


























.png)























.png)
.png)








.png)



.png)
%201%20(1).png)

.png)


.png)






.png)
.png)



.png)

















.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)


































































































.png)








.png)

.png)
.png)









.png)


.png)
.png)
.png)
.png)

.png)
.png)











Research
Top Crypto Trading Platforms in 2025
When it comes to crypto trading platforms, Token Metrics is not an exchange, but a crypto analytics and crypto trading intelligence platform powered by AI.
Token Metrics Team
10




%201.svg)
%201.svg)
Big news: We’re cranking up the heat on AI-driven crypto analytics with the launch of the Token Metrics API and our official SDK (Software Development Kit). This isn’t just an upgrade – it's a quantum leap, giving traders, hedge funds, developers, and institutions direct access to cutting-edge market intelligence, trading signals, and predictive analytics.
Crypto markets move fast, and having real-time, AI-powered insights can be the difference between catching the next big trend or getting left behind. Until now, traders and quants have been wrestling with scattered data, delayed reporting, and a lack of truly predictive analytics. Not anymore.
The Token Metrics API delivers 32+ high-performance endpoints packed with powerful AI-driven insights right into your lap, including:
Getting started with the Token Metrics API is simple:
At Token Metrics, we believe data should be decentralized, predictive, and actionable.
The Token Metrics API & SDK bring next-gen AI-powered crypto intelligence to anyone looking to trade smarter, build better, and stay ahead of the curve. With our official SDK, developers can plug these insights into their own trading bots, dashboards, and research tools – no need to reinvent the wheel.
The Layer 1 landscape is consolidating as users and developers gravitate to chains with clear specialization. Bitcoin Cash positions itself as a payment-focused chain with low fees and quick settlement for everyday usage.
The scenario projections below map potential outcomes for BCH across different total crypto market sizes. Base cases assume steady usage and listings, while moon scenarios factor in stronger liquidity and accelerated adoption.

Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to read it: Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline:
Token Metrics lead metric for Bitcoin Cash, cashtag $BCH, is a TM Grade of 54.81%, which translates to Neutral, and the trading signal is bearish, indicating short-term downward momentum. This implies Token Metrics views $BCH as mixed value long term: fundamentals look strong, while valuation and technology scores are weak, so upside depends on improvements in adoption or technical development. Market context: Bitcoin has been setting market direction, and with broader risk-off moves altcoins face pressure, which increases downside risk for $BCH in the near term.
Live details:
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Token Metrics scenarios span four market cap tiers, each representing different levels of crypto market maturity and liquidity:
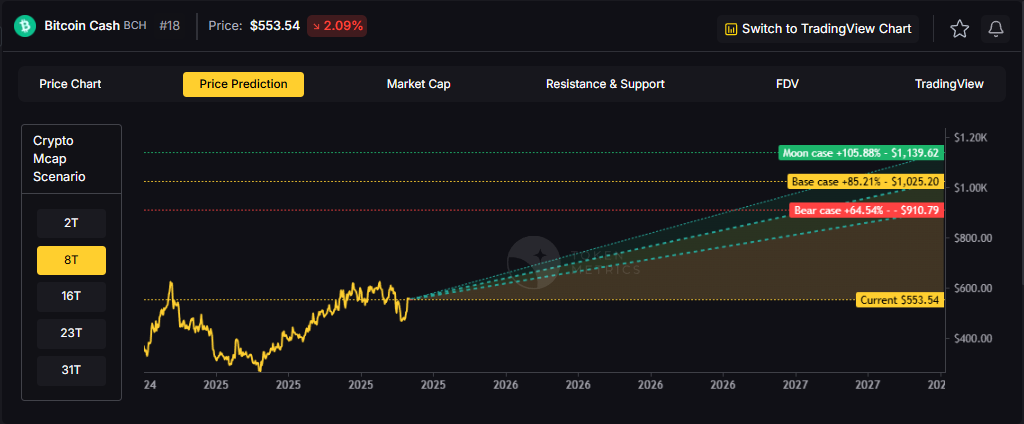


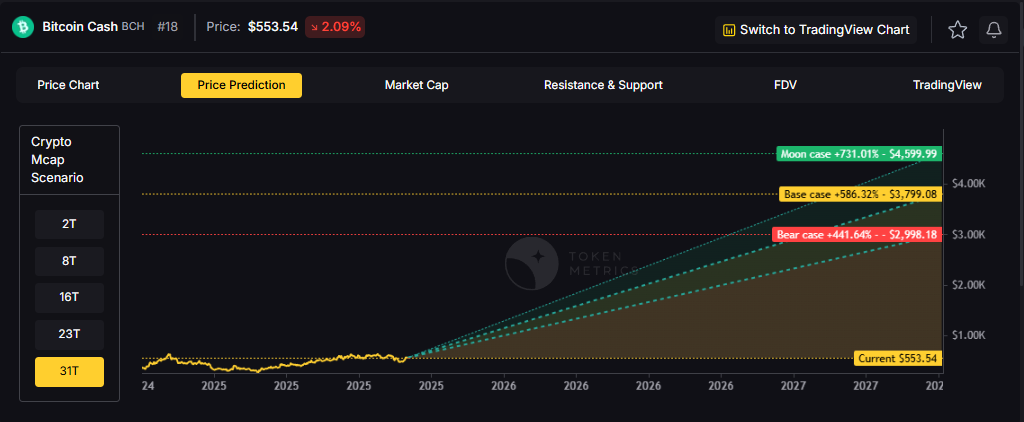
Each tier assumes progressively stronger market conditions, with the base case reflecting steady growth and the moon case requiring sustained bull market dynamics.
Bitcoin Cash represents one opportunity among hundreds in crypto markets. Token Metrics Indices bundle BCH with top one hundred assets for systematic exposure to the strongest projects. Single tokens face idiosyncratic risks that diversified baskets mitigate.
Historical index performance demonstrates the value of systematic diversification versus concentrated positions.
Bitcoin Cash is a peer-to-peer electronic cash network focused on fast confirmation and low fees. It launched in 2017 as a hard fork of Bitcoin with larger block capacity to prioritize payments. The chain secures value transfers using proof of work and aims to keep everyday transactions affordable.
BCH is used to pay transaction fees and settle transfers, and it is widely listed across major exchanges. Adoption centers on payments, micropayments, and remittances where low fees matter. It competes as a payment‑focused Layer 1 within the broader crypto market.
Token Metrics AI provides comprehensive context on Bitcoin Cash's positioning and challenges.
Vision:
Bitcoin Cash (BCH) is a cryptocurrency that emerged from a 2017 hard fork of Bitcoin, aiming to function as a peer-to-peer electronic cash system with faster transactions and lower fees. It is known for prioritizing on-chain scalability by increasing block sizes, allowing more transactions per block compared to Bitcoin. This design choice supports its use in everyday payments, appealing to users seeking a digital cash alternative. Adoption has been driven by its utility in micropayments and remittances, particularly in regions with limited banking infrastructure. However, Bitcoin Cash faces challenges including lower network security due to reduced mining hash rate compared to Bitcoin, and ongoing competition from both Bitcoin and other scalable blockchains. Its value proposition centers on accessibility and transaction efficiency, but it operates in a crowded space with evolving technological and regulatory risks.
Problem:
The project addresses scalability limitations in Bitcoin, where rising transaction fees and slow confirmation times hinder its use for small, frequent payments. As Bitcoin evolved into a store of value, a gap emerged for a blockchain-based currency optimized for fast, low-cost transactions accessible to the general public.
Solution:
Bitcoin Cash increases block size limits from 1 MB to 32 MB, enabling more transactions per block and reducing congestion. This on-chain scaling approach allows for faster confirmations and lower fees, making microtransactions feasible. The network supports basic smart contract functionality and replay protection, maintaining compatibility with Bitcoin's core architecture while prioritizing payment utility.
Market Analysis:
Bitcoin Cash operates in the digital currency segment, competing with Bitcoin, Litecoin, and stablecoins for use in payments and remittances. While not the market leader, it occupies a niche focused on on-chain scalability for transactional use. Its adoption is influenced by merchant acceptance, exchange liquidity, and narratives around digital cash. Key risks include competition from layer-2 solutions on other blockchains, regulatory scrutiny of cryptocurrencies, and lower developer and miner activity compared to larger networks. Price movements are often tied to broader crypto market trends and internal protocol developments. Despite its established presence, long-term growth depends on sustained utility, network security, and differentiation in a market increasingly dominated by high-throughput smart contract platforms.
Fundamental Grade: 80.41% (Community 62%, Tokenomics 100%, Exchange 100%, VC —, DeFi Scanner 72%).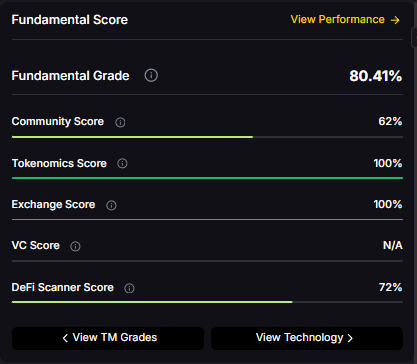
Technology Grade: 29.63% (Activity 22%, Repository 70%, Collaboration 48%, Security —, DeFi Scanner 72%).
Can BCH reach $3,000?
Based on the scenarios, BCH could reach $3,000 in the 23T moon case and 31T base case. The 23T tier projects $3,446.53 in the moon case. Not financial advice.
Can BCH 10x from current levels?
At current price of $553.54, a 10x would reach $5,535.40. This falls within the 31T base and moon cases. Bear in mind that 10x returns require substantial market cap expansion. Not financial advice.
Should I buy BCH now or wait?
Timing depends on your risk tolerance and macro outlook. Current price of $553.54 sits below the 8T bear case in our scenarios. Dollar-cost averaging may reduce timing risk. Not financial advice.
Want exposure? Buy BCH on MEXC
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
Infrastructure protocols become more valuable as the crypto ecosystem scales and relies on robust middleware. Chainlink provides critical oracle infrastructure where proven utility and deep integrations drive long-term value over retail speculation. Increasing institutional adoption raises demand for professional-grade data delivery and security.
Token Metrics projections for LINK below span multiple total market cap scenarios from conservative to aggressive. Each tier assumes different levels of infrastructure demand as crypto evolves from speculative markets to institutional-grade systems. These bands frame LINK's potential outcomes into 2027.

Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to read it: Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline: Token Metrics lead metric for Chainlink, cashtag $LINK, is a TM Grade of 23.31%, which translates to a Sell, and the trading signal is bearish, indicating short-term downward momentum. This means Token Metrics currently does not endorse $LINK as a long-term buy at current conditions.
Live details: Chainlink Token Details
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Token Metrics scenarios span four market cap tiers, each representing different levels of crypto market maturity and liquidity:
8T: At an 8 trillion dollar total crypto market cap, LINK projects to $26.10 in bear conditions, $30.65 in the base case, and $35.20 in bullish scenarios.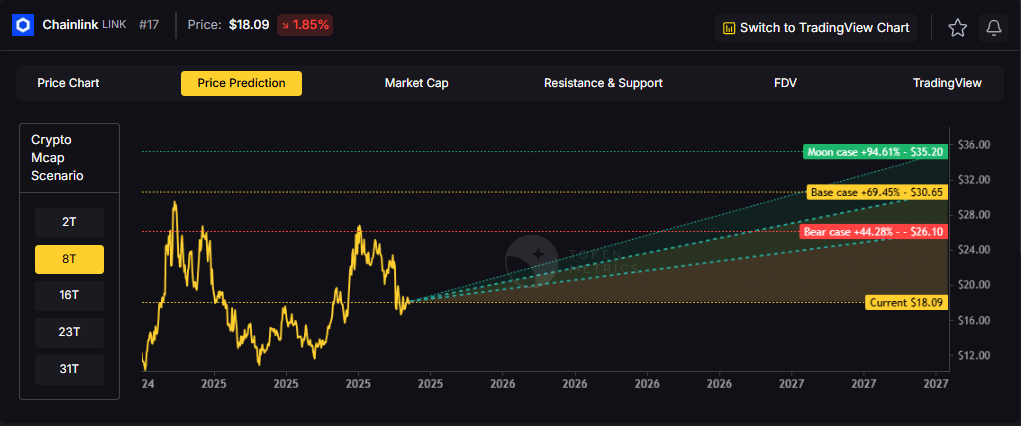
16T: Doubling the market to 16 trillion expands the range to $42.64 (bear), $56.29 (base), and $69.95 (moon).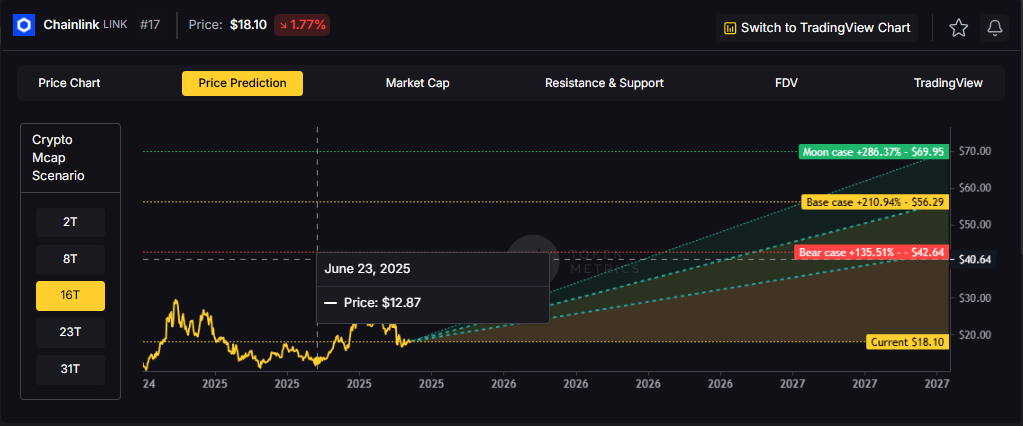
23T: At 23 trillion, the scenarios show $59.18, $81.94, and $104.70 respectively.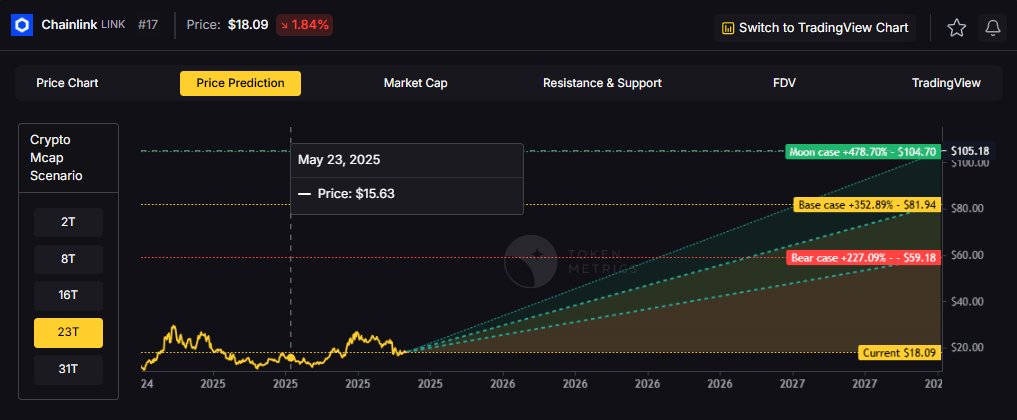
31T: In the maximum liquidity scenario of 31 trillion, LINK could reach $75.71 (bear), $107.58 (base), or $139.44 (moon).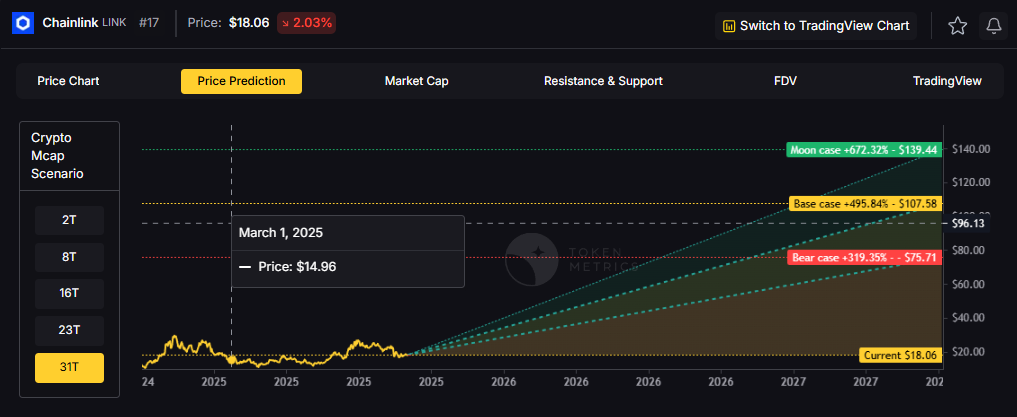
Chainlink represents one opportunity among hundreds in crypto markets. Token Metrics Indices bundle LINK with top one hundred assets for systematic exposure to the strongest projects. Single tokens face idiosyncratic risks that diversified baskets mitigate.
Historical index performance demonstrates the value of systematic diversification versus concentrated positions.
Chainlink is a decentralized oracle network that connects smart contracts to real-world data and systems. It enables secure retrieval and verification of off-chain information, supports computation, and integrates across multiple blockchains. As adoption grows, Chainlink serves as critical infrastructure for reliable data feeds and automation.
The LINK token is used to pay node operators and secure the network’s services. Common use cases include DeFi price feeds, insurance, and enterprise integrations, with CCIP extending cross-chain messaging and token transfers.
Vision: Chainlink aims to create a decentralized, secure, and reliable network for connecting smart contracts with real-world data and systems. Its vision is to become the standard for how blockchains interact with external environments, enabling trust-minimized automation across industries.
Problem: Smart contracts cannot natively access data outside their blockchain, limiting their functionality. Relying on centralized oracles introduces single points of failure and undermines the security and decentralization of blockchain applications. This creates a critical need for a trustless, tamper-proof way to bring real-world information onto blockchains.
Solution: Chainlink solves this by operating a decentralized network of node operators that fetch, aggregate, and deliver data from off-chain sources to smart contracts. It uses cryptographic proofs, reputation systems, and economic incentives to ensure data integrity. The network supports various data types and computation tasks, allowing developers to build complex, data-driven decentralized applications.
Market Analysis: Chainlink is a market leader in the oracle space and a key infrastructure component in the broader blockchain ecosystem, particularly within Ethereum and other smart contract platforms. It faces competition from emerging oracle networks like Band Protocol and API3, but maintains a strong first-mover advantage and widespread integration across DeFi, NFTs, and enterprise blockchain solutions. Adoption is driven by developer activity, partnerships with major blockchain projects, and demand for secure data feeds. Key risks include technological shifts, regulatory scrutiny on data providers, and execution challenges in scaling decentralized oracle networks. As smart contract usage grows, so does the potential for oracle services, positioning Chainlink at the center of a critical niche, though its success depends on maintaining security and decentralization over time.
Fundamental Grade: 74.58% (Community 81%, Tokenomics 100%, Exchange 100%, VC —, DeFi Scanner 17%).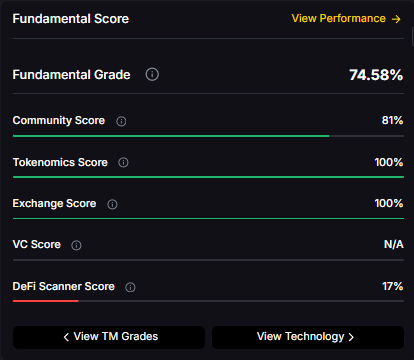
Technology Grade: 88.50% (Activity 81%, Repository 72%, Collaboration 100%, Security 86%, DeFi Scanner 17%).
Can LINK reach $100?
Yes. Based on the scenarios, LINK could reach $100+ in the 23T moon case. The 23T tier projects $104.70 in the moon case. Not financial advice.
What price could LINK reach in the moon case?
Moon case projections range from $35.20 at 8T to $139.44 at 31T. These scenarios assume maximum liquidity expansion and strong Chainlink adoption. Not financial advice.
Should I buy LINK now or wait?
Timing depends on risk tolerance and macro outlook. Current price of $18.09 sits below the 8T bear case in the scenarios. Dollar-cost averaging may reduce timing risk. Not financial advice.
Track live grades and signals: Token Details
Want exposure? Buy LINK on MEXC
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
Discover the full potential of your crypto research and portfolio management with Token Metrics. Our ratings combine AI-driven analytics, on-chain data, and decades of investing expertise—giving you the edge to navigate fast-changing markets. Try our platform to access scenario-based price targets, token grades, indices, and more for institutional and individual investors. Token Metrics is your research partner through every crypto market cycle.
The crypto market is tilting bullish into 2026 as liquidity, infrastructure, and participation improve across the board. Clearer rules and standards are reshaping the classic four-year cycle, flows can arrive earlier, and strength can persist longer than in prior expansions.
Institutional access is widening through ETFs and custody, while L2 scaling and real-world integrations help sustain on‑chain activity. This healthier backdrop frames our scenario work for HYPE. The ranges below reflect different total crypto market sizes and the share Hyperliquid could capture under each regime.
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to read it: Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline: Token Metrics TM Grade is 73.9%, a Buy, and the trading signal is bearish, indicating short-term downward momentum. This means Token Metrics judges HYPE as fundamentally attractive over the long term, while near-term momentum is negative and may limit rallies.
Live details: Hyperliquid Token Details
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Scenario Analysis
Token Metrics scenarios span four market cap tiers, each representing different levels of crypto market maturity and liquidity:
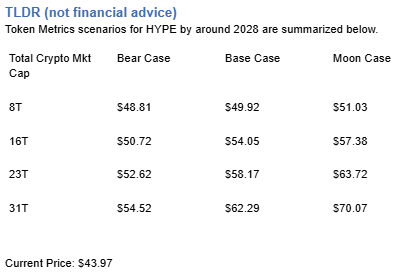
8T: At an 8 trillion dollar total crypto market cap, HYPE projects to $48.81 in bear conditions, $49.92 in the base case, and $51.03 in bullish scenarios.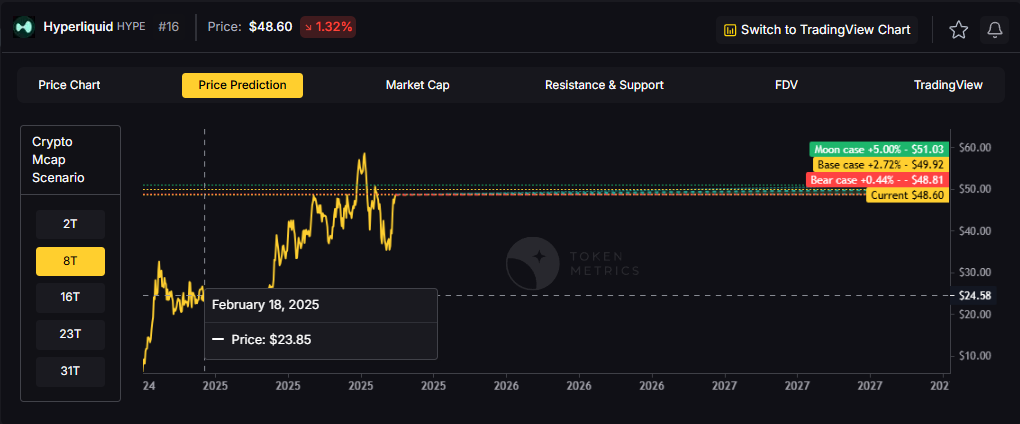
16T: Doubling the market to 16 trillion expands the range to $50.72 (bear), $54.05 (base), and $57.38 (moon).
23T: At 23 trillion, the scenarios show $52.62, $58.17, and $63.72 respectively.
31T: In the maximum liquidity scenario of 31 trillion, HYPE could reach $54.52 (bear), $62.29 (base), or $70.07 (moon).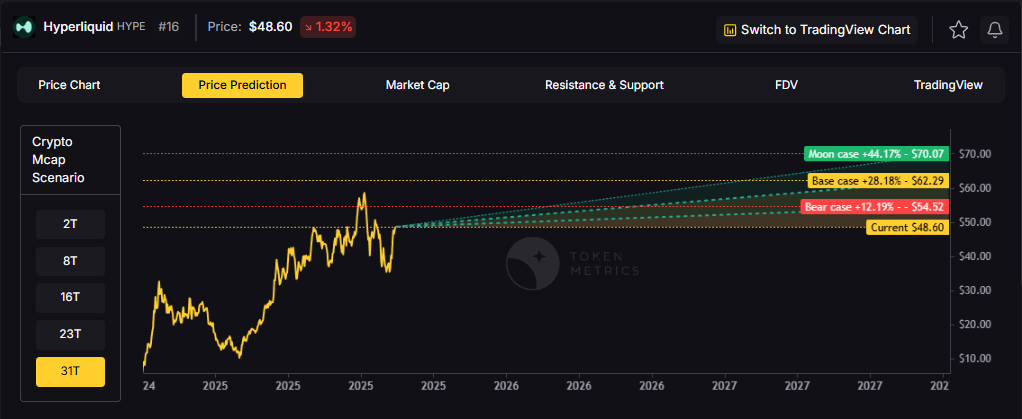
Each tier assumes progressively stronger market conditions, with the base case reflecting steady growth and the moon case requiring sustained bull market dynamics.
Diversification matters. HYPE is compelling, yet concentrated bets can be volatile. Token Metrics Indices hold HYPE alongside the top one hundred tokens for broad exposure to leaders and emerging winners.
Our backtests indicate that owning the full market with diversified indices has historically outperformed both the total market and Bitcoin in many regimes due to diversification and rotation.
Hyperliquid is a decentralized exchange focused on perpetual futures with a high-performance order book architecture. The project emphasizes low-latency trading, risk controls, and capital efficiency aimed at professional and retail derivatives traders. Its token, HYPE, is used for ecosystem incentives and governance-related utilities.
Can HYPE reach $60?
Yes, the 23T and 31T tiers imply ranges above $60 in the Base and Moon bands, though outcomes depend on liquidity and adoption. Not financial advice.
Is HYPE a good long-term investment?
Outcome depends on adoption, liquidity regime, competition, and supply dynamics. Diversify and size positions responsibly.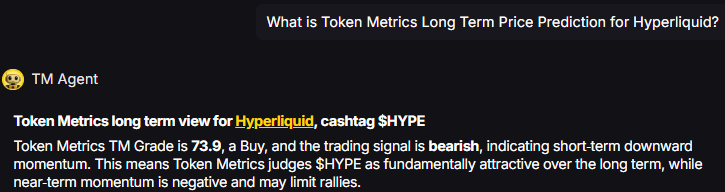
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
Token Metrics delivers AI-based crypto ratings, scenario projections, and portfolio tools so you can make smarter decisions. Discover real-time analytics on Token Metrics.

APIs are the connective tissue of modern applications; among them, RESTful APIs remain a dominant style because they map cleanly to HTTP semantics and scale well across distributed systems. This article breaks down what a RESTful API is, pragmatic design patterns, security controls, and practical monitoring and testing workflows. If you build or consume APIs, understanding these fundamentals reduces integration friction and improves reliability.
A RESTful API (Representational State Transfer) is an architectural style for designing networked applications. At its core, REST leverages standard HTTP verbs (GET, POST, PUT, PATCH, DELETE) and status codes to perform operations on uniquely identified resources, typically represented as URLs. Key characteristics include:
REST is a pragmatic guideline rather than a strict protocol; many APIs labeled "RESTful" adopt REST principles while introducing pragmatic extensions (e.g., custom headers, versioning strategies).
Good REST design begins with clear resource modeling. Ask: what are the nouns in the domain, and how do they relate? Use predictable URL structures and rely on HTTP semantics:
Design tips to improve usability and longevity:
Security is a primary concern for any public-facing API. Typical controls and patterns include:
Designing for security also means operational readiness: automated certificate rotation, secrets management, and periodic security reviews reduce long-term risk.
Performance tuning for RESTful APIs covers latency, throughput, and reliability. Practical strategies include caching (HTTP Cache-Control, ETags), connection pooling, and database query optimization. Use observability tools to collect metrics (error rates, latency percentiles), distributed traces, and structured logs for rapid diagnosis.
AI-assisted tools can accelerate many aspects of API development and operations: anomaly detection in request patterns, automated schema inference from traffic, and intelligent suggestions for endpoint design or documentation. While these tools improve efficiency, validate automated changes through testing and staged rollouts.
When selecting tooling, evaluate clarity of integrations, support for your API architecture, and the ability to export raw telemetry for custom analysis.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
REST focuses on resources and uses HTTP semantics; GraphQL centralizes queries into a single endpoint with flexible queries, and gRPC emphasizes high-performance RPCs with binary protocols. Choose based on client needs, performance constraints, and schema evolution requirements.
Common approaches include URL versioning (e.g., /v1/), header-based versioning, or semantic versioning of the API contract. Regardless of method, document deprecation timelines and provide migration guides and compatibility layers where possible.
Combine unit tests for business logic with integration tests that exercise endpoints and mocks for external dependencies. Use contract tests to ensure backward compatibility and end-to-end tests in staging environments. Automate tests in CI/CD to catch regressions early.
Additive changes (new fields, endpoints) are generally safe; avoid removing fields, changing response formats, or repurposing status codes. Feature flags and content negotiation can help introduce changes progressively.
Provide clear endpoint descriptions, request/response examples, authentication steps, error codes, rate limits, and code samples in multiple languages. Machine-readable specs (OpenAPI/Swagger) enable client generation and testing automation.
Disclaimer: This content is educational and informational only. It does not constitute professional, legal, security, or investment advice. Test and validate any architectural, security, or operational changes in environments that match your production constraints before rollout.

The Claude API is increasingly used to build context-aware AI assistants, document summarizers, and conversational workflows. This guide breaks down what the API offers, integration patterns, capability trade-offs, and practical safeguards to consider when embedding Claude models into production systems.
The Claude API exposes access to Anthropic’s Claude family of large language models. At a high level, it lets developers send prompts and structured instructions and receive text outputs, completions, or assistant-style responses. Key delivery modes typically include synchronous completions, streaming tokens for low-latency interfaces, and tools for handling multi-turn context. Understanding input/output semantics and token accounting is essential before integrating Claude into downstream applications.
Claude models are designed for safety-focused conversational AI and often emphasize instruction following and helpfulness while applying content filters. Typical features to assess:
Designing a robust integration with the Claude API means balancing performance, cost, and safety. Practical guidance:
Claude API use cases span chat assistants, summarization, prompt-driven code generation, and domain-specific Q&A. For each area evaluate these risk vectors:
Tooling around Claude often mirrors other LLM APIs: HTTP/SDK clients, streaming libraries, and orchestration frameworks. Combine the Claude API with retrieval-augmented generation (RAG) systems, vector stores for semantic search, and lightweight caching layers. AI-driven research platforms such as Token Metrics can complement model outputs by providing analytics and signal overlays when integrating market or on-chain data into prompts.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
The Claude API is an interface for sending prompts and receiving text-based model outputs from the Claude family. It supports completions, streaming responses, and multi-turn conversations, depending on the provider’s endpoints.
Implement a retrieval-augmented generation (RAG) approach: index documents into a vector store, use semantic search to fetch relevant segments, and summarize or stitch results before sending a concise prompt to Claude. Also consider chunking and progressive summarization when documents exceed context limits.
Optimize prompts to be concise, cache common responses, batch non-interactive requests, and choose lower-capacity model variants for non-critical tasks. Monitor token usage and set alerts for unexpected spikes.
Combine Claude’s built-in safety mechanisms with application-level filters, content validation, and human review workflows. Avoid sending regulated or sensitive data without proper agreements and minimize reliance on unverified outputs.
Use streaming for interactive chat interfaces where perceived latency matters. Batch completions are suitable for offline processing, analytics, and situations where full output is required before downstream steps.
This article is for educational purposes only and does not constitute professional, legal, or financial advice. It explains technical capabilities and integration considerations for the Claude API without endorsing specific implementations. Review service terms, privacy policies, and applicable regulations before deploying AI systems in production.

Every modern integration — from a simple weather widget to a crypto analytics agent — relies on API credentials to authenticate requests. An api key is one of the simplest and most widely used credentials, but simplicity invites misuse. This article explains what an api key is, how it functions, practical security patterns, and how developers can manage keys safely in production.
An api key is a short token issued by a service to identify and authenticate an application or user making an HTTP request. Unlike full user credentials, api keys are typically static strings passed as headers, query parameters, or request bodies. On the server side, the receiving API validates the key against its database, checks permissions and rate limits, and then either serves the request or rejects it.
Technically, api keys are a form of bearer token: possession of the key is sufficient to access associated resources. Because they do not necessarily carry user-level context or scopes by default, many providers layer additional access-control mechanisms (scopes, IP allowlists, or linked user tokens) to reduce risk.
API keys are popular because they are easy to generate and integrate: you create a key in a dashboard and paste it into your application. Typical use cases include server-to-server integrations, analytics pulls, and third-party widgets. In crypto and AI applications, keys often control access to market data, trading endpoints, or model inference APIs.
Limitations: api keys alone lack strong cryptographic proof of origin (compared with signed requests), are vulnerable if embedded in client-side code, and can be compromised if not rotated. For higher-security scenarios, consider combining keys with stronger authentication approaches like OAuth 2.0, mutual TLS, or request signing.
Secure handling of api keys reduces the chance of leak and abuse. Key best practices include:
These patterns are practical to implement: for example, many platforms offer scoped keys and rotation APIs so you can automate revocation and issuance without manual intervention.
Crypto data feeds, trading APIs, and model inference endpoints commonly require api keys. In these contexts, the attack surface often includes automated agents, cloud functions, and browser-based dashboards. Treat any key embedded in an agent as potentially discoverable and design controls accordingly.
Operational tips for crypto and AI projects:
Platforms such as Token Metrics provide APIs tailored to crypto research and can be configured with scoped keys for safe consumption in analytics pipelines and AI agents.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
An api key is a token that applications send with requests to identify and authenticate themselves to a service. It is often used for simple authentication, usage tracking, and applying access controls such as rate limits.
Store api keys outside of code: use environment variables, container secrets, or a managed secrets store. Ensure access to those stores is role-restricted and audited. Never commit keys to public repositories or client-side bundles.
API keys are static identifiers primarily for application-level authentication. OAuth tokens represent delegated user authorization and often include scopes and expiration. OAuth is generally more suitable for user-centric access control, while api keys are common for machine-to-machine interactions.
Rotation frequency depends on risk tolerance and exposure: a common pattern is scheduled rotation every 30–90 days, with immediate rotation upon suspected compromise. Automate the rotation process to avoid service interruptions.
Watch for abnormal usage patterns: sudden spikes in requests, calls from unexpected IPs or geographic regions, attempts to access endpoints outside expected scopes, or errors tied to rate-limit triggers. Configure alerts for such anomalies.
Many providers allow IP allowlisting or referrer restrictions. This reduces the attack surface by ensuring keys only work from known servers or client domains. Use this in combination with short lifetimes and least-privilege scopes.
AI agents that call external services should use securely stored keys injected at runtime. Limit their permissions to only what the agent requires, rotate keys regularly, and monitor agent activity to detect unexpected behavior.
This article is educational and informational in nature. It is not investment, legal, or security advice. Evaluate any security approach against your project requirements and consult qualified professionals for sensitive implementations.

Location data powers modern products: discovery, logistics, analytics, and personalized experiences all lean on accurate mapping services. The Google Maps API suite is one of the most feature-rich options for embedding maps, geocoding addresses, routing vehicles, and enriching UX with Places and Street View. This guide breaks the platform down into practical sections—what each API does, how to get started securely, design patterns to control costs and latency, and where AI can add value.
The Maps Platform is modular: you enable only the APIs and SDKs your project requires. Key components include:
Each API exposes different latency, quota, and billing characteristics. Plan around the functional needs (display vs. heavy batch geocoding vs. real-time routing).
Begin in the Google Cloud Console: create or select a project, enable the specific Maps Platform APIs your app requires, and generate an API key. Key operational steps:
Authentication and identity management are foundational—wider access means higher risk of unexpected charges and data leakage.
Successful integrations optimize performance, cost, and reliability. Consider these patterns:
The Maps Platform uses a pay-as-you-go model with billing tied to API calls, SDK sessions, or map loads depending on the product. To control costs:
Budgeting requires monitoring real usage patterns and aligning product behavior (e.g., map refresh frequency) with cost objectives.
Combining location APIs with machine learning unlocks advanced features: predictive ETA models, demand heatmaps, intelligent geofencing, and dynamic routing that accounts for historic traffic patterns. AI models can also enrich POI categorization from Places API results or prioritize search results based on user intent.
For teams focused on research and signals, AI-driven analytical tools can help surface patterns from large location datasets, cluster user behavior, and integrate external data feeds for richer context. Tools built for crypto and on-chain analytics illustrate how API-driven datasets can be paired with models to create actionable insights in other domains—similarly, map and location data benefit from model-driven enrichment that remains explainable and auditable.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
Google offers a free usage tier and a recurring monthly credit for Maps Platform customers. Beyond the free allocation, usage is billed based on API calls, map loads, or SDK sessions. Monitor your project billing and set alerts to avoid unexpected charges.
The Places API provides address and place autocomplete features tailored for UX-focused address entry. For server-side address validation or bulk geocoding, pair it with Geocoding APIs and implement server-side caching.
Apply application restrictions (HTTP referrers for web, package name & SHA-1 for Android, bundle ID for iOS) and limit the key to only the required APIs. Rotate keys periodically and keep production keys out of client-side source control when possible.
Yes—the Directions and Distance Matrix APIs support routing and travel-time estimates. For large-scale fleet optimization, consider server-side batching, rate-limit handling, and hybrid solutions that combine routing APIs with custom optimization logic to manage complexity and cost.
Common issues include unbounded API keys, lack of caching for geocoding, excessive map refreshes that drive costs, and neglecting offline/mobile behavior. Planning for quotas, testing under realistic loads, and instrumenting telemetry mitigates these pitfalls.
This article is for educational and technical information only. It does not constitute financial, legal, or professional advice. Evaluate features, quotas, and pricing on official Google documentation and consult appropriate professionals for specific decisions.

Discord's API is the backbone of modern community automation, moderation, and integrations. Whether you're building a utility bot, connecting an AI assistant, or streaming notifications from external systems, understanding the Discord API's architecture, constraints, and best practices helps you design reliable, secure integrations that scale.
The Discord API exposes two main interfaces: the Gateway (a persistent WebSocket) for real-time events and the REST API for one-off requests such as creating messages, managing channels, and configuring permissions. Together they let developers build bots and services that respond to user actions, post updates, and manage server state.
Key concepts to keep in mind:
Authentication is based on tokens. Bots use a bot token (issued in the Discord Developer Portal) to authenticate both the Gateway and REST calls. When building or auditing a bot, treat tokens like secrets: rotate them when exposed and store them securely in environment variables or a secrets manager.
Intents let you opt-in to categories of events. For example, message content intent is required to read message text in many cases. Use the principle of least privilege: request only the intents you need to reduce data exposure and improve performance.
Practical steps:
Rate limits are enforced per route and per global bucket. Familiarize yourself with the headers returned by the REST API (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset) and adopt respectful retry strategies. For Gateway connections, avoid rapid reconnects; follow exponential backoff and obey the recommended identify rate limits.
Design patterns to improve resilience:
Webhooks are lightweight for sending messages into channels without a bot token and are excellent for notifications from external systems. Interactions and slash commands provide structured, discoverable commands that integrate naturally into the Discord UI.
Best practices when using webhooks and interactions:
Security goes beyond token handling. Consider these areas:
Combining Discord bots with AI or external data APIs can produce helpful automation, moderation aids, or analytics dashboards. When integrating, separate concerns: keep the Discord-facing layer thin and stateless where possible, and offload heavy processing to dedicated services.
For crypto- and market-focused integrations, external APIs can supply price feeds, on-chain indicators, and signals which your bot can surface to users. AI-driven research platforms such as Token Metrics can augment analysis by providing structured ratings and on-chain insights that your integration can query programmatically.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
Begin by creating an application in the Discord Developer Portal, add a bot user, and generate a bot token. Choose a client library (for example discord.js, discord.py alternatives) to handle Gateway and REST interactions. Test in a private server before inviting to production servers.
Intents are event categories that determine which events the Gateway will send to your bot. Enable only the intents your features require. Some intents, like message content, are privileged and require justification for larger bots or those in many servers.
Respect rate-limit headers, use client libraries that implement request queues, batch operations when possible, and shard your bot appropriately. Implement exponential backoff for retries and monitor request patterns to identify hotspots.
Webhooks are simpler for sending messages from external systems because they don't require a bot token and have a low setup cost. Bots are required for interactive features, slash commands, moderation, and actions that require user-like behavior.
Validate interaction signatures using Discord's public key. Verify timestamps to prevent replay attacks and ensure your endpoint only accepts expected request types. Keep validation code in middleware for consistency.
This article is educational and technical in nature. It does not provide investment, legal, or financial advice. Implementations described here focus on software architecture, integration patterns, and security practices; adapt them to your own requirements and compliance obligations.

APIs power much of the software and services we use every day, but the acronym itself can seem abstract to newcomers. This guide answers the simple question "what does API stand for," explains the main types and patterns, and shows how developers, analysts, and researchers use APIs—especially in data-rich fields like crypto and AI—to access information and automate workflows.
API stands for Application Programming Interface. In practice, an API is a set of rules and protocols that lets one software component request services or data from another. It defines how requests should be formatted, what endpoints are available, what data types are returned, and which authentication methods are required.
Think of an API as a contract between systems: the provider exposes functionality or data, and the consumer calls that functionality using an agreed syntax. This contract enables interoperability across languages, platforms, and teams without sharing internal implementation details.
APIs come in several flavors depending on purpose and architecture. Understanding these helps you choose the right integration approach:
In domains like crypto, API types often include REST endpoints for historical data, WebSocket endpoints for live market updates, and specialized endpoints for on-chain data and analytics.
APIs unlock automation and integration across many workflows. Typical examples include:
For researchers and developers in crypto and AI, APIs enable programmatic access to prices, on-chain metrics, and model outputs. Tools that combine multiple data sources through APIs can accelerate analysis while maintaining reproducibility.
APIs must be designed with security and reliability in mind. Key considerations include:
Designing or choosing APIs with clear documentation, sandbox environments, and predictable SLAs reduces integration friction and downstream maintenance effort.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
API stands for Application Programming Interface. It is a defined set of rules that enables software to communicate and exchange data or functionality with other software components.
An API is a specification for interaction; a library or SDK is an implementation that exposes an API in a specific programming language. Libraries call APIs internally or provide convenience wrappers for API calls.
Use REST for simple, resource-oriented endpoints and predictable cacheable interactions. Use GraphQL when clients require flexible, tailored queries and want to minimize round trips for composite data needs.
Rate limits cap how many requests a client can make in a given period. Respecting limits with caching and backoff logic prevents service disruption and helps maintain reliable access.
Yes. Streaming and WebSocket APIs can deliver low-latency data feeds that serve as inputs to real-time models, while REST endpoints supply bulk or historical datasets used for training and backtesting.
Integration platforms, API gateways, and orchestration tools manage authentication, rate limiting, retries, and transformations. For crypto and AI workflows, data aggregation services and programmatic APIs speed analysis.
Evaluate documentation, uptime reports, data coverage, authentication methods, and community usage. Platforms that combine market, on-chain, and research signals are especially useful for analytical workflows.
Official style guides, API design books, and public documentation from major providers (Google, GitHub, Stripe) offer practical patterns for versioning, security, and documentation.
Disclaimer: This article is educational and informational only. It does not constitute financial, legal, or investment advice. Readers should perform independent research and consult appropriate professionals for their specific needs.

ChatGPT API has become a foundational tool for building conversational agents, content generation pipelines, and AI-powered features across web and mobile apps. This guide walks through how the API works, common integration patterns, cost and performance considerations, prompt engineering strategies, and security and compliance checkpoints — all framed to help developers design reliable, production-ready systems.
The ChatGPT API exposes a conversational, instruction-following model through RESTful endpoints. It accepts structured inputs (messages, system instructions, temperature, max tokens) and returns generated messages and usage metrics. Key capabilities include multi-turn context handling, role-based prompts (system, user, assistant), and streaming responses for lower perceived latency.
When evaluating the API for a project, consider three high-level dimensions: functional fit (can it produce the outputs you need?), operational constraints (latency, throughput, rate limits), and cost model (token usage and pricing). Structuring experiments around these dimensions produces clearer decisions than ad-hoc prototyping.
At a technical level, the API exchanges conversational messages composed of roles and content. The model's input size is measured in tokens, not characters; both prompts and generated outputs consume tokens. Developers must account for:
Token-awareness is essential for cost control and designing concise prompts. Tools exist to estimate token counts for given strings; include these estimates in batching and truncation logic to prevent failed requests due to exceeding the context window.
Common patterns for integrating the ChatGPT API map to different functional requirements:
Select a pattern based on latency tolerance, concurrency requirements, and the need to control outputs with additional logic or verifiable sources.
Pricing for ChatGPT-style APIs typically ties to token usage and model selection. For production systems, optimize costs and performance by:
Measure end-to-end latency including network, model inference, and application processing. Use streaming when user-perceived latency matters; otherwise, batch requests for throughput efficiency.
Robust ChatGPT API usage blends engineering discipline with iterative evaluation:
Adopt iterative prompt tuning: A/B different system instructions, sampling temperatures, and max tokens while measuring relevance, correctness, and safety against representative datasets.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
The ChatGPT API is a conversational model endpoint for generating text based on messages and instructions. Use it when you need flexible, context-aware text generation such as chatbots, summarization, or creative writing assistants.
Tokens measure both input and output size. Longer prompts and longer responses increase token counts, which raises cost and can hit the model's context window limit. Optimize prompts and truncate history when necessary.
Implement client-side throttling, request queuing, exponential backoff on 429 responses, and prioritize critical requests. Monitor usage patterns and adjust concurrency to avoid hitting provider limits.
Start with a clear system instruction to set tone and constraints, use examples for format guidance, keep user prompts concise, and test iteratively. Templates and guardrails reduce variability in outputs.
Secure API keys (do not embed in client code), encrypt data in transit and at rest, anonymize sensitive user data when possible, and review provider data usage policies. Apply access controls and rotate keys periodically.
Use streaming to improve perceived responsiveness for chat-like experiences or long outputs. Streaming reduces time-to-first-token and allows progressive rendering in UIs.
This article is for informational and technical guidance only. It does not constitute legal, compliance, or investment advice. Evaluate provider terms and conduct your own testing before deploying models in production.

The OpenAI API has become a foundation for building modern AI applications, from chat assistants to semantic search and generative agents. This post breaks down how the API works, core endpoints, implementation patterns, operational considerations, and practical tips to get reliable results while managing cost and risk.
The OpenAI API exposes pre-trained and fine-tunable models through RESTful endpoints. At a high level, you send text or binary payloads and receive structured responses — completions, chat messages, embeddings, or file-based fine-tune artifacts. Communication is typically via HTTPS with JSON payloads. Authentication uses API keys scoped to your account, and responses include usage metadata to help with monitoring.
Understanding the data flow is useful: client app → API request (model, prompt, params) → model inference → API response (text, tokens, embeddings). Latency depends on model size, input length, and concurrency. Many production systems put the API behind a middleware layer to handle retries, caching, and prompt templating.
The API surface typically includes several core capabilities you should know when planning architecture:
Choosing the right endpoint depends on the use case: embeddings for search/indexing, chat for conversational interfaces, and fine-tuning for repetitive, domain-specific prompts where consistency matters.
Design patterns and practical tweaks reduce friction in real-world systems. Here are tested approaches:
For development workflows, maintain separate API keys and quotas for staging and production, and log both prompts and model responses (with privacy controls) to enable debugging and iterative improvement.
Operational concerns are often the difference between a prototype and a resilient product. Key considerations include:
Instrumenting observability — latency, error rates, token counts per request — lets you correlate model choices with operational cost and end-user experience.
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
Common issues include prompt ambiguity, hallucinations, token truncation, and rate-limit throttling. Mitigation strategies:
Run adversarial tests to discover brittle prompts and incorporate guardrails in your application logic.
For scale, separate concerns into layers: ingestion, retrieval/indexing, inference orchestration, and post-processing. Use a vector database for embeddings, a message queue for burst handling, and server-side orchestration for prompt composition and retries. Edge caching for static outputs reduces repeated calls for common queries.
Consider hybrid strategies where smaller models run locally for simple tasks and the API is used selectively for high-value or complex inferences to balance cost and latency.
Most implementations use API keys sent in an Authorization header. Keys must be protected server-side. Rotate keys periodically and restrict scopes where supported.
Embedding-optimized models produce dense vectors for semantic tasks. Chat or completion models prioritize dialogue coherence and instruction-following. Select based on task: search and retrieval use embeddings; conversational agents use chat endpoints.
Use caching, smaller models for simple tasks, pre-compute embeddings for common queries, and implement warm-up strategies. Also evaluate regional endpoints and keep payload sizes minimal to reduce round-trip time.
Curate high-quality, representative datasets. Keep prompts consistent between fine-tuning and inference. Monitor for overfitting and validate on held-out examples to ensure generalization.
Track token usage by endpoint and user journey, set per-key quotas, and sample outputs rather than logging everything. Use batching and caching to reduce repeated calls, and enforce strict guards on long or recursive prompts.
Yes, with careful design. Add retries, fallbacks, safety checks, and human-in-the-loop reviews for high-stakes outcomes. Maintain SLAs that reflect model performance variability and instrument monitoring for regressions.
This article is for educational purposes only. It explains technical concepts, implementation patterns, and operational considerations related to the OpenAI API. It does not provide investment, legal, or regulatory advice. Always review provider documentation and applicable policies before deploying systems.

DeepSeek API has emerged as a specialized toolkit for developers and researchers who need granular, semantically rich access to crypto-related documents, on-chain data, and developer content. This article breaks down how the DeepSeek API works, common integration patterns, practical research workflows, and how AI-driven platforms can complement its capabilities without making investment recommendations.
The DeepSeek API is designed to index and retrieve contextual information across heterogeneous sources: whitepapers, GitHub repos, forum threads, on-chain events, and more. Unlike keyword-only search, DeepSeek focuses on semantic matching—returning results that align with the intent of a query rather than only literal token matches.
Key capabilities typically include:
Integrating the DeepSeek API into a product follows common design patterns depending on latency and scale requirements:
When building integrations, consider privacy, data retention, and whether you need to host a private index versus relying on a hosted DeepSeek endpoint.
Researchers using the DeepSeek API can follow a repeatable workflow to ensure comprehensive coverage and defensible results:
For reproducible experiments, version your query templates and save query-result sets alongside analysis notes.
Understanding the constraints of a semantic retrieval API is essential for reliable outputs:
Build Smarter Crypto Apps & AI Agents with Token Metrics
Token Metrics provides real-time prices, trading signals, and on-chain insights all from one powerful API. Grab a Free API Key
DeepSeek typically indexes a mix of developer-centric and community data: GitHub, whitepapers, documentation sites, forums, and on-chain events. Exact coverage depends on the provider's ingestion pipeline and configuration options you choose when provisioning indexes.
Embeddings map text into vector space where semantic similarity becomes measurable as geometric closeness. This allows queries to match documents by meaning rather than shared keywords, improving recall for paraphrased or conceptually related content.
While DeepSeek is optimized for textual retrieval, many deployments support linking to structured on-chain records. A common pattern is to return document results with associated on-chain references (contract addresses, event IDs) so downstream systems can fetch transaction-level details from block explorers or node APIs.
Use a combination of automated metrics (precision@k, recall sampling) and human review. For technical subjects, validate excerpts against source code, transaction logs, and authoritative docs to avoid false positives driven by surface-level similarity.
Keep retrieved context concise and relevant: prioritize high-salience chunks, include provenance for factual checks, and use retrieval augmentation to ground model outputs. Also, monitor token usage and prefer compressed summaries for long sources.
DeepSeek is focused on semantic retrieval and contextual search, while other crypto APIs may prioritize raw market data, on-chain metrics, or analytics dashboards. Combining DeepSeek-style search with specialized APIs (for price, on-chain metrics, or signals) yields richer tooling for research workflows.
Explore provider docs and example use cases. For integrated AI research and ratings, see Token Metrics which demonstrates how semantic retrieval can be paired with model-driven analysis for structured insights.
This article is for informational and technical education only. It does not constitute investment advice, endorsements, or recommendations. Evaluate tools and data sources critically and consider legal and compliance requirements before deployment.


9450 SW Gemini Dr
PMB 59348
Beaverton, Oregon 97008-7105 US
.svg)




.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.















































%20Price%20Prediction%202025%2C%202030%20-%20Forecast%20Analysis.png)

















.png)

%20Price%20Prediction%20.webp)









%20Price%20Prediction.webp)



%20Price%20Prediction%20Analysis%20-%20Can%20it%20Reach%20%24500%20in%20Future_.png)
















