
































.png)























.png)
.png)








.png)



.png)
%201%20(1).png)

.png)


.png)






.png)
.png)



.png)

















.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)


































































































.png)








.png)

.png)
.png)









.png)


.png)
.png)
.png)
.png)

.png)
.png)











Research
Top Crypto Trading Platforms in 2025
When it comes to crypto trading platforms, Token Metrics is not an exchange, but a crypto analytics and crypto trading intelligence platform powered by AI.
Token Metrics Team
10 min




%201.svg)
%201.svg)
Big news: We’re cranking up the heat on AI-driven crypto analytics with the launch of the Token Metrics API and our official SDK (Software Development Kit). This isn’t just an upgrade – it's a quantum leap, giving traders, hedge funds, developers, and institutions direct access to cutting-edge market intelligence, trading signals, and predictive analytics.
Crypto markets move fast, and having real-time, AI-powered insights can be the difference between catching the next big trend or getting left behind. Until now, traders and quants have been wrestling with scattered data, delayed reporting, and a lack of truly predictive analytics. Not anymore.
The Token Metrics API delivers 32+ high-performance endpoints packed with powerful AI-driven insights right into your lap, including:
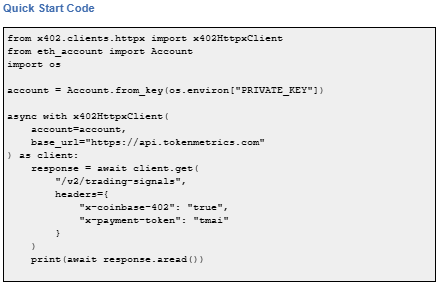
Getting started with the Token Metrics API is simple:
At Token Metrics, we believe data should be decentralized, predictive, and actionable.
The Token Metrics API & SDK bring next-gen AI-powered crypto intelligence to anyone looking to trade smarter, build better, and stay ahead of the curve. With our official SDK, developers can plug these insights into their own trading bots, dashboards, and research tools – no need to reinvent the wheel.
DeFi protocols are maturing beyond early ponzi dynamics toward sustainable revenue models. Aave operates in this evolving landscape where real yield and proven product-market fit increasingly drive valuations rather than speculation alone. Growing regulatory pressure on centralized platforms creates tailwinds for decentralized alternatives—factors that inform our comprehensive AAVE price prediction framework.
The scenario bands below reflect how AAVE price predictions might perform across different total crypto market cap environments. Each tier represents a distinct liquidity regime, from bear conditions with muted DeFi activity to moon scenarios where decentralized infrastructure captures significant value from traditional finance.

Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline: Token Metrics TM Grade is 72, Buy, and the trading signal is bullish, indicating solid protocol fundamentals, healthy developer activity, and positive near-term momentum. Concise twelve-month numeric view, Token Metrics price prediction scenarios cluster roughly between $70 and $320, with a base case near $150, reflecting continued growth in lending TVL, fee revenue capture by the protocol, and modest macro tailwinds.
Live details: Aave Token Details
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Our Token Metrics price prediction framework spans four market cap tiers, each representing different levels of crypto market maturity and liquidity:
8T Market Cap - AAVE Price Prediction:
At an 8 trillion dollar total crypto market cap, AAVE projects to $293.45 in bear conditions, $396.69 in the base case, and $499.94 in bullish scenarios.
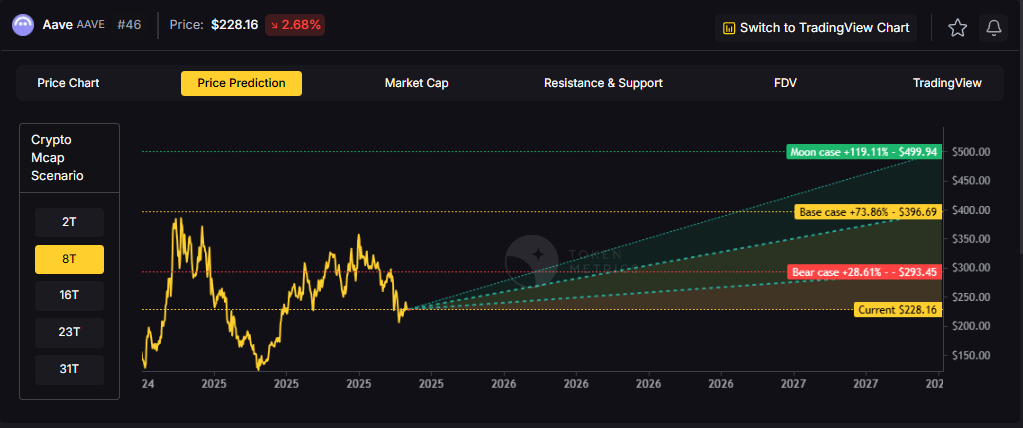
Doubling the market to 16 trillion expands the price prediction range to $427.46 (bear), $732.18 (base), and $1,041.91 (moon).
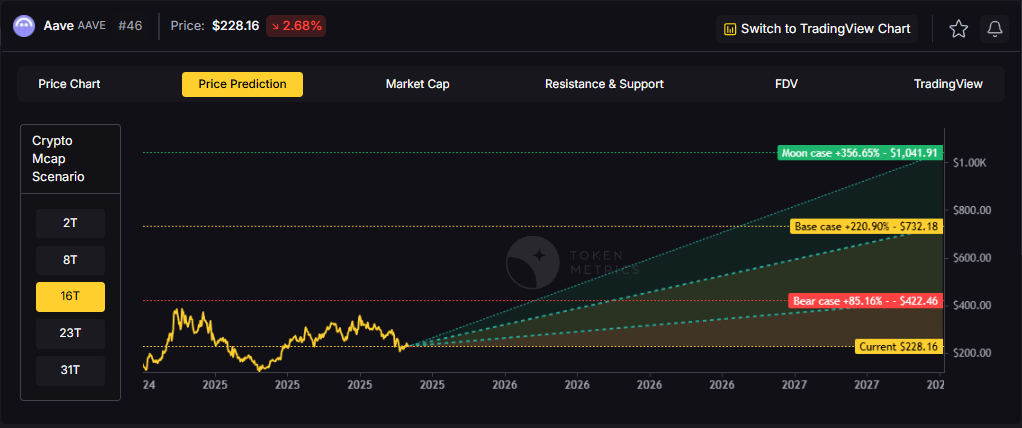
At 23 trillion, the price prediction scenarios show $551.46, $1,007.67, and $1,583.86 respectively.

In the maximum liquidity scenario of 31 trillion, AAVE price predictions could reach $680.47 (bear), $1,403.16 (base), or $2,175.85 (moon).
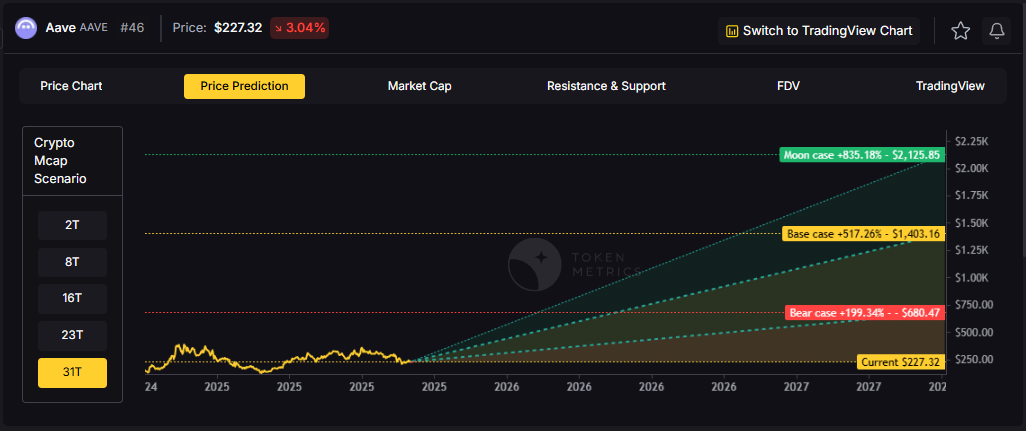
Each tier assumes progressively stronger market conditions, with the base case price prediction reflecting steady growth and the moon case requiring sustained bull market dynamics.
Aave represents one opportunity among hundreds in crypto markets. Token Metrics Indices bundle AAVE with top one hundred assets for systematic exposure to the strongest projects. Single tokens face idiosyncratic risks that diversified baskets mitigate.
Historical index performance demonstrates the value of systematic diversification versus concentrated positions.
Aave is a decentralized lending protocol that operates across multiple EVM-compatible chains including Ethereum, Polygon, Arbitrum, and Optimism. The network enables users to supply crypto assets as collateral and borrow against them in an over-collateralized manner, with interest rates dynamically adjusted based on utilization.
The AAVE token serves as both a governance asset and a backstop for the protocol through the Safety Module, where stakers earn rewards in exchange for assuming shortfall risk. Primary utilities include voting on protocol upgrades, fee switches, collateral parameters, and new market deployments.
Token Metrics AI provides comprehensive context on Aave's positioning and challenges.
Vision: Aave aims to create an open, accessible, and non-custodial financial system where users have full control over their assets. Its vision centers on decentralizing credit markets and enabling seamless, trustless lending and borrowing across blockchain networks.
Problem: Traditional financial systems often exclude users due to geographic, economic, or institutional barriers. Even in crypto, accessing credit or earning yield on idle assets can be complex, slow, or require centralized intermediaries. Aave addresses the need for transparent, permissionless, and efficient lending and borrowing markets in the digital asset space.
Solution: Aave uses a decentralized protocol where users supply assets to liquidity pools and earn interest, while borrowers can draw from these pools by posting collateral. It supports features like variable and stable interest rates, flash loans, and cross-chain functionality through its Layer 2 and multi-chain deployments. The AAVE token is used for governance and as a safety mechanism via its staking program (Safety Module).
Market Analysis: Aave is a leading player in the DeFi lending sector, often compared with protocols like Compound and Maker. It benefits from strong brand recognition, a mature codebase, and ongoing innovation such as Aave Arc for institutional pools and cross-chain expansion. Adoption is driven by liquidity, developer activity, and integration with other DeFi platforms. Key risks include competition from newer lending protocols, regulatory scrutiny on DeFi, and smart contract risks. As a top DeFi project, Aave's performance reflects broader trends in decentralized finance, including yield demand, network security, and user trust. Its multi-chain strategy helps maintain relevance amid shifting ecosystem dynamics.
Fundamental Grade: 75.51% (Community 77%, Tokenomics 100%, Exchange 100%, VC 49%, DeFi Scanner 70%).

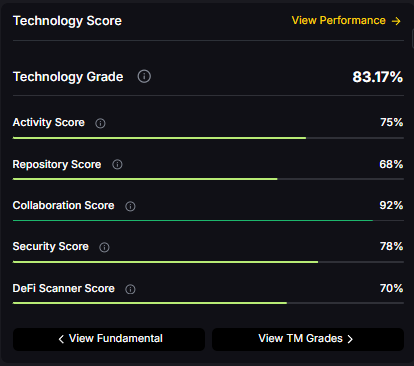
Technology Grade: 83.17% (Activity 75%, Repository 68%, Collaboration 92%, Security 78%, DeFi Scanner 70%).
Yes. Based on our price prediction scenarios, AAVE could reach $1,007.67 in the 23T base case and $1,041.91 in the 16T moon case. Not financial advice.
At current price of $228.16, a 10x would reach $2,281.60. This falls within the 31T moon case price prediction at $2,175.85 (only slightly below), and would require extreme liquidity expansion. Not financial advice.
Our moon case price predictions range from $499.94 at 8T to $2,175.85 at 31T. These scenarios assume maximum liquidity expansion and strong Aave adoption. Not financial advice.
Our comprehensive 2027 price prediction framework suggests AAVE could trade between $293.45 and $2,175.85, depending on market conditions and total crypto market capitalization. The base case scenario clusters around $396.69 to $1,403.16 across different market cap environments. Not financial advice.
AAVE shows strong fundamentals (75.51% grade) and technology scores (83.17% grade), with bullish trading signals. However, all price predictions involve uncertainty and risk. Always conduct your own research and consult financial advisors before investing. Not financial advice.

Track live grades and signals: Token Details
Want exposure? Buy AAVE on MEXC
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
x402 is an open-source, HTTP-native payment protocol developed by Coinbase that enables pay-per-call API access using crypto wallets. It leverages the HTTP 402 Payment Required status code to create seamless, keyless API payments.
It eliminates traditional API keys and subscriptions, allowing agents and applications to pay for exactly what they use in real time. It works across Base and Solana with USDC and selected native tokens such as TMAI.
Start using Token Metrics X402 integration here. https://www.x402scan.com/server/244415a1-d172-4867-ac30-6af563fd4d25
x402 transforms API access by making payments native to HTTP requests.
Feature | Traditional APIs | x402 APIs |
Authentication | API keys, tokens | Wallet signature |
Payment Model | Subscription, prepaid | Pay-per-call |
Onboarding | Sign up, KYC, billing | Connect wallet |
Rate Limits | Fixed tiers | Economic (pay more = more access) |
Commitment | Monthly/annual | Zero, per-call only |
How to use it: Add x-coinbase-402: true header to any supported endpoint. Sign payment with your wallet. The API responds immediately after confirming micro-payment.
Token Metrics integration: All public endpoints available via x402 with per-call pricing from $0.017 to $0.068 USDC (10% discount with TMAI token).
Explore live agents: https://www.x402scan.com/composer.
The Protocol Flow
The HTTP 402 status code was reserved in HTTP/1.1 in 1997 for future digital payment use cases and was never standardized for any specific payment scheme. x402 activates this path by using 402 responses to coordinate crypto payments during API requests.
Why this matters: It eliminates intermediary payment processors, enables true machine-to-machine commerce, and reduces friction for AI agents.
CoinGecko Recognition
CoinGecko launched a dedicated x402 Ecosystem category in October 2025, tracking 700+ projects with over $1 billion market cap and approximately $213 million in daily trading volume. Top performers include PING and Alnalyst, along with established projects like EigenCloud.
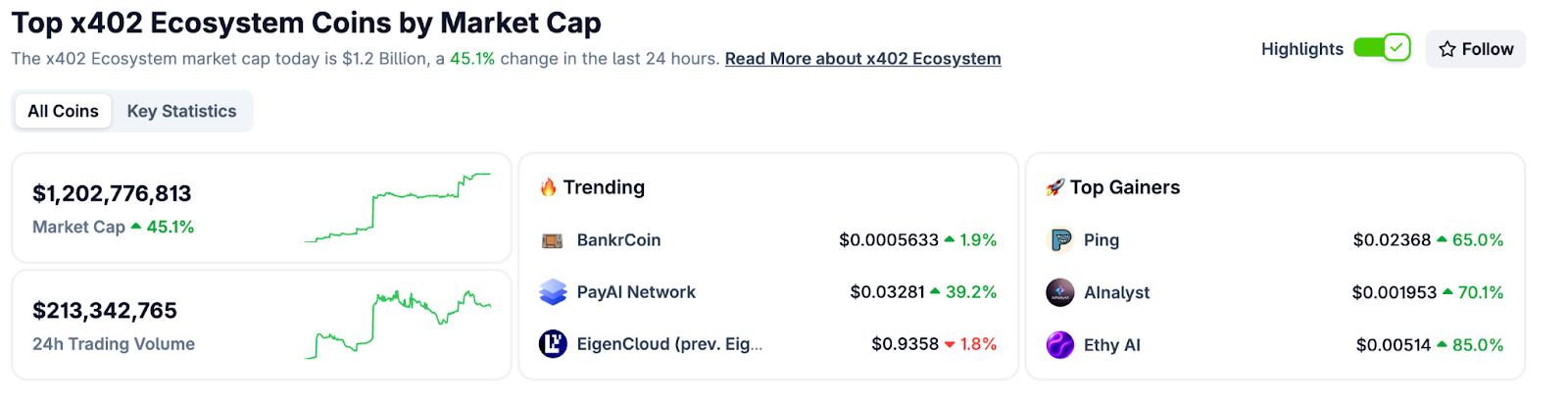
Base Network Adoption
Base has emerged as the primary chain for x402 adoption, with 450,000+ weekly transactions by late October 2025, up from near-zero in May. This growth demonstrates real agent and developer usage.
Composer is x402scan's sandbox for discovering and using AI agents that pay per tool call. Users can open any agent, chat with it, and watch tool calls and payments stream in real time.
Top agents include AInalyst, Canza, SOSA, and NewEra. The Composer feed shows live activity across all agents.

Explore Composer: https://x402scan.com/composer
What We Ship
Token Metrics offers all public API endpoints via x402 with no API key required. Pay per call with USDC or TMAI for a 10 percent discount. Access includes trading signals, price predictions, fundamental grades, technology scores, indices data, and the AI chatbot.
Check out Token Metrics Integration on X402. https://www.x402scan.com/server/244415a1-d172-4867-ac30-6af563fd4d25
Data as of October, 2025.
Pricing Tiers
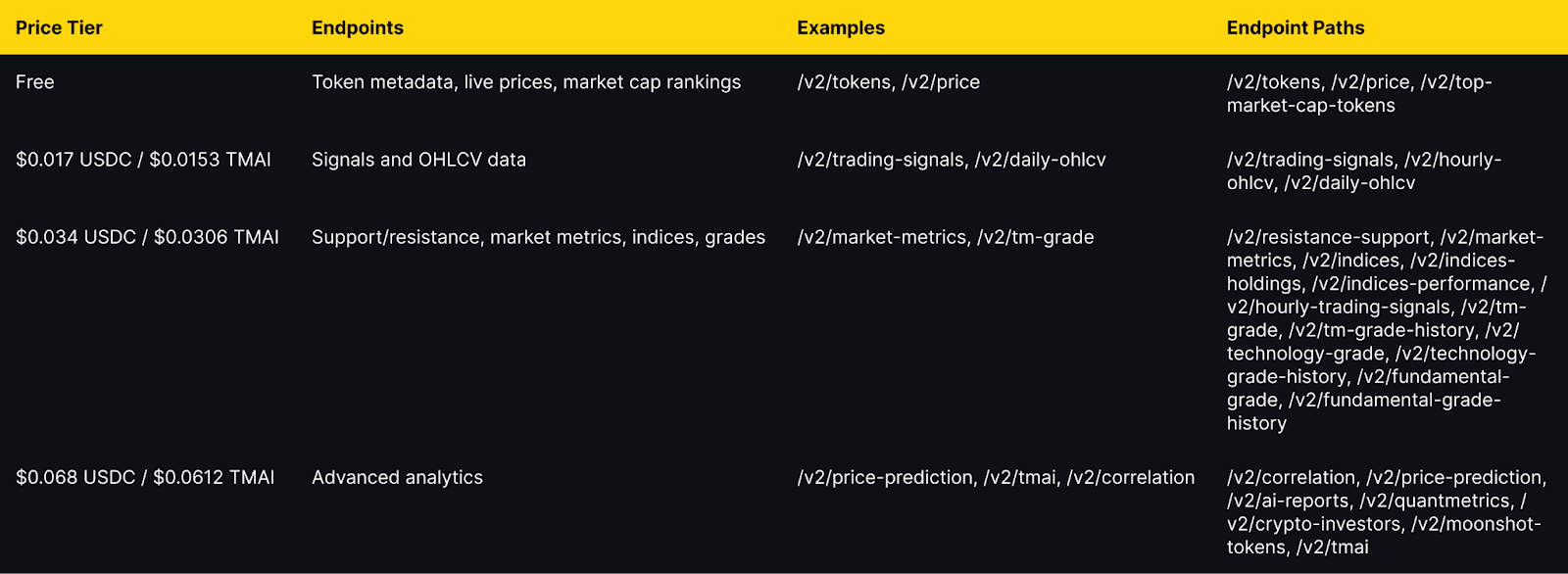
Important note: TMAI Spend Limit: TMAI has 18 decimals. Set max payment to avoid overspending. Example: 200 TMAI = 200 * (10 ** 18) in base units.
Full integration guide: https://api.tokenmetrics.com
Ecosystem Participants and Tools
Active x402 Endpoints
Key endpoints beyond Token Metrics include Heurist Mesh for crypto intelligence, Tavily extract for structured web content, Firecrawl search for SERP and scraping, Twitter or X search for social discovery, and various DeFi and market data providers.
Infrastructure and Tools
Common Questions About x402
How is x402 different from traditional API keys?
x402 uses wallet signatures instead of API keys. Payment happens per call rather than via subscription. No sign-up, no monthly billing, no rate limit tiers. You pay for exactly what you use.
Which chains support x402?
Currently Base and Solana. Most activity is on Base with USDC as the primary payment token. Some endpoints accept native tokens like TMAI for discounts.
Do I need to trust the API provider with my funds?
No. Payments are on-chain and verifiable. You approve each transaction amount. No escrow or prepayment is required.
What happens if a payment fails?
The API returns 402 Payment Required again with updated payment details. Your client retries automatically. You do not receive data until payment confirms.
Can I use x402 with existing API clients?
Yes, with x402 client libraries such as x402-axios for Node and x402-httpx for Python. These wrap standard HTTP clients and handle the payment flow automatically.
Getting Started Checklist
Token Metrics x402 Resources
What's Next for x402
Ecosystem expansion. More API providers adopting x402, additional chains beyond Base and Solana, standardization of payment headers and response formats.
Agent sophistication. As x402 matures, expect agents that automatically discover and compose multiple paid endpoints, optimize costs across providers, and negotiate better rates for bulk usage.
Disclosure
Educational content only, not financial advice. API usage and crypto payments carry risks. Verify all transactions before signing. Do your own research.
Opening Hook
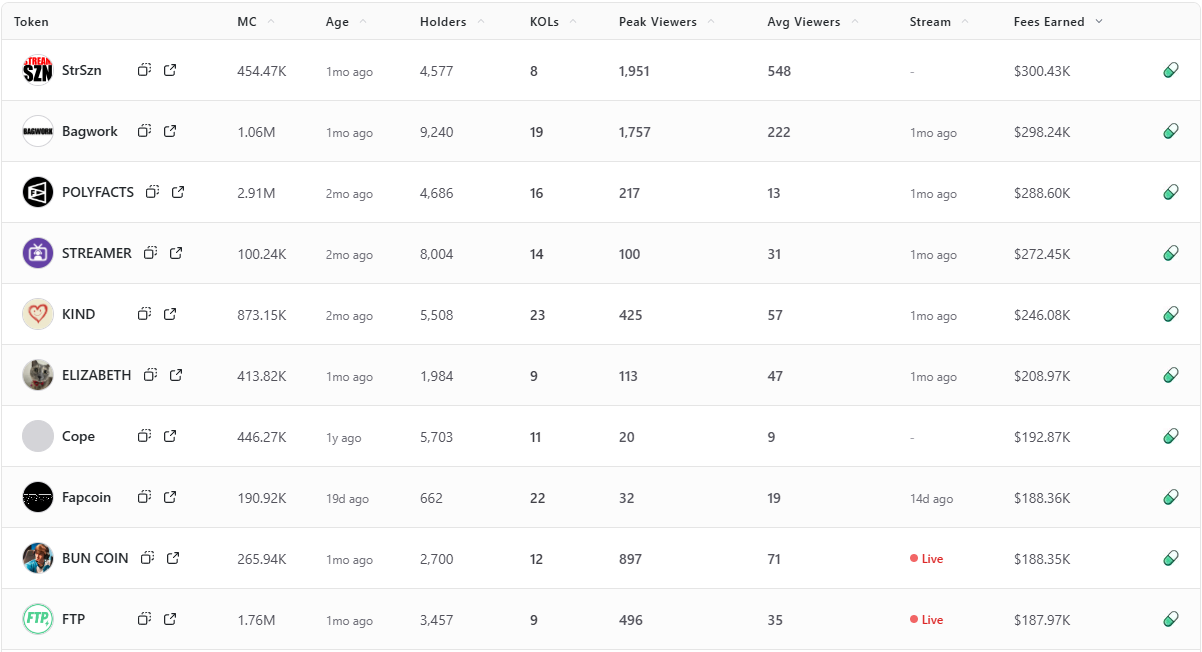
Fees Earned is a clean way to see which livestream tokens convert attention into on-chain activity. This leaderboard ranks the top 10 Pump.fun livestream tokens by Fees Earned using the screenshot you provided.
Selection rule is simple, top 10 by Fees Earned from the screenshot, numbers appear exactly as shown. If a field is not in the image, it is recorded as —.
Entity coverage: project names and tickers are taken as listed on Pump.fun, chain is Solana, sector is livestream meme tokens and creator tokens.
Token Metrics Live (TMLIVE) brings real time, data driven crypto market analysis to Pump.fun. The team has produced live crypto content for 7 years with a 500K plus audience and a platform of more than 100,000 users. Our public track record includes early coverage of winners like MATIC and Helium in 2018.
TMLIVE Quick Stats, as captured
TLDR: Fees Earned Leaders at a Glance
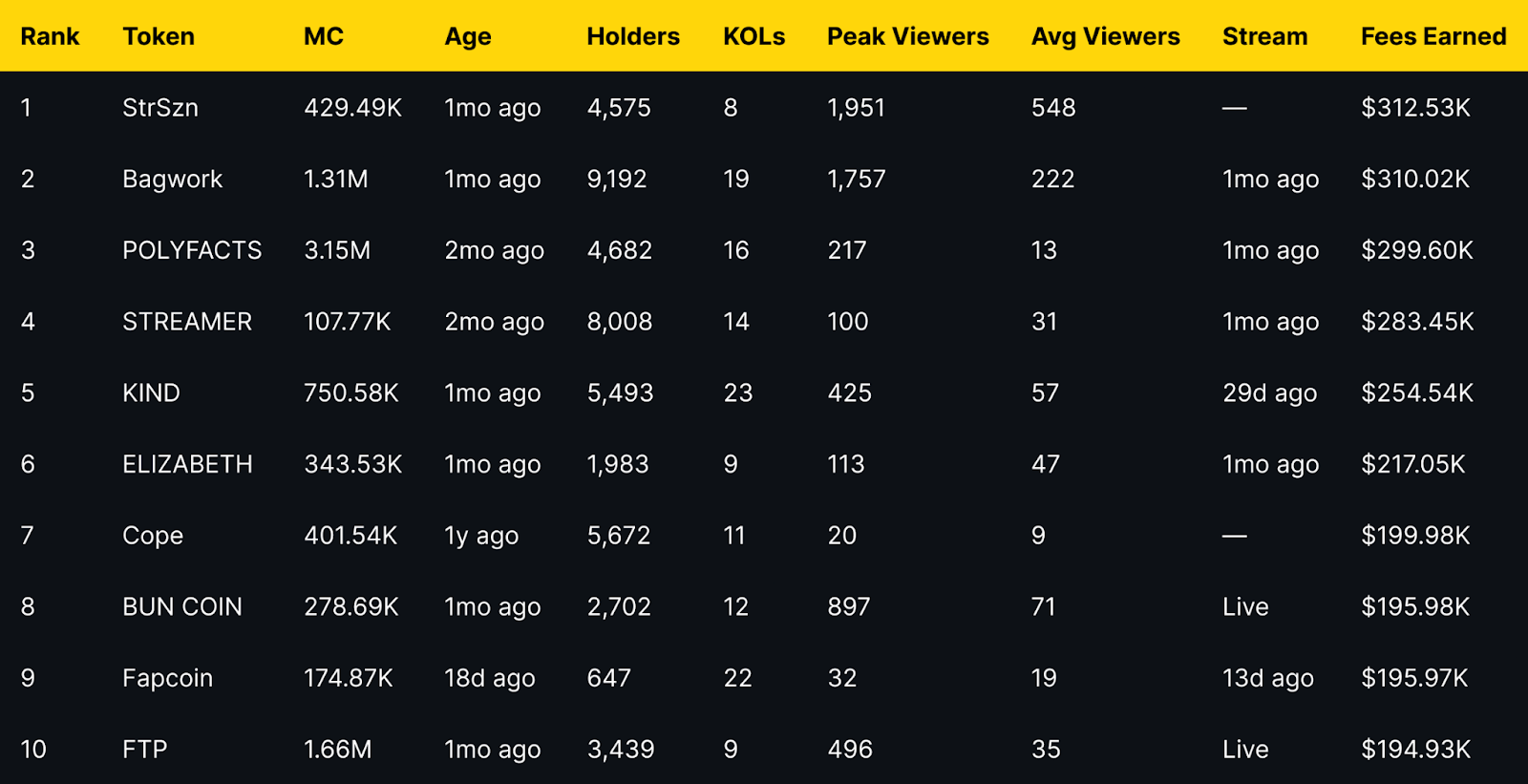
Short distribution note: the top three sit within a narrow band of each other, while mid-table tokens show a mix of older communities and recent streams. Several names with modest average viewers still appear due to concentrated activity during peaks.
StrSzn
Positioning: Active community meme with consistent viewer base.
Research Blurb: Project details unclear at time of writing. Fees and viewership suggest consistent stream engagement over the last month.
Quick Facts: Chain = Solana, Status = —, Peak Viewers = 1,951, Avg Viewers = 548.
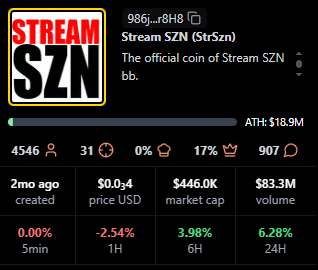
https://pump.fun/coin/986j8mhmidrcbx3wf1XJxsQFvWBMXg7gnDi3mejsr8H8
Bagwork
Positioning: Large holder base with sustained attention.
Research Blurb: Project details unclear at time of writing. Strong holders and KOL presence supported steady audience numbers.
Quick Facts: Chain = Solana, Status = 1mo ago, Holders = 9,192, KOLs = 19.

https://pump.fun/coin/7Pnqg1S6MYrL6AP1ZXcToTHfdBbTB77ze6Y33qBBpump
POLYFACTS
Positioning: Higher market cap with light average viewership.
Research Blurb: Project details unclear at time of writing. High market cap with comparatively low average viewers implies fees concentrated in shorter windows.
Quick Facts: Chain = Solana, Status = 1mo ago, MC = 3.15M, Avg Viewers = 13.
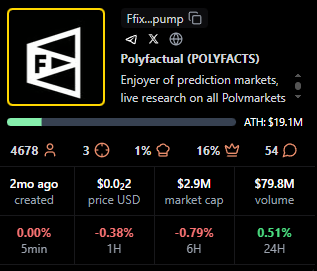
https://pump.fun/coin/FfixAeHevSKBZWoXPTbLk4U4X9piqvzGKvQaFo3cpump
STREAMER
Positioning: Community focused around streaming identity.
Research Blurb: Project details unclear at time of writing. Solid holders and moderate KOL count, steady averages over time.
Quick Facts: Chain = Solana, Status = 1mo ago, Holders = 8,008, KOLs = 14.

https://pump.fun/coin/3arUrpH3nzaRJbbpVgY42dcqSq9A5BFgUxKozZ4npump
KIND
Positioning: Heaviest KOL footprint in the top 10.
Research Blurb: Project details unclear at time of writing. The largest KOL count here aligns with above average view metrics and meaningful fees.
Quick Facts: Chain = Solana, Status = 29d ago, KOLs = 23, Avg Viewers = 57.

https://pump.fun/coin/V5cCiSixPLAiEDX2zZquT5VuLm4prr5t35PWmjNpump
ELIZABETH
Positioning: Mid-cap meme with consistent streams.
Research Blurb: Project details unclear at time of writing. Viewer averages and recency indicate steady presence rather than single spike behavior.
Quick Facts: Chain = Solana, Status = 1mo ago, Avg Viewers = 47, Peak Viewers = 113.
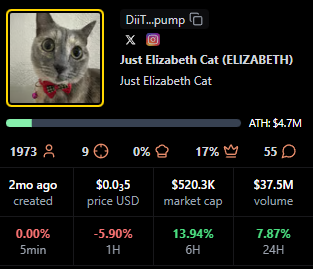
https://pump.fun/coin/DiiTPZdpd9t3XorHiuZUu4E1FoSaQ7uGN4q9YkQupump
Cope
Positioning: Older token with a legacy community.
Research Blurb: Project details unclear at time of writing. Despite low recent averages, it holds a sizable base and meaningful fees.
Quick Facts: Chain = Solana, Status = —, Age = 1y ago, Avg Viewers = 9.
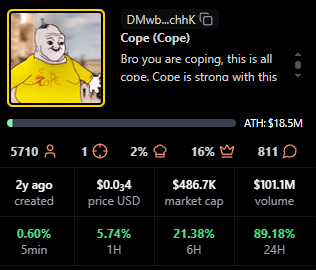
https://pump.fun/coin/DMwbVy48dWVKGe9z1pcVnwF3HLMLrqWdDLfbvx8RchhK
BUN COIN
Positioning: Currently live, strong peaks relative to size.
Research Blurb: Project details unclear at time of writing. Live streaming status often coincides with bursts of activity that lift fees quickly.
Quick Facts: Chain = Solana, Status = Live, Peak Viewers = 897, Avg Viewers = 71.

https://pump.fun/coin/HQDTzNa4nQVetoG6aCbSLX9kcH7tSv2j2sTV67Etpump
Fapcoin
Positioning: Newer token with targeted pushes.
Research Blurb: Project details unclear at time of writing. Recent age and meaningful KOL support suggest orchestrated activations that can move fees.
Quick Facts: Chain = Solana, Status = 13d ago, Age = 18d ago, KOLs = 22.

https://pump.fun/coin/8vGr1eX9vfpootWiUPYa5kYoGx9bTuRy2Xc4dNMrpump
FTP
Positioning: Live status with solid mid-table view metrics.
Research Blurb: Project details unclear at time of writing. Peaks and consistent averages suggest an active audience during live windows.
Quick Facts: Chain = Solana, Status = Live, Peak Viewers = 496, Avg Viewers = 35.
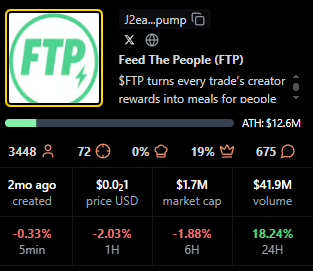
https://pump.fun/coin/J2eaKn35rp82T6RFEsNK9CLRHEKV9BLXjedFM3q6pump
Signals From Fees Earned: Patterns to Watch
Fees Earned often rise with peak and average viewers, but timing matters. Several tokens here show concentrated peaks with modest averages, which implies that well timed announcements or coordinated segments can still produce high fees.
Age is not a blocker for this board. Newer tokens like Fapcoin appear due to focused activity, while older names such as Cope persist by mobilizing established holders. KOL count appears additive rather than decisive, with KIND standing out as the KOL leader.
For creators, Fees Earned reflects whether livestream moments translate into on-chain action. Design streams around clear calls to action, align announcements with segments that drive peaks, then sustain momentum with repeatable formats that stabilize averages.
For traders, Fees Earned complements market cap, viewers, and age. Look for projects that combine rising averages with consistent peaks, because those patterns suggest repeatable engagement rather than single event spikes.
TV Live is a fast way to follow real-time crypto market news, creator launches, and token breakdowns as they happen. You get context on stream dynamics, audience behavior, and on-chain activity while the story evolves.
CTA: Watch TV Live for real-time crypto market news →TV Live Link
CTA: Follow and enable alerts → TV Live
Token Metrics is trusted for transparent data, crypto analytics, on-chain ratings, and investor education. Our platform offers cutting-edge signals and market research to empower your crypto investing decisions.
What is the best way to track Pump.fun livestream leaders?
Tracking Pump.fun livestream leaders starts with the scanner views that show Fees Earned, viewers, and KOLs side by side, paired with live coverage so you see data and narrative shifts together.
Do higher fees predict higher market cap or sustained viewership?
Higher Fees Earned does not guarantee higher market cap or sustained viewership, it indicates conversion in specific windows, while longer term outcomes still depend on execution and community engagement.
How often do these rankings change?
Rankings can change quickly during active cycles, the entries shown here reflect the exact time of the screenshot.
Next Steps
Disclosure
This article is educational content. Cryptocurrency involves risk. Always do your own research.
.svg)




.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.















































%20Price%20Prediction%202025%2C%202030%20-%20Forecast%20Analysis.png)

















.png)

%20Price%20Prediction%20.webp)









%20Price%20Prediction.webp)



%20Price%20Prediction%20Analysis%20-%20Can%20it%20Reach%20%24500%20in%20Future_.png)


















