


















.png)
.png)
.png)

.png)
.png)

















.png)























.png)
.png)








.png)



.png)
%201%20(1).png)

.png)


.png)






.png)
.png)



.png)

















.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)




























































































.png)








.png)

.png)
.png)









.png)


.png)











Research
Top Crypto Trading Platforms in 2025
When it comes to crypto trading platforms, Token Metrics is not an exchange, but a crypto analytics and crypto trading intelligence platform powered by AI.
Token Metrics Team
10




%201.svg)
%201.svg)
Big news: We’re cranking up the heat on AI-driven crypto analytics with the launch of the Token Metrics API and our official SDK (Software Development Kit). This isn’t just an upgrade – it's a quantum leap, giving traders, hedge funds, developers, and institutions direct access to cutting-edge market intelligence, trading signals, and predictive analytics.
Crypto markets move fast, and having real-time, AI-powered insights can be the difference between catching the next big trend or getting left behind. Until now, traders and quants have been wrestling with scattered data, delayed reporting, and a lack of truly predictive analytics. Not anymore.
The Token Metrics API delivers 32+ high-performance endpoints packed with powerful AI-driven insights right into your lap, including:
Getting started with the Token Metrics API is simple:
At Token Metrics, we believe data should be decentralized, predictive, and actionable.
The Token Metrics API & SDK bring next-gen AI-powered crypto intelligence to anyone looking to trade smarter, build better, and stay ahead of the curve. With our official SDK, developers can plug these insights into their own trading bots, dashboards, and research tools – no need to reinvent the wheel.
The dream of passive income drives millions toward cryptocurrency—earning money while you sleep, building wealth automatically, achieving financial freedom without constant work. Yet most crypto "passive income" strategies require active management, constant monitoring, technical expertise, and significant time investment. They're anything but passive.
Token Metrics AI Indices deliver genuine passive income through systematic wealth accumulation requiring minimal ongoing effort. Once established, your crypto portfolio grows automatically through professional AI management, strategic rebalancing, and compound returns—all without your daily involvement or active trading.
This comprehensive guide explores how crypto indices create true passive income, compares index investing to other passive income strategies, reveals the mathematics of automated wealth compounding, and provides actionable frameworks for building substantial passive income streams through disciplined index allocation.
Understanding genuine passive income requires distinguishing it from "active income disguised as passive" that dominates crypto discussions.
Many crypto strategies marketed as "passive income" require substantial ongoing effort:
These strategies generate income but demand active participation—they're jobs, not passive income streams.
True passive income exhibits specific characteristics:
Token Metrics indices meet all these criteria—once established, your wealth grows automatically through AI-powered management while you focus on other priorities.
Understanding the mechanisms generating passive returns through indices reveals why this approach delivers superior risk-adjusted income compared to alternatives.
The primary income source from crypto indices is capital appreciation—portfolio value increasing over time as cryptocurrency markets grow and AI optimization captures opportunities.
Unlike stocks requiring decades to double, crypto indices can deliver 50-200% annual returns during favorable market cycles. A $25,000 initial investment growing at 60% annually becomes $100,000 in three years and $400,000 in six years—substantial wealth creation requiring zero active trading.
This appreciation occurs passively through:
You make no trading decisions. You don't research tokens. You don't time markets. The system handles everything while appreciation compounds automatically.
Passive income's true power emerges through compounding—returns generating additional returns in self-reinforcing cycles. Token Metrics indices amplify compounding through systematic profit capture and reinvestment.
When indices rebalance, profits from appreciating tokens are automatically reinvested into new opportunities. This mechanical reinvestment ensures all gains compound rather than sitting idle. Over years and decades, compounding creates extraordinary wealth accumulation.
Example: $10,000 growing at 40% annually with full reinvestment becomes $150,000 in seven years. Without reinvestment—if you withdrew gains annually—the same investment reaches only $38,000. Compounding creates an additional $112,000 in wealth automatically.
Adding regular contributions to index positions creates powerful dollar-cost averaging benefits that enhance passive returns. By investing fixed amounts regardless of market conditions, you automatically buy more tokens when prices are low and fewer when prices are high.
This systematic averaging removes timing pressure—you don't need to identify perfect entry points. Whether markets surge or crash, your regular contributions continue mechanically, building positions that appreciate over complete market cycles.
Combined with compound growth, dollar-cost averaging creates remarkable long-term wealth accumulation requiring minimal effort beyond initial automated contribution setup.
Token Metrics indices can be held in tax-advantaged retirement accounts where appreciation compounds tax-free (Roth IRA) or tax-deferred (Traditional IRA). This tax optimization dramatically accelerates wealth accumulation compared to taxable accounts.
In taxable accounts, annual rebalancing triggers capital gains taxes that reduce compounding power. In retirement accounts, all gains compound without tax drag—a significant passive income enhancement requiring only initial account setup.
Understanding how index-based passive income compares to other strategies reveals relative advantages.
Vs. Staking/Yield Farming: While staking offers 5-20% APY, it involves token price risk (10% yield means nothing if price drops 50%), lock-up periods preventing selling during crashes, impermanent loss, protocol risks, and constant management overhead. Index capital appreciation typically exceeds staking yields by 40+ percentage points while maintaining complete liquidity.
Vs. Real Estate: Real estate requires $50,000-$500,000+ minimums, involves management burdens despite property managers, suffers from illiquidity (months to sell), concentrates wealth geographically, and carries leverage risks. Indices require minimal capital, zero management, complete liquidity, global diversification, and no leverage risks.
Vs. Dividend Stocks: Dividend yields of 2-4% and appreciation of 6-8% annually pale against crypto potential. Dividends trigger immediate taxation reducing after-tax returns. Crypto indices offer dramatically higher return potential with tax-efficient compounding.
Vs. Bitcoin/Ethereum Only: Concentrated two-asset holdings sacrifice diversification, miss altcoin opportunities, lack rebalancing benefits, and forego professional management. Indices provide superior risk-adjusted returns with equal passivity.
Understanding how small initial investments and regular contributions compound into substantial wealth over time makes passive income potential concrete rather than abstract.
You don't need large capital to begin building meaningful passive income. Small amounts invested consistently compound into substantial wealth through time and returns.
Scenario 1: Modest Beginning
This scenario transforms $31,000 in total contributions into nearly half a million through compound growth—passive income requiring only initial setup and automated monthly contributions.
Scenario 2: Aggressive Accumulation
Nearly $1 million from $65,000 in contributions—extraordinary passive wealth creation through systematic index investing.
Real returns vary annually—bull markets deliver 100-300% returns while bear markets create 50-80% drawdowns. However, averaging across complete cycles, conservative crypto indices historically achieve 30-60% annualized returns.
These projections assume no income from your job increases, which is unrealistic. As your career progresses and income grows, contribution amounts can increase proportionally, accelerating wealth accumulation further.
Once accumulated, substantial crypto index holdings generate retirement income through systematic withdrawal strategies.
If you accumulate $2 million in crypto indices by age 60, withdrawing 4% annually provides $80,000 passive income while preserving principal. If crypto continues appreciating even modestly at 15% annually, your portfolio grows despite withdrawals, providing inflation-protected lifetime income.
This passive income stream requires no active work—automated monthly withdrawals provide cash flow while remaining capital compounds through continued AI management.
Creating effective passive income through crypto indices requires systematic implementation across several phases.
Phase 1: Foundation Setup (Month 1)
Complete this foundation work once—all subsequent wealth building occurs automatically.
Phase 2: Automation Implementation (Month 2)
After automation setup, your system operates independently requiring minimal intervention.
Phase 3: Optimization and Scaling (Months 3-12)
Even during optimization phase, time commitment remains minimal—1-2 hours monthly maximum.
Phase 4: Wealth Preservation and Distribution (Years 10+)
Throughout all phases, your involvement remains minimal while wealth compounds automatically through professional AI management.
Optimizing passive income requires strategic decisions about allocation, risk management, and contribution timing.
Allocation Balance: Higher returns come with higher volatility. Conservative approach uses 70% conservative/20% balanced/10% aggressive indices. Moderate uses 50/30/20 split. Aggressive uses 30/30/40 split. All remain completely passive from management perspective.
Contribution Timing: Maintain regular automated contributions always, but keep 10-20% dry powder in stablecoins for crisis deployment during 30%+ market crashes. These fear-driven purchases generate outsized returns.
Tax Location Optimization: Roth IRA provides tax-free growth ideal for aggressive indices. Traditional IRA offers tax-deferred growth suitable for conservative indices. Taxable accounts provide flexibility but trigger annual rebalancing taxes. This optimization happens once but compounds into substantial savings over decades.
Even with automated systems, investors make predictable mistakes that undermine passive income goals.
True passive income through crypto indices isn't mythical—it's mathematically achievable through systematic implementation and patient execution. Token Metrics provides the professional AI management, diversification, and optimization infrastructure transforming crypto from speculation into genuine passive wealth building.
The beauty of this approach is simplicity: establish system once, contribute consistently, trust professional management, and let compound growth work its magic over years and decades. No day trading. No constant monitoring. No technical expertise required. Just disciplined, automated wealth accumulation.
Your action determines outcomes. Those who begin today, implement systematic contributions, and maintain discipline through market cycles build substantial passive income streams funding financial independence. Those who delay, overthink, or abandon strategy during volatility watch opportunities pass without capturing benefits.
Token Metrics indices eliminate complexity and emotion from crypto investing, leaving only systematic wealth accumulation. The technology works. The mathematics favor consistent long-term investors. The only question is whether you'll begin building your passive income system today or postpone financial freedom indefinitely.
Start your 7-day free trial and take the first step toward true passive income through automated, professional crypto index investing. Your future self will thank you for the decision you make today.
When evaluating cryptocurrency index providers, most investors focus on past performance, fees, or token selection. While these factors matter, they miss the fundamental differentiator determining long-term success: the sophistication of artificial intelligence powering portfolio management.
Token Metrics doesn't just use AI as marketing buzzword—the platform employs cutting-edge machine learning systems that fundamentally outperform human decision-making in ways that compound into extraordinary advantages over time. Understanding why AI-driven indices surpass both traditional approaches and human-managed alternatives reveals why this technology represents the future of crypto investing.
This comprehensive guide explores the specific AI technologies powering Token Metrics indices, examines what these systems can do that humans cannot, compares AI-driven approaches to traditional alternatives, and reveals how technological advantages translate into superior investment outcomes.
Before understanding AI's advantages, recognize the inherent limitations of human portfolio management in cryptocurrency markets.
The human brain processes information sequentially and slowly. A skilled analyst might evaluate 10-20 cryptocurrencies daily using 5-10 data points each. This yields 50-200 data points daily—a tiny fraction of available information.
Token Metrics' AI analyzes 6,000+ cryptocurrencies using 80+ data points each—480,000+ data points daily. This 2,400x information processing advantage means the AI identifies opportunities and risks invisible to human analysis.
Human decision-making suffers from systematic cognitive biases:
These biases cause systematic errors leading to poor timing, holding losers too long, selling winners prematurely, and following crowds into overvalued assets. AI systems have no cognitive biases—they evaluate data objectively based on mathematical relationships.
Human portfolio managers experience fear during market crashes and euphoria during rallies. These emotions trigger fight-or-flight responses overwhelming rational analysis, causing panic selling at bottoms and overconfident buying at tops.
AI experiences no emotions. Market crashes don't trigger fear. Rallies don't create euphoria. The system evaluates probabilities and executes strategies mechanically regardless of market sentiment.
Humans require sleep, breaks, vacations, and time for other life activities. Portfolio managers cannot monitor markets 24/7 or maintain consistent attention over years without degradation.
AI operates continuously without fatigue, monitoring global markets across time zones simultaneously. The system never sleeps, never takes vacations, never loses focus—maintaining perpetual vigilance impossible for humans.
Human learning occurs slowly through experience and study. A portfolio manager might learn from hundreds of trades over decades, building intuition from limited personal experience.
AI learns from millions of data points across thousands of assets simultaneously. Every market movement, every token launch, every sentiment shift contributes to model training. The system identifies patterns across entire crypto history that individual humans could never detect.
Token Metrics employs an ensemble of sophisticated machine learning models, each serving specific purposes within the investment process.
These models excel at identifying complex, non-linear relationships between variables. In crypto markets, simple linear relationships rarely exist—token performance depends on intricate interactions between multiple factors.
Gradient boosting builds thousands of decision trees, each learning from previous trees' errors. This iterative process creates highly accurate predictions by combining many weak predictors into strong aggregate models.
Application: Identifying which combinations of technical, fundamental, and sentiment factors predict future price movements most accurately.
RNNs specialize in time-series analysis, recognizing patterns in sequential data. Cryptocurrency prices represent time-series data where past patterns influence future movements.
Unlike simple technical analysis looking at individual indicators, RNNs identify complex temporal relationships spanning multiple timeframes simultaneously. The networks detect subtle patterns in how prices, volumes, and other metrics evolve together over time.
Application: Forecasting price trajectories by learning from historical patterns while adapting to changing market dynamics.
Random forest algorithms create multiple decision trees using random subsets of data and features, then aggregate their predictions. This approach reduces overfitting risk—where models perform excellently on historical data but fail on new data.
By training on different data subsets, random forests identify robust patterns that generalize well rather than memorizing specific historical sequences unlikely to repeat exactly.
Application: Robust token classification separating quality projects from low-quality alternatives based on generalizable characteristics.
NLP algorithms analyze text data from social media, news articles, developer communications, and community forums. These systems extract sentiment, identify trending topics, detect narrative shifts, and quantify community engagement.
Unlike humans who might read dozens of articles weekly, NLP processes millions of text sources daily, identifying sentiment patterns and narrative changes before they become obvious.
Application: Gauging market sentiment, detecting emerging narratives, identifying coordinated pumps or manipulative campaigns, and assessing community health.
Anomaly detection identifies unusual patterns suggesting either opportunities or risks. These systems establish baseline "normal" behavior, then flag deviations warranting attention.
In crypto markets, anomalies might indicate insider trading before announcements, coordinated manipulation schemes, security vulnerabilities, or emerging trends before mainstream recognition.
Application: Early warning systems for security threats, manipulation detection, and identifying breakout candidates showing unusual strength relative to historical patterns.
Understanding specific capabilities unique to AI reveals why technology-driven approaches surpass traditional methods.
Human portfolio managers analyze assets sequentially—evaluating Bitcoin, then Ethereum, then Solana, one at a time. This sequential processing misses relationships between assets.
AI analyzes all assets simultaneously, identifying correlations, relative strength patterns, sector rotations, and cross-asset opportunities. The system recognizes when DeFi tokens strengthen relative to Layer-1s, when memecoins show coordinated movement, or when specific sectors lead or lag broader markets.
This simultaneous analysis reveals relative value opportunities invisible to sequential human analysis.
Humans excel at recognizing simple patterns—support and resistance levels, head-and-shoulders formations, moving average crossovers. However, complex multi-dimensional patterns exceed human cognitive capacity.
AI identifies patterns involving dozens of variables simultaneously across thousands of assets. These patterns might involve specific combinations of technical indicators, on-chain metrics, sentiment scores, and fundamental factors that human analysts could never process holistically.
Example: The AI might recognize that tokens with specific combinations of technical momentum, developer activity growth, and social sentiment shifts outperform 73% of the time over subsequent 30 days. Humans cannot track and validate such complex multi-factor patterns.
The most valuable investment opportunities occur during market extremes when fear or greed overwhelm rational analysis. Humans struggle maintaining discipline during these periods—buying during maximum fear feels terrifying, selling during euphoria seems foolish.
AI executes mechanically based on statistical probabilities regardless of market sentiment. When indicators show extreme fear and historically attractive valuations, the system buys aggressively. When indicators show extreme euphoria and overvaluation, the system takes profits systematically.
This emotionless execution during extremes generates substantial alpha that humans rarely capture despite understanding the principle intellectually.
Human learning occurs slowly. Portfolio managers develop strategies based on historical experience, but adapting to new market regimes takes time and often requires painful losses first.
AI learns continuously from every market movement. When strategies underperform, the system adjusts weightings automatically. When new patterns emerge, the AI incorporates them immediately. This perpetual learning ensures strategies evolve with markets rather than becoming obsolete.
Markets move in milliseconds. By the time humans notice significant price movements and decide how to respond, opportunities have passed.
AI monitors markets continuously and responds within microseconds. When rebalancing signals trigger or new opportunities emerge, execution occurs immediately rather than after human deliberation delays.
This speed advantage proves especially valuable during volatile periods when opportunities appear and disappear rapidly.
Understanding Token Metrics' AI advantages becomes clearer through direct comparison with traditional approaches.
Vs. Market-Cap-Weighted Indices: Traditional indices simply track largest cryptocurrencies by size, overexposing to overvalued bubbles and missing emerging opportunities. Token Metrics' AI evaluates fundamentals, momentum, and valuations, overweighting undervalued opportunities regardless of size.
Vs. Human-Managed Crypto Funds: Traditional funds employ analyst teams covering 50-100 tokens maximum, influenced by cognitive biases, charging 2% management and 20% performance fees. Token Metrics covers 6,000+ tokens without biases or emotions at subscription fees far lower than traditional management costs.
Vs. DIY Individual Selection: Individual investors face time constraints, limited professional tools, emotional attachment preventing objectivity, and FOMO-driven poor timing. AI provides comprehensive analysis using professional data, objective evaluation, and systematic timing based on probabilities.
Understanding theoretical AI advantages is useful, but what matters most is how these translate into actual superior investment performance.
AI identifies emerging opportunities before they become obvious to human investors. By analyzing on-chain activity, developer engagement, and early sentiment shifts, the system detects promising tokens months before mainstream attention arrives.
Result: Index positions established at significantly lower prices capture maximum appreciation when opportunities materialize.
AI's anomaly detection and comprehensive analysis identify risks earlier than human analysis. Security vulnerabilities, team problems, tokenomics issues, or manipulation schemes trigger early warning systems.
Result: Positions reduced or eliminated before major problems cause catastrophic losses, preserving capital for better opportunities.
The system identifies optimal rebalancing timing based on technical signals, sentiment extremes, and volatility patterns. Rather than rebalancing on arbitrary schedules, the AI rebalances when conditions offer maximum advantage.
Result: Systematic "buy low, sell high" execution that human emotion prevents, generating additional alpha through superior timing.
AI constructs portfolios maximizing diversification benefits through correlation analysis across all tokens. Rather than naive diversification holding many similar assets, the system combines tokens with complementary characteristics.
Result: Smoother return profiles with superior risk-adjusted performance through true diversification rather than false variety.
Every market cycle improves AI performance through additional training data. Each bull market, bear market, and consolidation phase provides data points refining model accuracy.
Result: Performance improving over time rather than degrading as with human strategies that become obsolete when markets evolve.
AI technology continues advancing rapidly, suggesting Token Metrics' advantages will expand over time:
Understanding AI advantages has direct practical implications:
Artificial intelligence represents the future of cryptocurrency portfolio management not because it's trendy—because it's fundamentally superior. The information processing, pattern recognition, emotionless execution, and continuous learning capabilities of modern AI exceed human limitations by orders of magnitude.
Token Metrics doesn't just use AI as marketing—the platform employs institutional-grade machine learning providing genuine competitive advantages translating into measurably superior risk-adjusted returns.
The choice facing crypto investors is straightforward: compete against sophisticated AI systems using human limitations, or harness those same AI capabilities through Token Metrics indices. One approach fights the future; the other embraces it.
As AI technology continues advancing and more capital recognizes these advantages, the performance gap between AI-driven and traditional approaches will widen. Early adopters of superior technology capture outsized returns, while late adopters play catch-up from positions of disadvantage.
Your opportunity exists today. Token Metrics provides access to institutional-grade AI previously available only to hedge funds and professional investors. The democratization of artificial intelligence through accessible indices transforms crypto investing from speculation into systematic wealth building.
Begin your 7-day free trial and experience firsthand how artificial intelligence transforms cryptocurrency investing from emotional gambling into disciplined, technology-driven wealth creation.
The Layer 1 landscape is consolidating as users and developers gravitate to chains with clear specialization. Bitcoin Cash positions itself as a payment-focused chain with low fees and quick settlement for everyday usage.
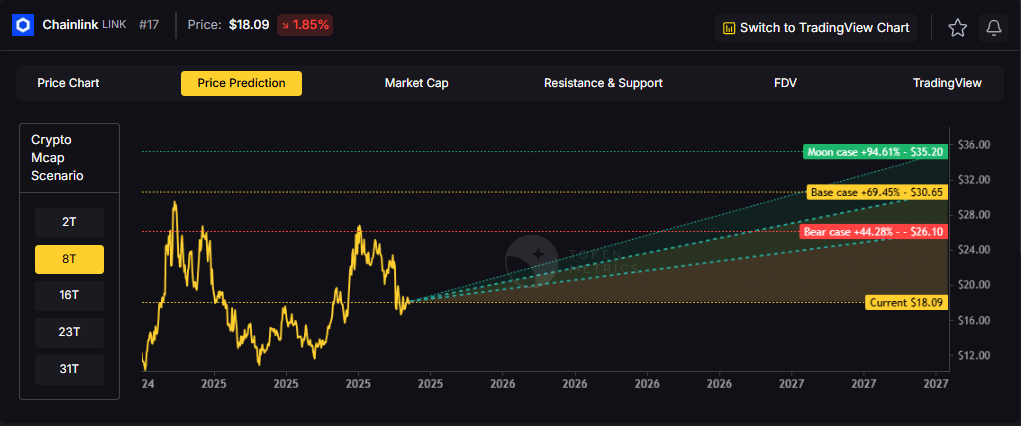
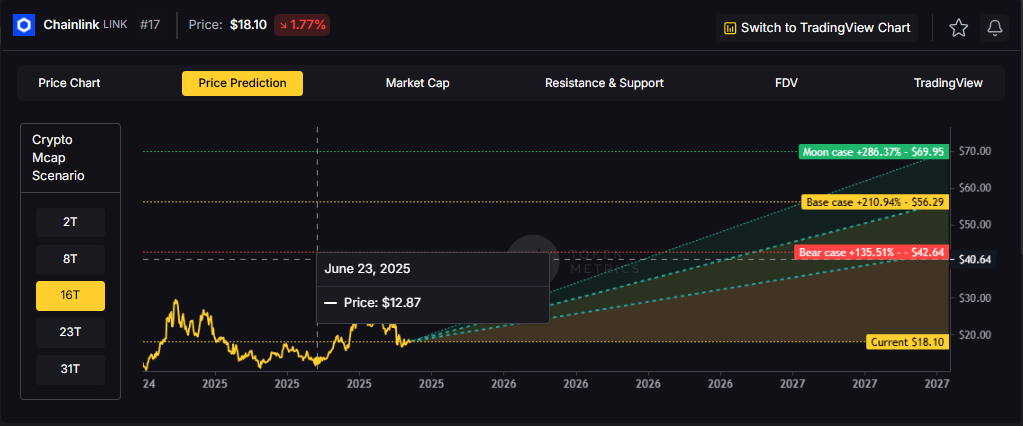
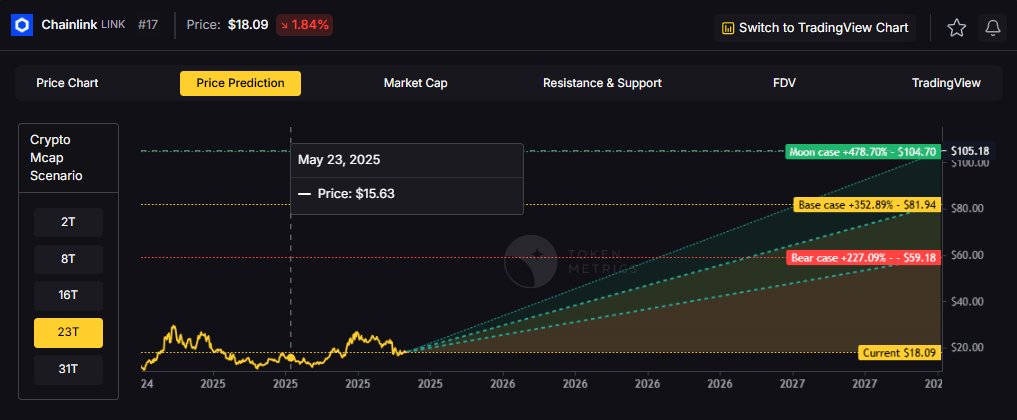
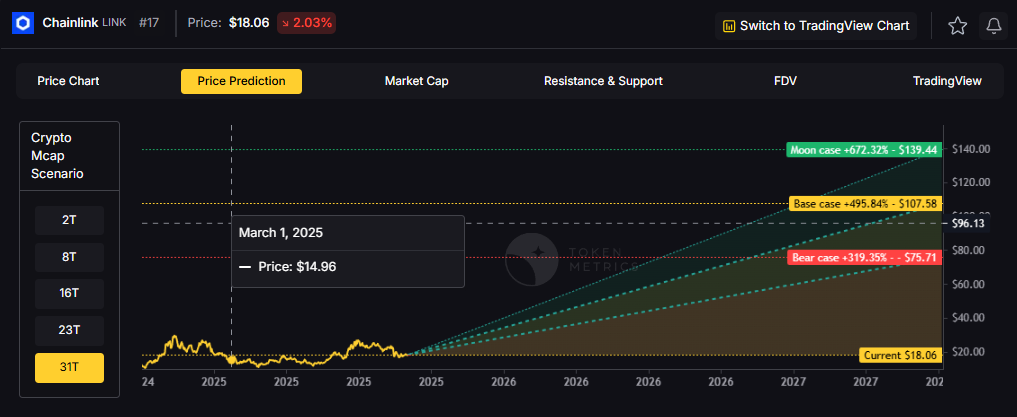
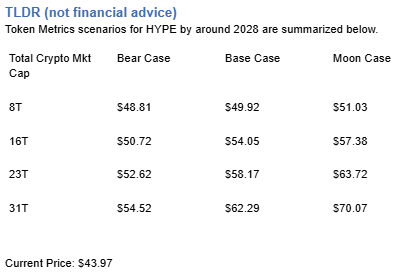
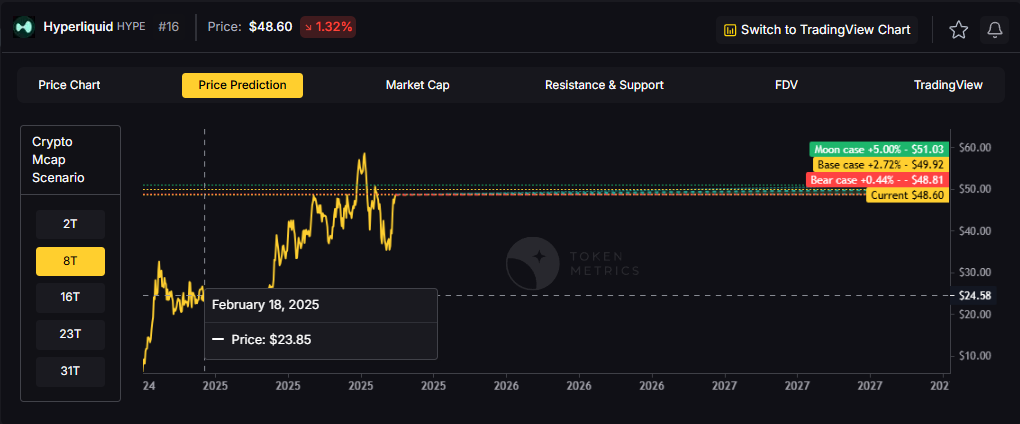
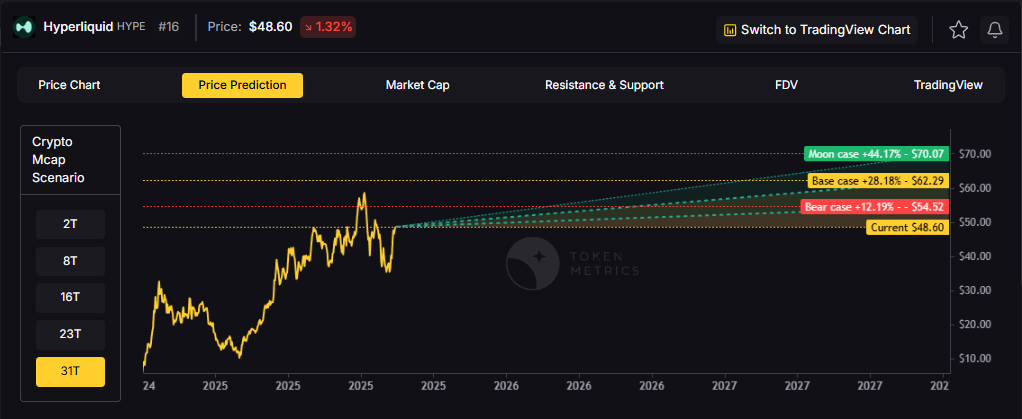
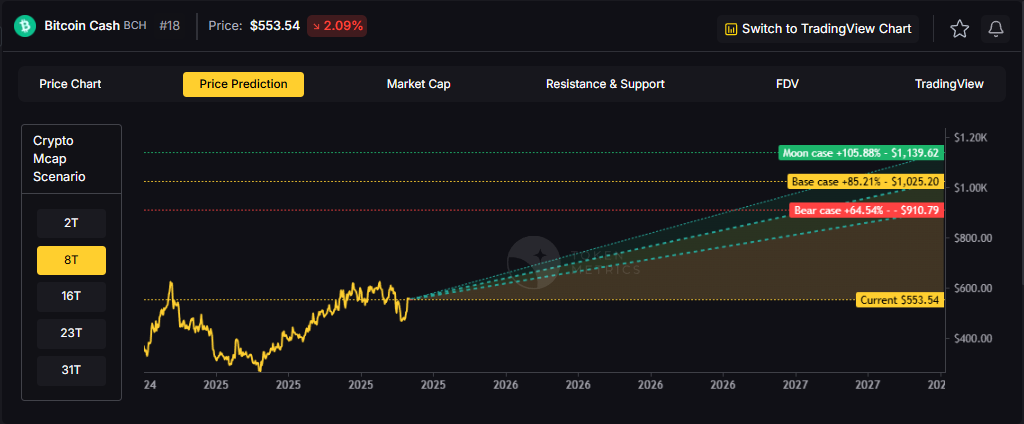
The scenario projections below map potential outcomes for BCH across different total crypto market sizes. Base cases assume steady usage and listings, while moon scenarios factor in stronger liquidity and accelerated adoption.

Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
How to read it: Each band blends cycle analogues and market-cap share math with TA guardrails. Base assumes steady adoption and neutral or positive macro. Moon layers in a liquidity boom. Bear assumes muted flows and tighter liquidity.
TM Agent baseline:
Token Metrics lead metric for Bitcoin Cash, cashtag $BCH, is a TM Grade of 54.81%, which translates to Neutral, and the trading signal is bearish, indicating short-term downward momentum. This implies Token Metrics views $BCH as mixed value long term: fundamentals look strong, while valuation and technology scores are weak, so upside depends on improvements in adoption or technical development. Market context: Bitcoin has been setting market direction, and with broader risk-off moves altcoins face pressure, which increases downside risk for $BCH in the near term.
Live details:
Affiliate Disclosure: We may earn a commission from qualifying purchases made via this link, at no extra cost to you.
Token Metrics scenarios span four market cap tiers, each representing different levels of crypto market maturity and liquidity:


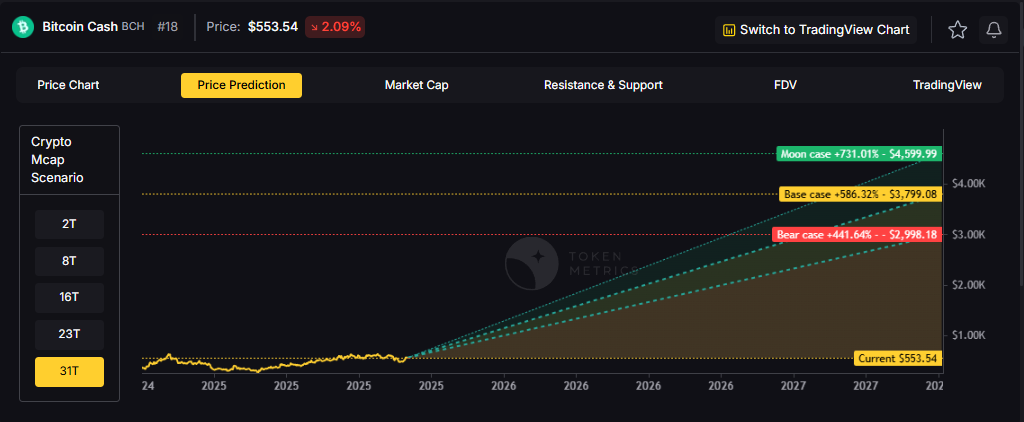
Each tier assumes progressively stronger market conditions, with the base case reflecting steady growth and the moon case requiring sustained bull market dynamics.
Bitcoin Cash represents one opportunity among hundreds in crypto markets. Token Metrics Indices bundle BCH with top one hundred assets for systematic exposure to the strongest projects. Single tokens face idiosyncratic risks that diversified baskets mitigate.
Historical index performance demonstrates the value of systematic diversification versus concentrated positions.
Bitcoin Cash is a peer-to-peer electronic cash network focused on fast confirmation and low fees. It launched in 2017 as a hard fork of Bitcoin with larger block capacity to prioritize payments. The chain secures value transfers using proof of work and aims to keep everyday transactions affordable.
BCH is used to pay transaction fees and settle transfers, and it is widely listed across major exchanges. Adoption centers on payments, micropayments, and remittances where low fees matter. It competes as a payment‑focused Layer 1 within the broader crypto market.
Token Metrics AI provides comprehensive context on Bitcoin Cash's positioning and challenges.
Vision:
Bitcoin Cash (BCH) is a cryptocurrency that emerged from a 2017 hard fork of Bitcoin, aiming to function as a peer-to-peer electronic cash system with faster transactions and lower fees. It is known for prioritizing on-chain scalability by increasing block sizes, allowing more transactions per block compared to Bitcoin. This design choice supports its use in everyday payments, appealing to users seeking a digital cash alternative. Adoption has been driven by its utility in micropayments and remittances, particularly in regions with limited banking infrastructure. However, Bitcoin Cash faces challenges including lower network security due to reduced mining hash rate compared to Bitcoin, and ongoing competition from both Bitcoin and other scalable blockchains. Its value proposition centers on accessibility and transaction efficiency, but it operates in a crowded space with evolving technological and regulatory risks.
Problem:
The project addresses scalability limitations in Bitcoin, where rising transaction fees and slow confirmation times hinder its use for small, frequent payments. As Bitcoin evolved into a store of value, a gap emerged for a blockchain-based currency optimized for fast, low-cost transactions accessible to the general public.
Solution:
Bitcoin Cash increases block size limits from 1 MB to 32 MB, enabling more transactions per block and reducing congestion. This on-chain scaling approach allows for faster confirmations and lower fees, making microtransactions feasible. The network supports basic smart contract functionality and replay protection, maintaining compatibility with Bitcoin's core architecture while prioritizing payment utility.
Market Analysis:
Bitcoin Cash operates in the digital currency segment, competing with Bitcoin, Litecoin, and stablecoins for use in payments and remittances. While not the market leader, it occupies a niche focused on on-chain scalability for transactional use. Its adoption is influenced by merchant acceptance, exchange liquidity, and narratives around digital cash. Key risks include competition from layer-2 solutions on other blockchains, regulatory scrutiny of cryptocurrencies, and lower developer and miner activity compared to larger networks. Price movements are often tied to broader crypto market trends and internal protocol developments. Despite its established presence, long-term growth depends on sustained utility, network security, and differentiation in a market increasingly dominated by high-throughput smart contract platforms.
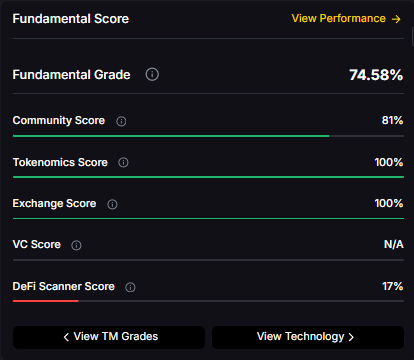
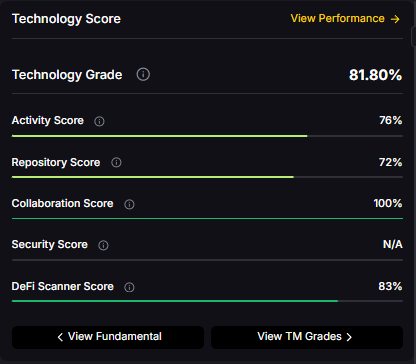
Fundamental Grade: 80.41% (Community 62%, Tokenomics 100%, Exchange 100%, VC —, DeFi Scanner 72%).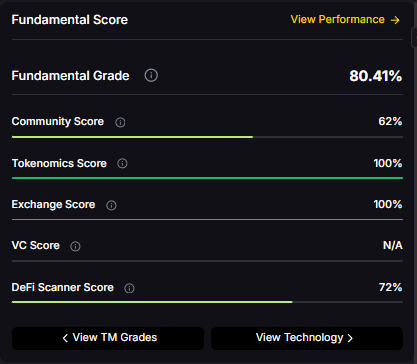
Technology Grade: 29.63% (Activity 22%, Repository 70%, Collaboration 48%, Security —, DeFi Scanner 72%).
Can BCH reach $3,000?
Based on the scenarios, BCH could reach $3,000 in the 23T moon case and 31T base case. The 23T tier projects $3,446.53 in the moon case. Not financial advice.
Can BCH 10x from current levels?
At current price of $553.54, a 10x would reach $5,535.40. This falls within the 31T base and moon cases. Bear in mind that 10x returns require substantial market cap expansion. Not financial advice.
Should I buy BCH now or wait?
Timing depends on your risk tolerance and macro outlook. Current price of $553.54 sits below the 8T bear case in our scenarios. Dollar-cost averaging may reduce timing risk. Not financial advice.
Want exposure? Buy BCH on MEXC
Disclosure
Educational purposes only, not financial advice. Crypto is volatile, do your own research and manage risk.
.svg)




.png)
Token Metrics Media LLC is a regular publication of information, analysis, and commentary focused especially on blockchain technology and business, cryptocurrency, blockchain-based tokens, market trends, and trading strategies.
Token Metrics Media LLC does not provide individually tailored investment advice and does not take a subscriber’s or anyone’s personal circumstances into consideration when discussing investments; nor is Token Metrics Advisers LLC registered as an investment adviser or broker-dealer in any jurisdiction.
Information contained herein is not an offer or solicitation to buy, hold, or sell any security. The Token Metrics team has advised and invested in many blockchain companies. A complete list of their advisory roles and current holdings can be viewed here: https://tokenmetrics.com/disclosures.html/
Token Metrics Media LLC relies on information from various sources believed to be reliable, including clients and third parties, but cannot guarantee the accuracy and completeness of that information. Additionally, Token Metrics Media LLC does not provide tax advice, and investors are encouraged to consult with their personal tax advisors.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Ratings and price predictions are provided for informational and illustrative purposes, and may not reflect actual future performance.















































%20Price%20Prediction%202025%2C%202030%20-%20Forecast%20Analysis.png)

















.png)

%20Price%20Prediction%20.webp)









%20Price%20Prediction.webp)



%20Price%20Prediction%20Analysis%20-%20Can%20it%20Reach%20%24500%20in%20Future_.png)


















