model; confirm current fees on site.
Regions. EU focus; global access varies.
Consider If. You want EU branding and ERC-20 simplicity.
Alternatives. PAXG; VNXAU.
Why Use It. AgAu outlines 1:1 backed gold and silver tokens with Swiss custody and a peer-to-peer payment focus; docs and reports describe convertibility and audited reserves. (agau.io)
Best For. Users seeking Swiss jurisdiction and payments-style UX.
Notable Features. Swiss issuer; P2P spend; audit & documents hub. (agau.io)
Fees Notes. See issuer documentation for fees and redemption steps.
Regions. Global (jurisdictional checks apply).
Consider If. You want Swiss custody with payments emphasis.
Alternatives. VNXAU; AUS.
CTA: Start free trial to screen assets and time entries with AI.
What are gold-backed tokens?
They are blockchain tokens that represent ownership of a specific quantity of vaulted, insured gold, typically with published fees and, in some cases, physical redemption options.
Are gold-backed tokens safer than stablecoins?
They can diversify away from fiat risk, but introduce custody and redemption dependencies. Safety depends on the issuer’s vaulting, audits, legal structure, and your ability to redeem.
What fees should I expect?
Common fees include creation/redemption, possible storage, transfer, and network fees. Examples: XAUt lists 0.25% create/redeem; Paxos publishes creation/destruction fees and notes no storage fee currently. Always check the live schedules. (Tether)
Can I redeem tokens for a real gold bar?
Some issuers support bar redemption with minimum sizes and location constraints (e.g., LBMA bar logistics in London for PAXG). Others support gram-level redemption via partners. (help.paxos.com)
Which chains are supported?
Varies: PAXG (Ethereum), XAUt (Ethereum/TRON), VNX (Ethereum/Polygon/Q/Solana), Aurus (multi-chain), CGO (XDC), Kinesis (native + exchange listings). (paxos.com)
Are there discontinued tokens I should avoid?
Yes. PMGT has been discontinued; CACHE Gold (CGT) ceased backing as of Sept 30, 2025. Verify project status before buying. (perthmint.com)
Choose PAXG for bar-linked redemption and strong disclosures, XAUt for simple fees and brand reach, or Kinesis if you want to spend metals and earn fee-share yields. For EEA vaulting with allocation lookup, VNX is compelling; for gram-based DeFi exposure, Aurus is versatile.
Related Reads:
.svg)




.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.















































%20Price%20Prediction%202025%2C%202030%20-%20Forecast%20Analysis.png)

















.png)

%20Price%20Prediction%20.webp)









%20Price%20Prediction.webp)



%20Price%20Prediction%20Analysis%20-%20Can%20it%20Reach%20%24500%20in%20Future_.png)


















